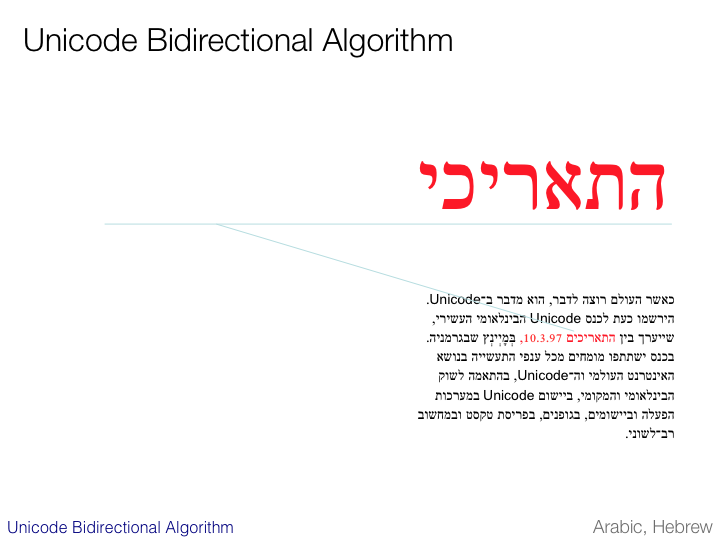
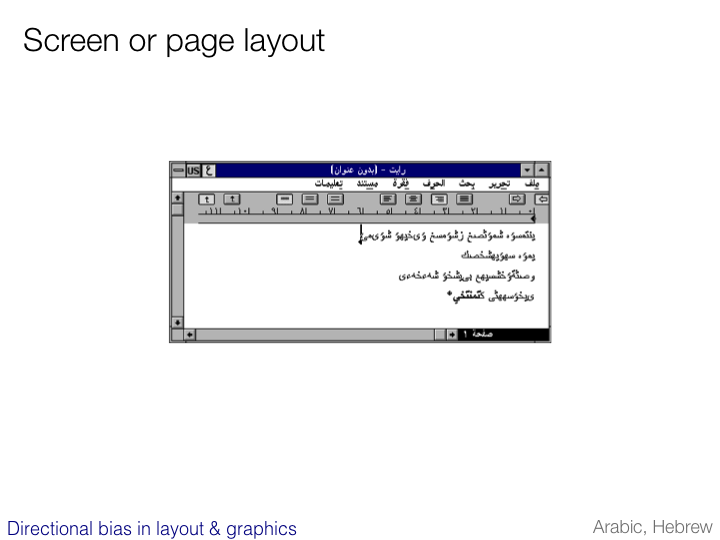
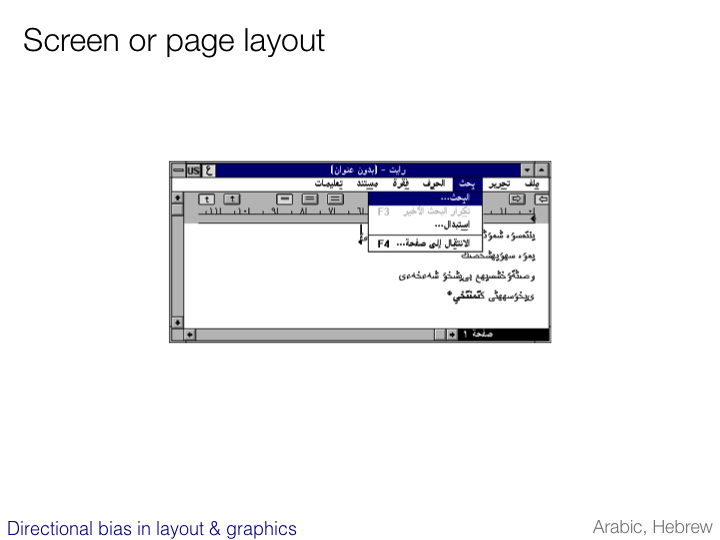
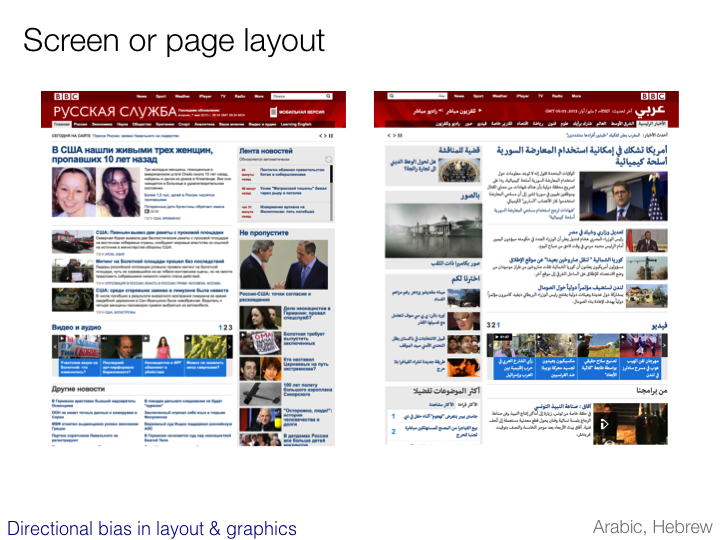
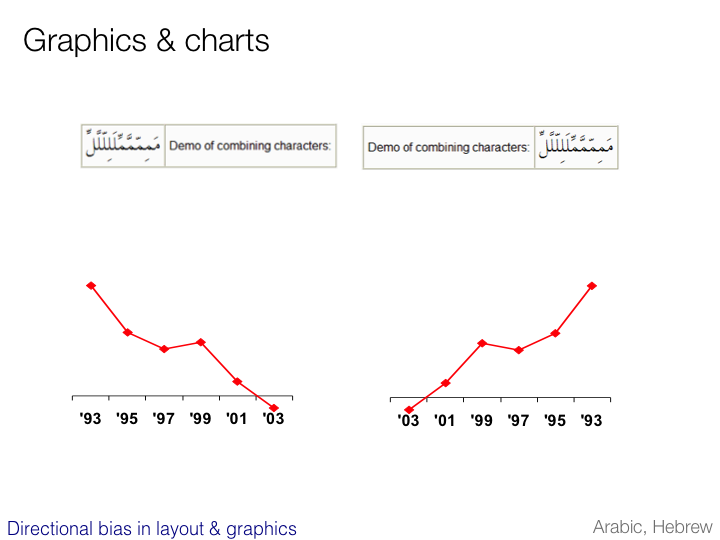
Vertical text
Reading direction


