
New app: Encoding converter
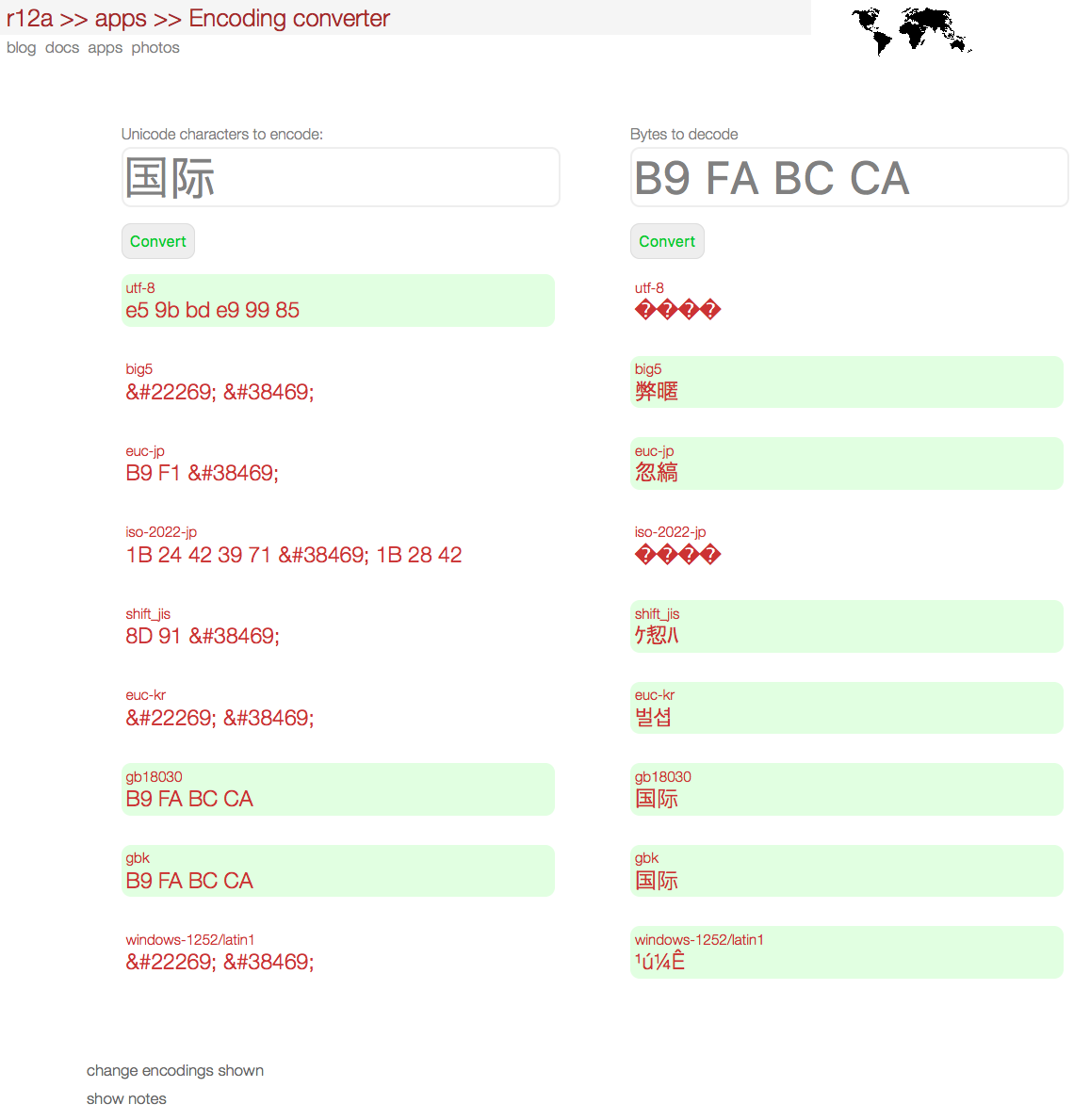
This app allows you to see how Unicode characters are represented as bytes in various legacy encodings, and vice versa. You can customise the encodings you want to experiment with by clicking on change encodings shown. The default selection excludes most of the single-byte encodings.
