Factoids listed at the start of the EURid/UNESCO World Report on IDN Deployment 2013
5.1 million IDN domain names
Only 2% of the world’s domain names are in non-Latin script
The 5 most popular browsers have strong support for IDNs in their latest versions
Poor support for IDNs in mobile devices
92% of the world’s most popular websites do not recognise IDNs as URLs in links
0% of the world’s most popular websites allow IDN email addresses as user accounts
99% correlation between IDN scripts and language of websites (Han, Hangkuk, Hiragana, Katakana)
About two weeks ago I attended the part of a 3-day Asia Pacific Top
Level Domain Association (APTLD) meeting in Oman related to ‘Universal
Acceptance’ of Internationalized Domain Names (IDNs), ie. domain names
using non-ASCII characters. This refers to the fact that, although IDNs
work reasonably well in the browser context, they are problematic when
people try to use them in the wider world for things such as email and
social media ids, etc. The meeting was facilitated by Don Hollander, GM
of APTLD.
Here’s a summary of information from the presentations and discussions.
(By the way, Don Hollander and Dennis Tan Tanaka, Verisign, each gave
talks about this during the MultilingualWeb workshop in Madrid the week
before. You can find links to their slides from the event program.)
Basic proposition
International Domain Names (IDNs) provide much improved accessibility
to the web for local communities using non-Latin scripts, and are
expected to particularly smooth entry for the 3 billion people not yet
web-enabled. For example, in advertising (such as on the side of a bus)
they are easier and much faster to recognise and remember, they are also
easier to note down and type into a browser.
The biggest collection of IDNs is under .com and .net, but there are
new Brand TLDs emerging as well as IDN country codes. On the Web there
is a near-perfect correlation between use of IDNs and the language of a
web site.
The problems tend to arise where IDNs are used across cultural/script
boundaries. These cross-cultural boundaries are encountered not just
by users but by implementers/companies that create tools, such as email
clients, that are deployed across multilingual regions.
It seems to be accepted that there is a case for IDNs, and that they
already work pretty well in the context of the browser, but problems in
widespread usage of internationalized domain names beyond the browser
are delaying demand, and this apparently slow demand doesn’t convince
implementers to make changes – it’s a chicken and egg situation.
The main question asked at the meeting was how to break the vicious
cycle. The general opinion seemed to lean to getting major players like
Google, Microsoft and Apple to provide end-to-end support for IDNs
throughout their produce range, to encourage adoption by others.
Problems
Domain names are used beyond the browser context. Problem areas include:
- email
- email clients generally don’t support use of non-ascii email addresses
- standards don’t address the username part of email addresses as well as domain
- there’s an issue to do with smptutf8 not being visible in all the right places
- you can’t be sure that your email will get through, it may be dropped on the floor even if only one cc is IDN
- applications that accept email IDs or IDNs
- even Russian PayPal IDs fail for the .рф domain
- things to be considered include:
- plain text detection: you currently need http or www at start in google docs to detect that something is a domain name
- input validation: no central validation repository of TLDs
- rendering: what if the user doesn’t have a font?
- storage & normalization: ids that exist as either IDN or punycode are not unique ids
- security and spam controls: Google won’t launch a solution without
resolving phishing issues; some spam filters or anti-virus scanners
think IDNs are dangerous abnormalities
- other integrations: add contact, create mail and send mail all show different views of IDN email address
- search: how do you search for IDNs in contacts list?
- search in general already works pretty well on Google
- I wasn’t clear about how equivalent IDN and Latin domain names will be treated
- mobile devices: surprisingly for the APTLD folks, it’s harder to
find the needed fonts and input mechanisms to allow typing IDNs in
mobile devices
- consistent rendering:
- some browsers display as punycode in some circumstances – not very user friendly
- there are typically differences between full and hybrid (ie. partial) int. domain names
- IDNs typed in twitter are sent as punycode (mouse over the link in the tweet on a twitter page)
Initiatives
Google are working on enabling IDN’s throughout their application
space, including Gmail but also many other applications – they pulled
back from fixing many small, unconnected bugs to develop a company wide
strategy and roll out fixes across all engineering teams. The Microsoft
speaker echoed the same concerns and approaches.
