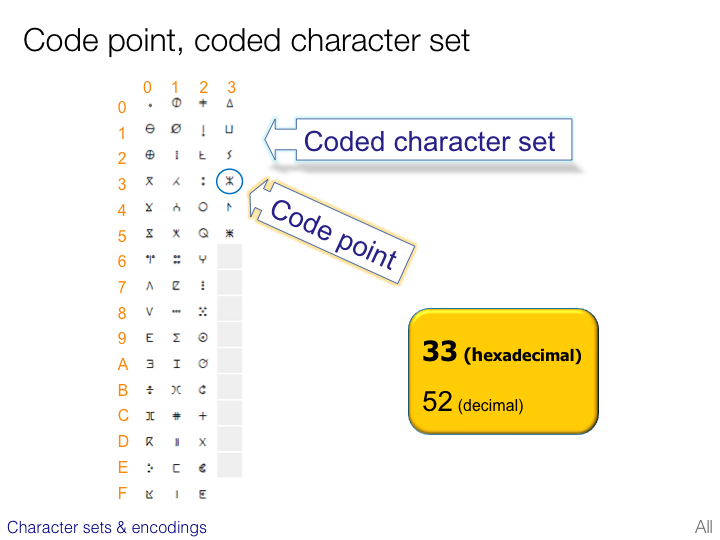
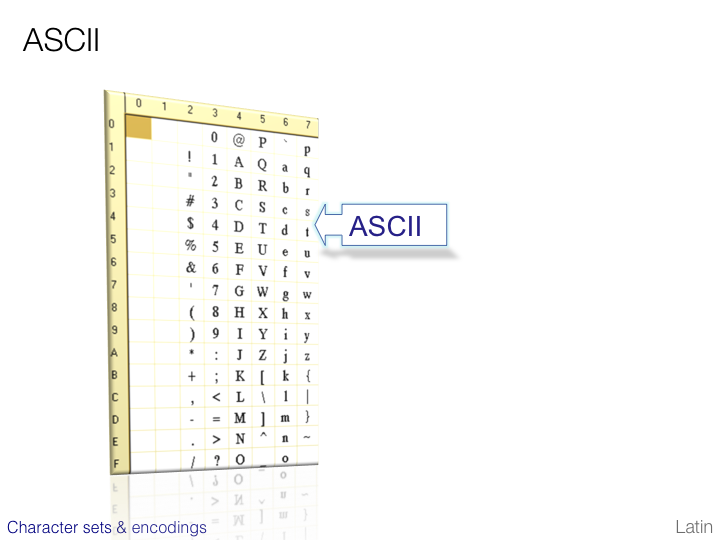
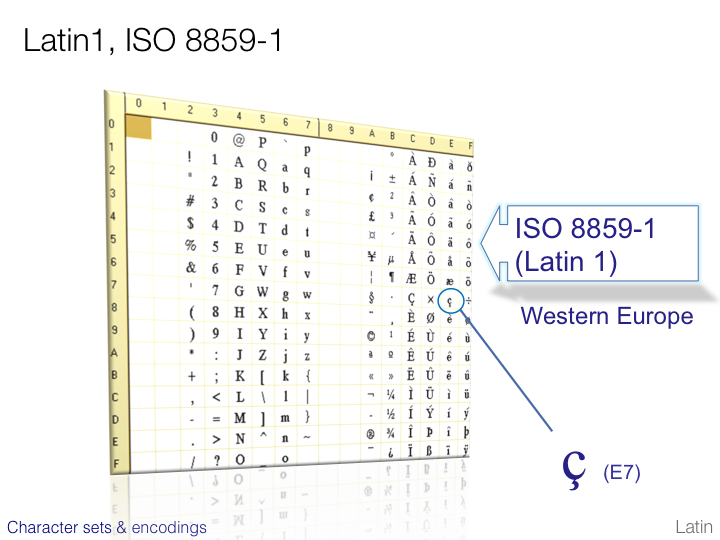
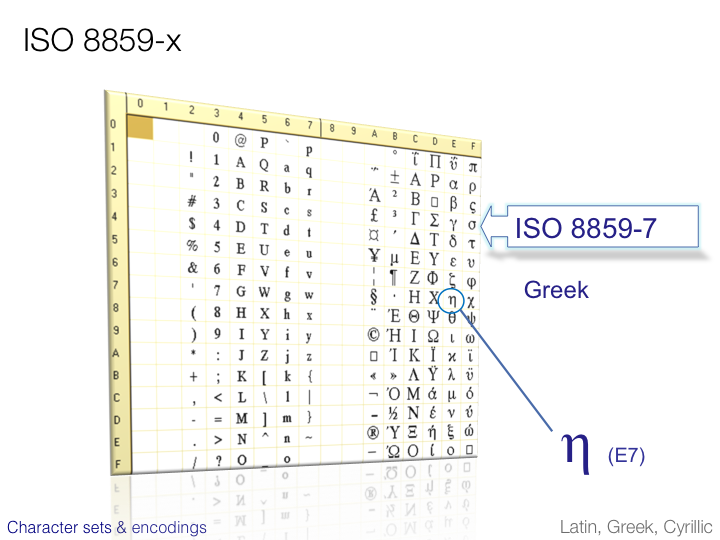
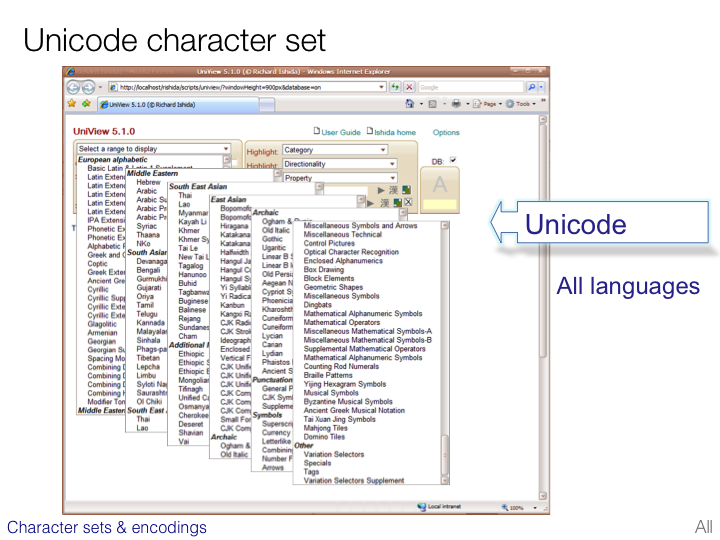
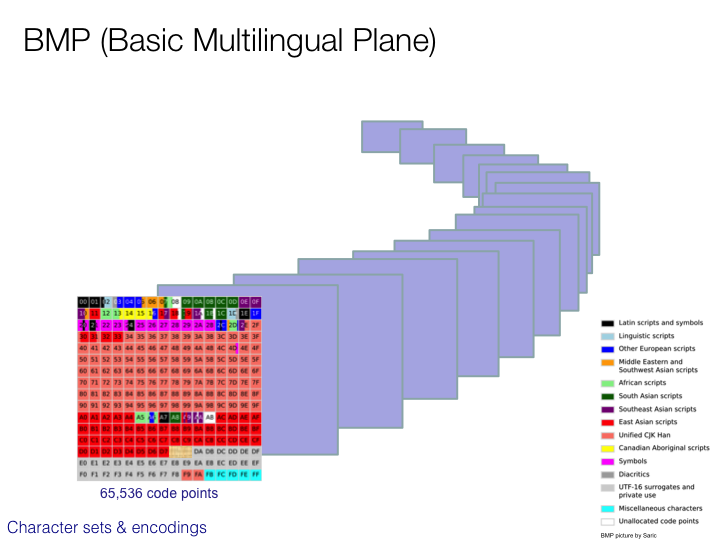
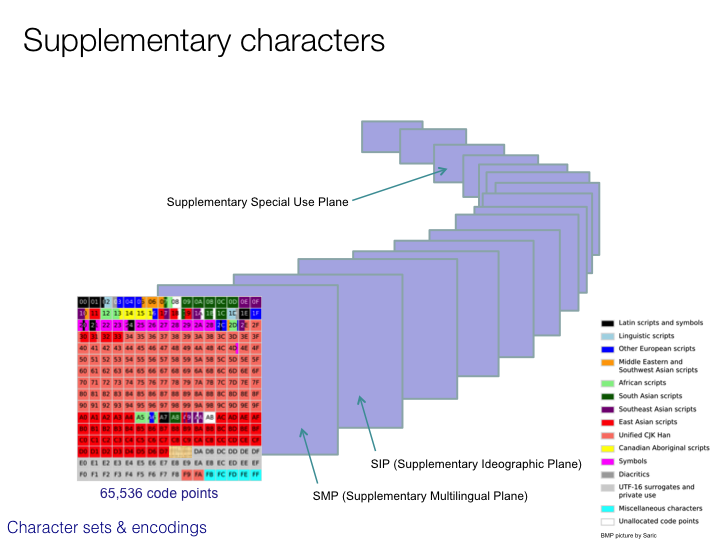
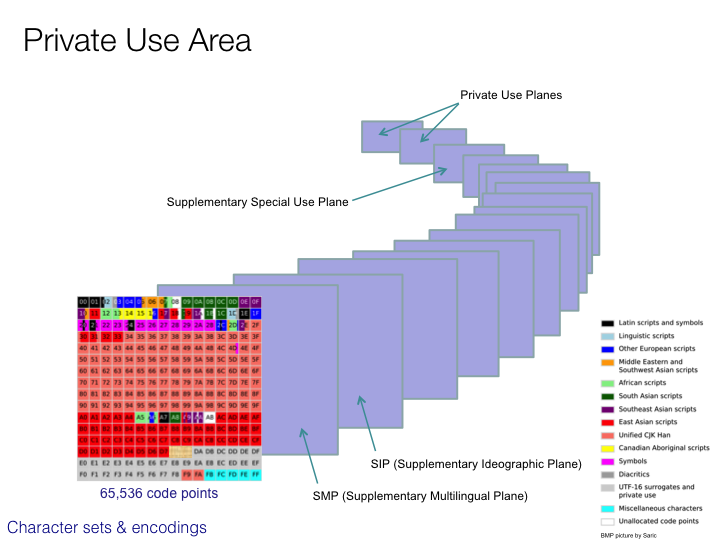
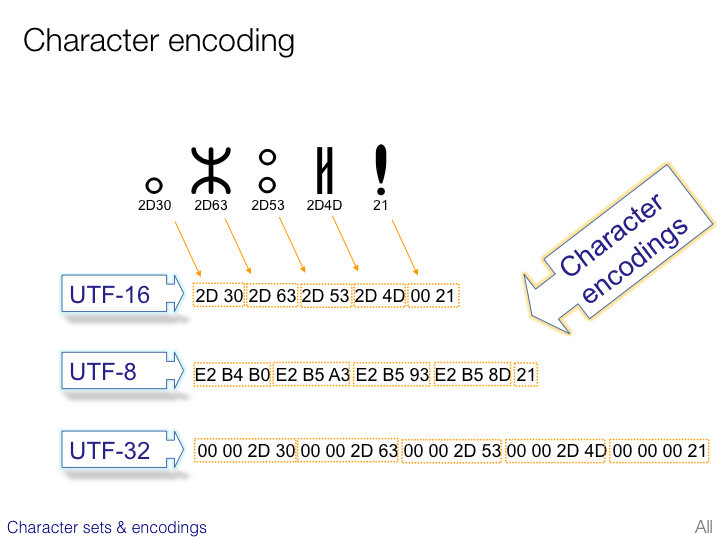
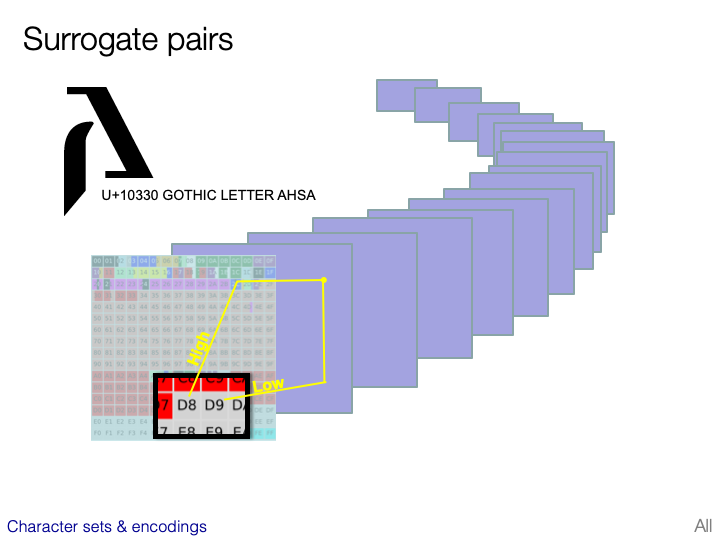
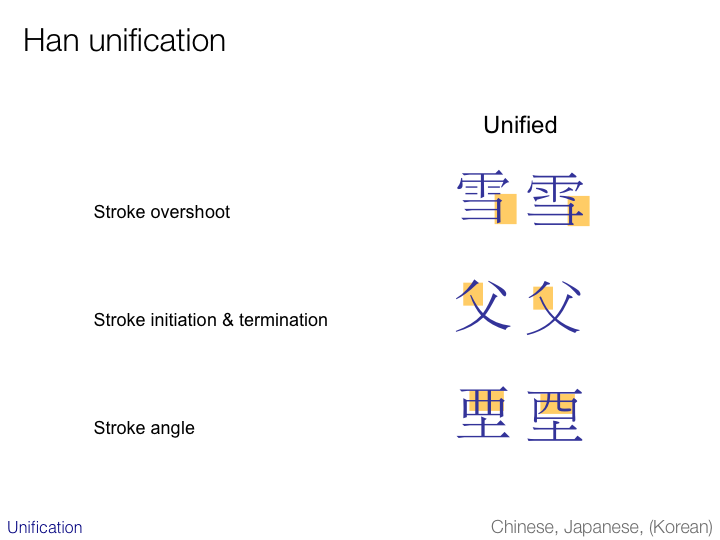
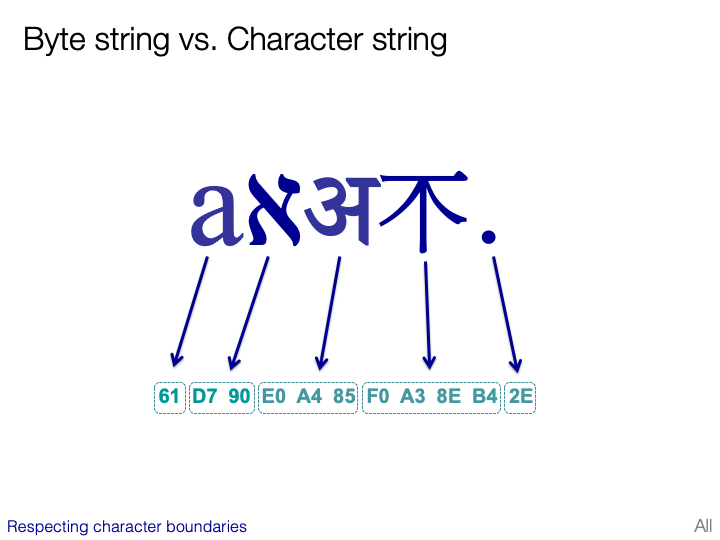
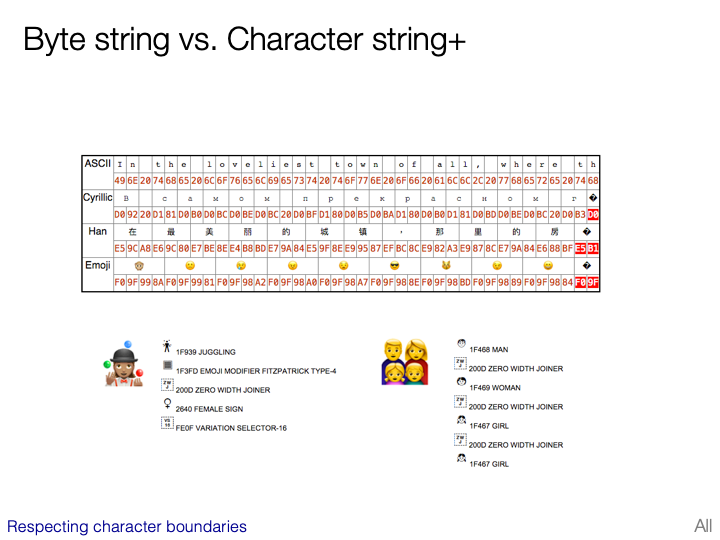
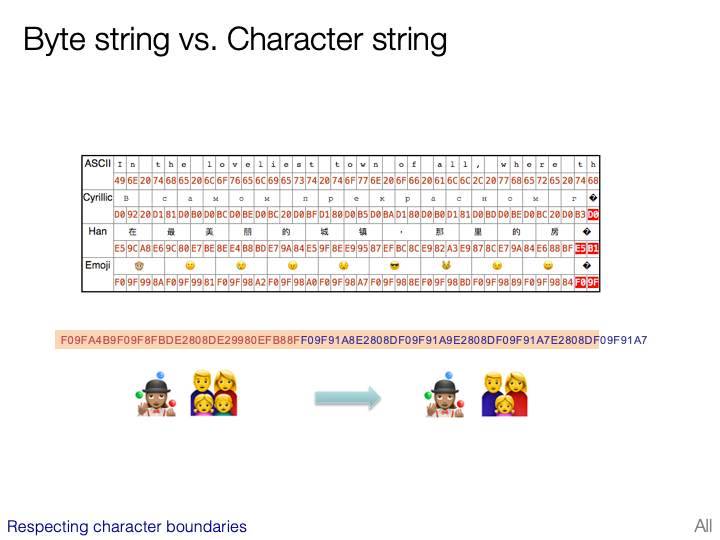
CJK character sets
Chinese

Initially there was only one type of Chinese – what we now call Traditional Chinese. Then in the 1950s Mainland China introduced a Simplified Chinese. It was simplified in two ways:
-
the more common character shapes were reduced in complexity,
-
a relatively smaller set of characters was defined for common usage than had traditionally been the case (resulting in the mapping more than one character in Traditional Chinese to a single character in the Simplified Chinese set).
This slide shows Traditional Chinese above and Simplified Chinese below.
Traditional Chinese is still used to write characters in Taiwan and Hong Kong, and much of the Chinese diaspora. Simplified Chinese is used in Mainland China and Singapore. It is important to stress that people speaking many different, often mutually unintelligible, Chinese dialects would use one or other of these scripts to write Chinese – ie. the characters do not necessarily represent the sounds.
There are a few local characters, such as for Cantonese in Hong Kong, that are not in widespread use.
In Chinese these ideographs are called hanzi (xan.ʦɹ̩). They are often referred to as Han characters.
There is another script used with Traditional Chinese for annotations and transliteration during input. It is called zhuyin (ʈʂu.in) or bopomofo, and will be described in more detail later.
It is said that Chinese people typically use around 3-4,000 characters for most communication, but a reasonable word processor would need to support at least 10,000. Unicode supports over 70,000 Han characters.

This slide shows examples of contrasting shapes in Traditional and Simplified ideographs.
The paragraph on the left is in Simplified Chinese. That on the right is Traditional. The slide shows the same two characters from each paragraph so that you can see how the shape varies. In one case, just the left-hand part of the glyph is different; in the other, the right-hand side is different.
Each of the large glyphs shown above is a separate code point in Unicode. The Simplified and Traditional shapes are not unified unless they are extremely similar. (Han unification will be explained in more detail later.)
Japanese

Japanese uses three native scripts in addition to Latin (which is called romaji), and mixes them all together.
Top centre on the slide is an example of ideographic characters, borrowed from Chinese, which in Japanese are called kanji. Kanji characters are used principally for the roots of words.
The example at the top right of the slide is written entirely in hiragana. Hiragana is a native Japanese syllabic script typically used for many indigenous Japanese words (as in this case) and for grammatical particles and endings. The example at the bottom of the slide shows its use to express grammatical information alongside a kanji character (the darker, initial character) that expresses the root meaning of the word.