Vertical Mongolian lines are stacked from the left to the right of the page, but this is very unusual. Mongolian is also unusual in that it is only meant to be read vertically.
Lines in vertical Chinese, Japanese and Korean are stacked from the right to the left of the page. All of these scripts can also be set horizontally.
In Japan, vertically oriented text is still very common in printed matter such as books, magazines and newspapers. It is also quite common for Traditional Chinese. It is less common, but still found for Simplified Chinese and Korean text.
Columns in vertical text
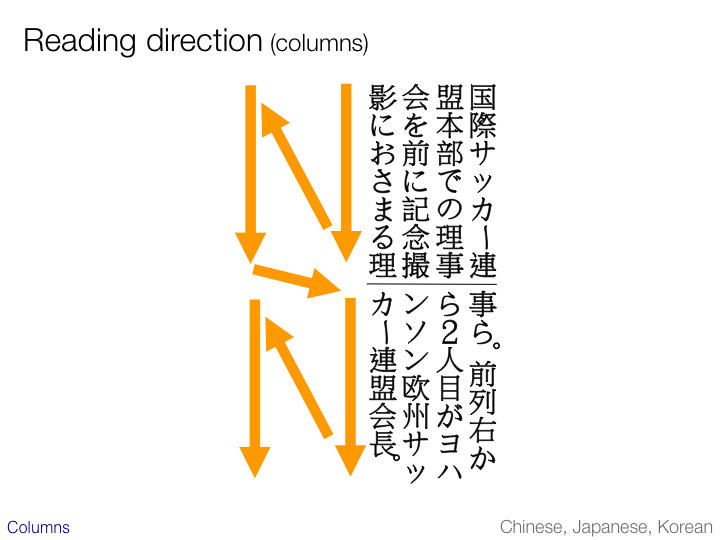
This slide illustrates the path of the eye in two-column vertical text. The columns, of course, run horizontally. If you are implementing an OCR application, this is an important thing to get right.
Rotations & shifts

This and the two following slides show differences between the same text when set horizontally and vertically.
On this slide we see how parentheses and vowel lengthening marks are rotated. Bear in mind that this does not reflect any change in the underlying characters – the change is purely in the choice of glyph.

This slide shows how punctuation and small kana characters move from one corner of the cell square to the other. This is not a question of rotation.
This is not always an issue. In Chinese a period or a comma is typically centered in the character cell.

This slide shows the treatment of embedded Latin text. Text typically flows down the line at a 90 degree rotation from the East Asian characters, however acronyms and initials are commonly not rotated.
Tate chu yoko

Vertical text often includes short runs of horizontal numbers or Latin text. In CSS this is referred to using the Japanese name tate chu yoko. It occurs in Chinese, Japanese and Korean vertical text.

The example on this slide shows the heading of a newspaper article in Korean. It is rather an extreme case!
(Note also the use of a hanja character meaning ‘hundred’ between the 3 and the 76.)