The app provides a way of detecting the likely encoding of a sequence of bytes if you have no context, and also allows you to see which encodings support specific characters. The list of encodings is limited to those described for use on the Web by the Encoding specification.
The algorithms used are based on those described in the Encoding specification, and thus describe the behaviour you can expect from web browsers. The transforms may not be the same as for other conversion tools. (In some cases the browsers may also produce a different result than shown here, while the implementation of the spec proceeds. See the tests.)
Encoding algorithms convert Unicode characters to sequences of double-digit hex numbers that represent the bytes found in the target character encoding. A character that cannot be handled by an encoder will be represented as a decimal HTML character escape.
Decoding algorithms take the byte codes just mentioned and convert them to Unicode characters. The algorithm returns replacement characters where it is unable to map a given byte to the encoding.
For the decoder input you can provide a string of hex numbers separated by space or by percent signs.
Green backgrounds appear behind sequences where all characters or bytes were successfully mapped to a character in the given encoding. Beware, however, that the character mapped to may not be the one you expect – especially in the single byte encodings.
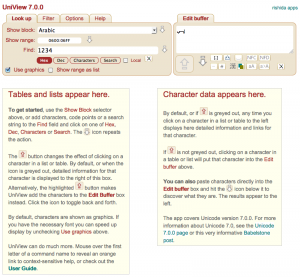
To identify characters and look up information about them you will find UniView extremely useful. You can paste Unicode characters into the UniView Edit Buffer and click on the down-arrow icon below to find out what they are.
(Click on the name that appears for more detailed information.) It is
particularly useful for identifying escaped characters. Copy the
escape(s) to the Find input area on UniView and click on Dec just below.
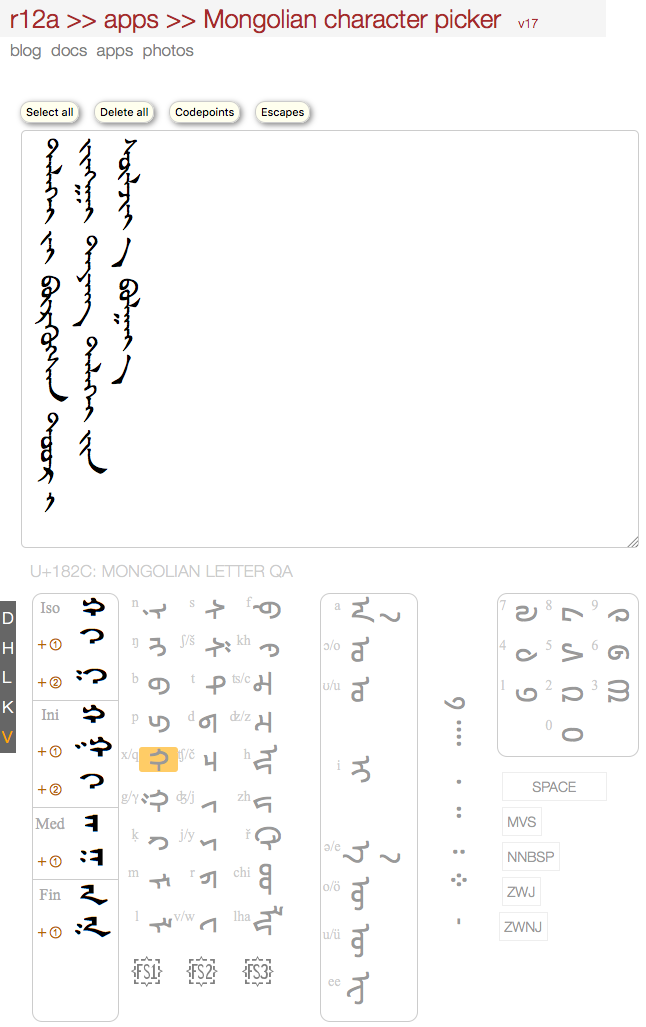












January 7th, 2015 at 12:32 am e
Richard, your post tickled my memory about a draft sitting in my list of blog posts to complete, so I sat down and completed it. My blog describes how we resolved the combining issue for a Lao keyboard; the principle should be applicable to other systems. It’s a bit wordy though…
http://marc.durdin.net/2015/01/how-to-rendering-combining-marks-consistently-across-platforms-a-long-story/