Japanese everyday usage requires around 2,000 kanji characters – although Japanese character sets include many thousands more.

The example at the bottom left of this slide shows the katakana script. This is used for foreign loan words in Japanese. The example reads ‘te-ki-su-to’, ie. ‘text’.
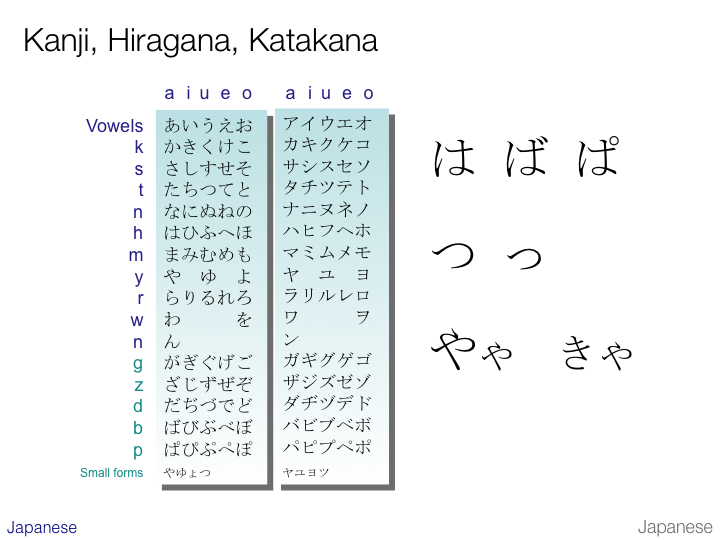
On the two slides above we see the more common characters from the hiragana (left) and katakana (right) syllabaries arranged in traditional order. A character in the same location in each table is pronounced exactly the same.
With the exception of the vowels on the top line and the letter ‘n’, all of the symbols represent a consonant followed by a vowel.
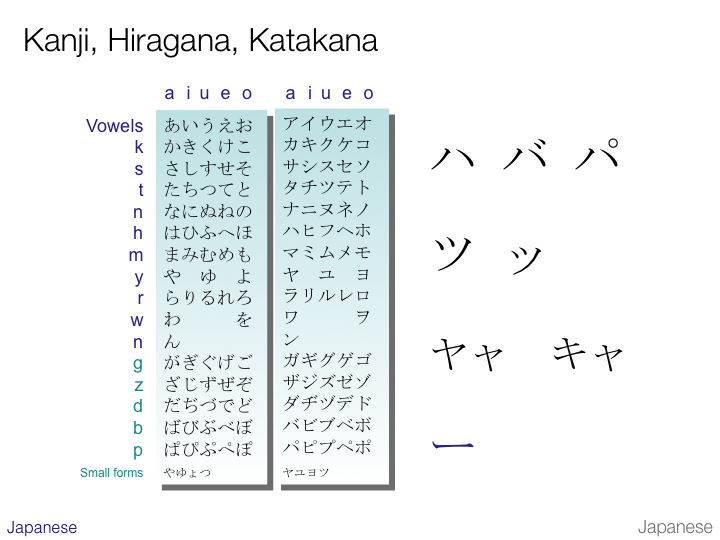
The first of the two slides highlights some script features (on the right) from hiragana. The second shows the correspondences in katakana.
Voiced consonants are indicated by attaching a dakuten mark (looks like a quote mark) to the unvoiced shape. The ‘p’ sound is indicated by the use of a han-dakuten (looks like a small circle). The slides show glyphs for ‘ha’, ‘ba’, and ‘pa’ on the top line.
A small ‘tsu’ (っ) is commonly used to lengthen a consonant sound.
Small versions of や, ゆ, and よ are used to form syllables such as ‘kya’ (きゃ), ‘kyu’ (きゅ), and ‘kyo’ (きょ) respectively.
When writing katakana the mark ー is used to indicate a lengthened vowel.
