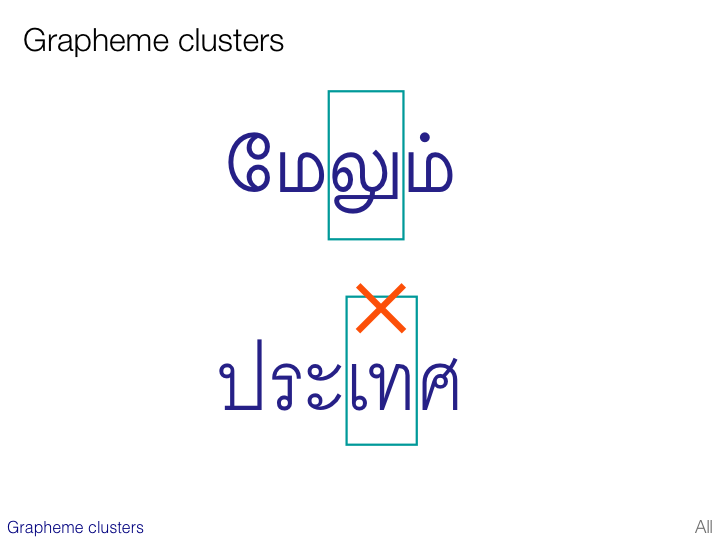
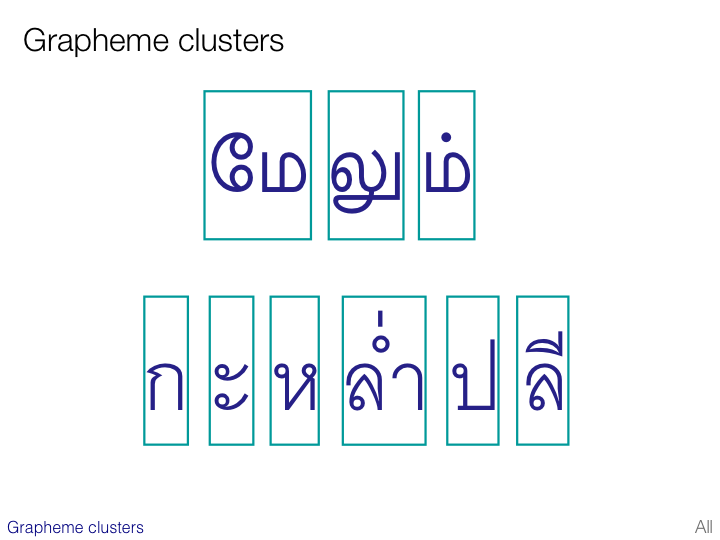
To facilitate the process of string comparison for operations such as searching, sorting and comparison it is helpful to adopt a standard
policy with regard to precomposed versus decomposed variants of a character sequence, and the order in which multiple combining characters appear.
This can be achieved by applying an appropriate normalization form. The Unicode Standard provides a normalization form
called NFD that represents all character sequences in maximally decomposed form. In addition to decomposition, NFD applies a standard order to
multiple composing characters attached to a base character. As an alternative, the Unicode Standard offers NFC. NFC is achieved by applying NFD to
the text, then re-composing characters for which precomposed forms exist in version 3.0 of the standard.
Note that there are actually some precomposed forms in the Unicode character set that are not generated by NFC, for reasons we
will not go into here. In addition, where there is no precomposed form, a character sequence is left decomposed, but canonical ordering is still
applied to all combining characters.
The Unicode Standard also offers two more normalization forms, NFKD and NFKC, where K stands for ‘kompatibility’. These forms are provided
because the Unicode character set includes many characters merely to provide round-trip compatibility with other character sets. Such characters
represent such things as glyph variants, shaped forms, alternative compositions, and so on, but can be represented by other ‘canonical’ versions of
the character or characters already in Unicode. Ideally, such compatibility variants should not be used. The NFKD and NFKC normalization forms
replace them with more appropriate characters or character sequences. (This, of course, can cause a problem if you intend to convert data back into
its original encoding, because you lose the original information.)
go to top of page