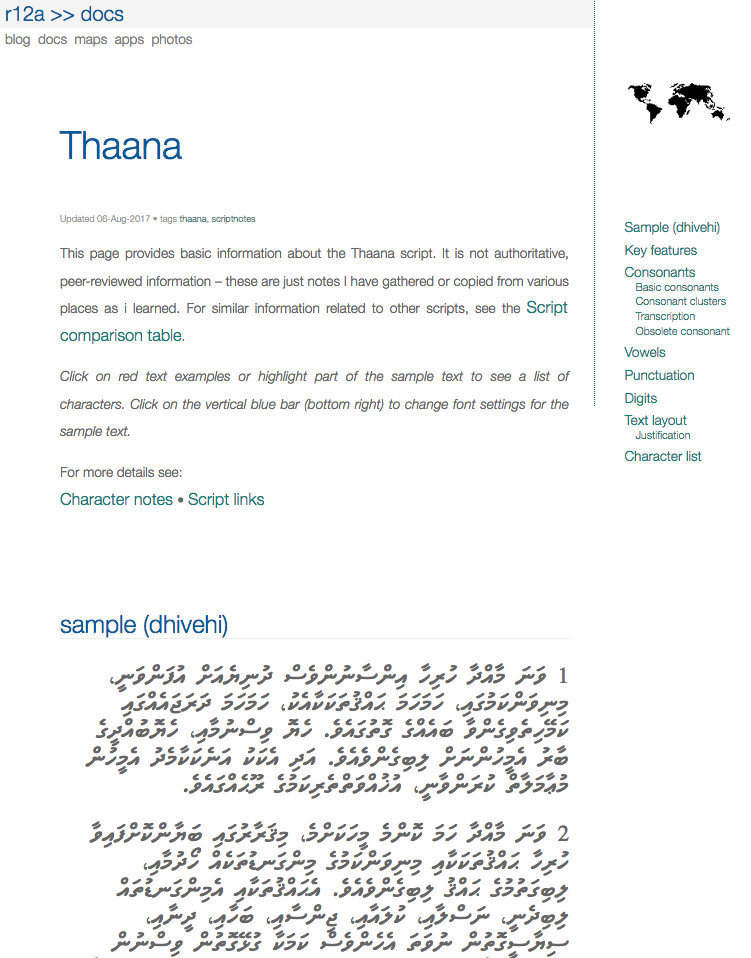
I've often heard from people that there needs to be a way to represent linguistic interlinear glossed text in HTML (with CSS).
(To my mind, the term 'interlinear gloss' isn't especially helpful in describing the particular use case I have in mind. Rather than inline annotations, where a word or two appears above or below the main text of a document in the interline space, here I'm talking about table-like, multi-line text containing aligned items, as in the example below. This arrangement is common for linguistic analyses of text.)
I also often hear the suggestion that an extension to ruby markup is needed to allow for this. I disagree. I also often hear that we need some new HTML markup for this. I don't think so.
I suspect that the following approach may tick all the necessary boxes, without any additions to anything. This example is quite simple, but it can easily be extended to include more lines and more interesting styling options. Note also that the text wraps according to the width of the window.
When ʾIsayəyyas heard this statement from the mouth of the servants of Satan, he went to the king and said to the king ...
The code
The markup uses divs and spans, which are then styled using CSS flexbox properties.
<div class="multilineGlossedText">
<div class="stack"><span class="legend">Ge'ez:</span><span class="legend">Pronunciation:</span><span class="legend">Gloss:</span></div>
<div class="stack"><span class="base" lang="gez">ወሶበ፡</span><span class="trans">wä-sobä</span><span class="gloss">and-when</span></div>
<div class="stack"><span class="base" lang="gez">ሰማዐ፡</span><span class="trans">sämʾä</span><span class="gloss">heard.he</span></div>
<div class="stack"><span class="base" lang="gez">ኢሳይያሰ፡</span><span class="trans">ʾIsayəyyas</span><span class="gloss">ʾIsayəyyas</span></div>
...
<div class="stack"><span class="base" lang="gez">ለንጉሥ፡ ...</span><span class="trans">lä-nəguś ...</span><span class="gloss">to-king ...</span></div>
</div>
This is the CSS code.
.multilineGlossedText {
display: flex;
flex-direction: row;
flex-wrap: wrap;
}
.stack {
display: flex;
flex-direction: column;
flex-wrap: nowrap;
margin-right: .75em;
margin-top: .5em;
}
.legend { font-style: italic; }
RTL text example
This example annotates text that is written right-to-left. It shows transcriptions written RTL and LTR, but without actually needing to reverse the string in the source. There's a lot more styling going on for the different types of data. It also applies small caps to a morphological identifier. In the original, the Arabic and reversed transcription were separate from the rest of the annotations, but here I bring them all together.
The teacher lost his donkey. He was both searching for it and was expressing his thanks. They asked the cause of being grateful.
I created a GitHub issue for further discussion of this idea.





 at the top right of the page.
at the top right of the page.