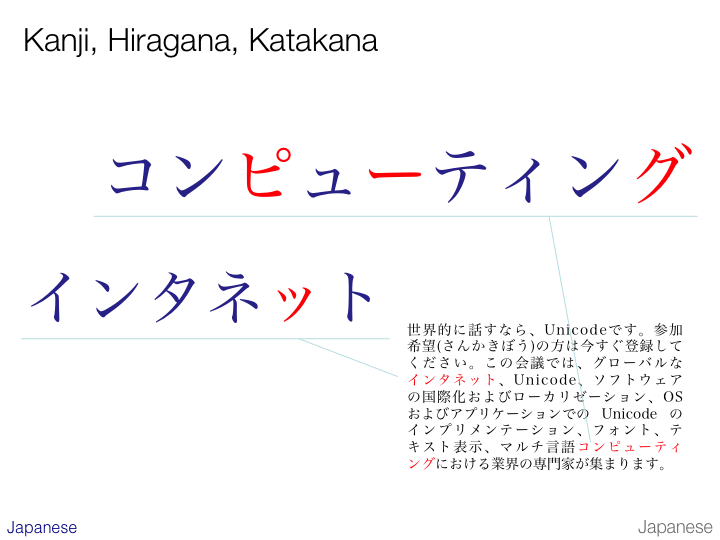
The lower example on the slide shows the small tsu being used in katakana to lengthen the ‘t’ sound that follows it. This can be transcribed as ‘intanetto’.
The higher example shows usage of other small versions of katakana characters. The transcription is ‘konpyuutingu’. In the first case the small ‘yu’ combines with the preceding ‘pi’ to produce ‘pyu’. In the second case the small ‘i’ is used with the preceding ‘te’ syllable to produce ‘ti’ – a sound that is not native to Japanese. (Their equivalent would be ‘chi’.)
The higher example also shows the use of the han-dakuten and dakuten to turn ‘hi’ into ‘pi’ and ‘ku’ into ‘gu’.
There is also a lengthening mark that lengthens the ‘u’ sound before it.

Han and kana characters are usually full-width, whereas latin text is half-width or proportionally spaced.
Half-width katakana characters do exist, and for compatibility reasons there is a Unicode block for half-width kana characters. These codes should not normally be used, however. They arise from the early computing days when Japanese had to be fitted into a Western-biased technology.
Similarly, it is common to find full-width Latin text, especially in tables. Again, there is a Unicode block dedicated to full width Latin characters and punctuation, but a font should be used instead.
Korean

Korean uses a unique script called hangul. It is unique in that, although it is a syllabic script, the individual phonemes within a syllable are represented by individual shapes. The example shows how the word ‘ta-kuk-o’ is composed of 7 jamos, each expressing a single phoneme. The jamos are displayed as part of a two dimensional syllabic character.
The initial jamo in the last syllable is not pronounced in initial position and serves purely to conform to the rule that hangul syllables always begin with a consonant.
It is possible to store hangul text as either jamos or syllabic characters in Unicode, although the latter is more common. Unicode enables both approaches.
South Korea also mixes ideographic characters borrowed from Chinese with hangul, though on nothing like the scale of Japanese. In fact, it is quite normal to find whole documents without any hanja, as the ideographic characters in Korean are called.
There are about 2,300 hangul characters in everyday use, but the Unicode Standard has code points for around 11,000.
Radicals

A radical is an ideograph or a component of an ideograph that is used for indexing dictionaries and word lists, and as the basis for creating new ideographs. The 214 radicals of the KangXi dictionary are universally recognised.
The examples enlarged on the slide show the ideographic character meaning ‘word’, ‘say’ or ‘speak’ (bottom left), and three more characters that use this as a radical on their left hand side.

The visual appearance of radicals may vary significantly.
Here the radical shown on the previous slide is seen as used in Simplified Chinese (top right). Although the shape differs somewhat it still represents the same radical.
On the bottom row we see the ‘water’ radical being used in two different positions in a character, and with two different shapes. This time the right-most example is found in both simplified and traditional forms.

Unicode dedicates two blocks to radicals. The KangXi radicals block (pronounced kʰɑŋ.ɕi) depicted here contains the base forms of the 214 radicals.
The CJK Radicals Extension contains variant shapes of these radicals when they are used as parts of other characters or in simplified form. These have not been unified because they often appear independently in dictionaries indices.
Characters in these blocks should never be used as ideographs.