In my talk, I expressed the hope that Google and MS and others would
collaborate to develop synergies and standards wherever feasible.
Microsoft, also called for a standard approach rather than in-house,
proprietary solutions, to ensure interoperability.
However, progress is slow because changes need to be made in so many places, not just the email client.
Google expects to have some support for international email addresses
this summer. You won’t be able to sign up for Arabic/Chinese/etc email
addresses yet, but you will be able to use Gmail to communicate with
users on other providers who have internationalized addresses. Full
implementation will take a little longer because there’s no real way to
test things without raising inappropriate user expectations if the
system is live.
SaudiNIC has been running Arabic emails for some time, but it’s a
home-grown and closed system – they created their own protocols, because
there were no IETF protocols at the time – the addresses are actually
converted to punycode for transmission, but displayed as Arabic to the
user (http://nic.sa).
Google uses system information about language preferences of the user
to determine whether or not to display the IDN rather than punycode in
Chrome’s address bar, but this could cause problems for people using a
shared computer, for example in an internet café, a conference laptop
etc. They are still worrying about users’ reactions if they can’t
read/display an email address in non-ASCII script. For email, currently
they’re leaning towards just always showing the Unicode version, with
the caveat that they will take a hard line on mixed script (other than
something mixed with ASCII) where they may just reject the mail.
A trend to note is a growing number of redirects from IDN to ASCII, eg. http://правительство.рф page shows http://government.ru in the address bar when you reach the site.
Other observations
All the Arabic email addresses I saw were shown fully right to left,
ie. <tld><domain>@<username>. I wonder whether this
may dislodge some of the hesitation in the IETF about the direction in
which web addresses should be displayed – perhaps they should therefore
also flow right-to-left?? (especially if people write domain names
without http://, which these guys seem to think they will).
Many of the people in the room wanted to dispense with the http://
for display of web addresses, to eliminate the ASCII altogether, also
get rid of www. – problem is, how to identify the string as a domain
name – is the dot sufficient?? We saw some examples of this, but they
had something like “see this link” alongside.
By the way, Google is exploring the idea of showing the user, by
default, only the domain name of a URL in future versions of the Chrome
browser address bar. A Google employee at the workshop said “I think
URLs are going away as far as something to be displayed to users – the
only thing that matters is the domain name … users don’t understand the
rest of the URL”. I personally don’t agree with this.
One participant proposed that government mandates could be very
helpful in encouraging adaptation of technologies to support
international domain names.
My comments
I gave a talk and was on a panel. Basically my message was:
Most of the technical developments for IDN and IRIs were developed at
the IETF and the Unicode Consortium, but with significant support by
people involved in the W3C Internationalization Working Group. Although
the W3C hasn’t been leading this work, it is interested in understanding
the issues and providing support where appropriate. We are, however,
also interested in wider issues surrounding the full path name of the
URL (not just the domain name), 3rd level domain labels, frag ids, IRI
vs punycode for domain name escaping, etc. We also view domain names as
general resource identifiers (eg. for use in linked data), not just for
a web presence and marketing.
I passed on a message that groups such as the Wikimedia folks I met
with in Madrid the week before are developing a very wide range of fonts
and input mechanisms that may help users input non-Latin IDs on
terminals, mobile devices and such like, especially when travelling
abroad. It’s something to look into. (For more information about
Wikimedia’s jQuery extensions, see here and here.)
I mentioned the idea of bidi issues related to both the overall
direction of Arabic/Hebrew/etc URLs/domain names, and the more difficult
question about to handle mixed direction text that can make the logical
http://www.oman/muscat render to the user as http://www.muscat/oman
when ‘muscat’ and ‘oman’ are in Arabic, due to the default properties of
the Unicode bidi algorithm. Community guidance would be a help in
resolving this issue.
I said that the W3C is all about getting people together to find
interoperable solutions via consensus, and that we could help with
networking to bring the right people together. I’m not proposing that
we should take on ownership of the general problem of Universal
Acceptance, but I did suggest that if they can develop specific
objectives for a given aspect of the problem, and identify a natural
community of stakeholders for that issue, then they could use our
Community Groups to give some structure to and facilitate discussions.
I also suggested that we all engage in grass-roots lobbying, requesting that service/tool providers allow us to use IDNs.
Conclusions
At the end of the first day, Don Hollander summed up what he had gathered from the presentations and discussions as follows:
People want IDNs to work, they are out there, and they are not going
away. Things don’t appear quite so dire as he had previously thought,
given that browser support is generally good, closed email communities
are developing, and search and indexing works reasonably well. Also
Google and Microsoft are working on it, albeit perhaps slower than
people would like (but that’s because of the complexity involved). There
are, however, still issues.
The question is how to go forward from here. He asked whether APTLD
should coordinate all communities at a high level with a global
alliance. After comments from panelists and participants, he concluded
that APTLD should hold regular meetings to assess and monitor the
situation, but should focus on advocacy. The objective would be to
raise visibility of the issues and solutions. “The greatest
contribution from Google and Microsoft may be to raise the awareness of
their thousands of geeks.” ICANN offered to play a facilitation role
and to generate more publicity.
One participant warned that we need a platform for forward motion,
rather than just endless talking. I also said that in my panel
contributions. I was a little disappointed (though not particularly
surprised) that APTLD didn’t try to grasp the nettle and set up
subcommittees to bring players together to take practical steps to
address interoperable solutions, but hopefully the advocacy will help
move things forward and developments by companies such as Google and
Microsoft will help start a ball rolling that will eventually break the
deadlock.

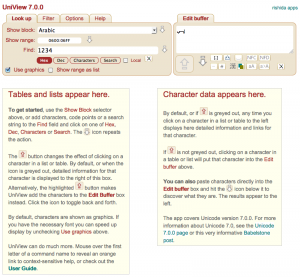
 icon. Clicking on the icon takes you to a page listing resources for
that block, rather than listing the resources in the lower right part of
UniView’s interface.
icon. Clicking on the icon takes you to a page listing resources for
that block, rather than listing the resources in the lower right part of
UniView’s interface.















 icon alongside the
icon alongside the  Clicking on this will display the characters in the area in the lower
right part of the page with all relevant characters converted to
uppercase, lowercase and titlecase. Characters that had no case
conversion information are also listed.
Clicking on this will display the characters in the area in the lower
right part of the page with all relevant characters converted to
uppercase, lowercase and titlecase. Characters that had no case
conversion information are also listed. Clicking on this produces the same kind of output as clicking on the
icon just above, but shows the mappings for those characters that have
been changed, eg. e→E.
Clicking on this produces the same kind of output as clicking on the
icon just above, but shows the mappings for those characters that have
been changed, eg. e→E.





February 24th, 2012 at 6:46 pm
Thanks Richard for posting this explanation. I think this is good news, and not just for online MT (as you note). So much content that goes through human workflows is in HTML (or XHTML) format, and so far what to translate has, for the most part, been left up to the translator’s discretion. While translators will generally get it right (which they can do because they are able to infer a lot about texts) they do sometimes get it wrong. Having this notion of a translate directive embedded at a fundamental level into core technologies is a major coup for the translation and localization industry because it will raise awareness and simplify processes.
I’m excited by the news that so many tools are already picking up on this new attribute. I’ve seen far too many instances where good ideas languish for years without adoption. I think this success vindicates the agile approach we anticipate for MultilingualWeb-LT of picking small, manageable problems and addressing them with simple solutions. While there is a place and need for mega-standards like XLIFF, TMX, TBX, etc., I think the future of standards will increasingly revolve around small standards that work together to create a whole greater than the sum of their parts. What’s fantastic about this approach is that developers will be able to implement the parts that matter to them without the overhead of implementing complex formats of limited value.
February 24th, 2012 at 9:07 pm
[…] attribute that allows fine-grained control over what HTML content should be translated, or not. Richard Ishida of the W3C has all the details of the attribute and its applicability, as well as some interesting insight […]