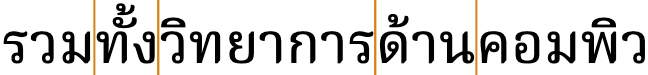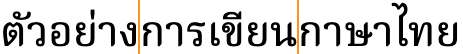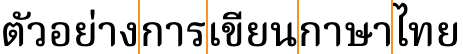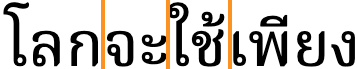This page brings together basic information about the Thai script and its use for the Thai language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Thai using Unicode.
The Thai script ( อักษรไทย ) is used primarily for writing the Thai language, as well as Northern Thai, Northeastern Thai, Southern Thai, and Thai Song, which are separate languages. It is also used to write a number of minority languages in Thailand, Laos and China, as well as Pali, which is widely used in Buddhist temples and monasteries.s
The alphabet was derived from the Old Khmer script, which descended from Pallava. Thai tradition attributes the creation of the script to King Ramkhamhaeng the Great (พ่อขุนรามคำแหงมหาราชpʰo kʰun raːm kʰam ŋɛː ma haː raː tɕʰa) in 1283, though this has been challenged.
Both the Thai language and script are closely related to Lao and its script.
Vowel sounds are often written differently when they appear in a closed vs. open syllable. Thai vowels all come in short and long forms, which are phonemically distinctive. Short vowels in open syllables usually end with a glottal stop. A set of diphthongs end in ə, and most vowels can be followed by either w or j.
There are 5 pre-base vowel glyphs, but no circumgraphs, although the many composite vowel components often appear on more than one side of the base. This page lists 37 composite vowels (including diphthongs), which can involve up to 4 glyphs (plus a tone mark) at a time, and can surround the base consonant(s) on up to 3 sides simultaneously.
Consonants Thai has 41 basic consonant letters. Each onset consonant is associated with a high, mid, or low class related to tone.
Vowel absenceVowel absence is not indicated using conjunct forms, or a visible combining mark. Given that consonants normally include an inherent vowel, the orthography normally needs a way to indicate when a consonant is not followed by a vowel, but Thai doesn't.This can lead to ambiguous parsing of text, since it's not clear whether a consonant represents a syllable coda or a new syllable with inherent vowel. , or dedicated syllable-final combining marks. Syllable-initial clusters and syllable-final consonant sounds are all written with ordinary consonant letters. There are no dedicated medial consonant characters.
Syllable codas are all written with ordinary consonant letters, with the exception of ◌ำ. It can therefore be difficult to algorithmically detect syllable boundaries.
NumbersThai has native digits, and they are commonly used.
LayoutThai text runs left to right in horizontal lines. Spaces separate phrases, rather than words. There is no case distinction.
Punctuation is mostly ASCII, but some native punctuation marks are also used.
Notable features
visual encoding: pre-base letters rather than pre-base glyphs
no conjuncts
no independent vowel letters
substantial use of composite vowel signs
consonant clusters treated as indivisible units, even though there are no conjuncts
3 consonant classes determine tone along with context & tone marks
The following table provides typical phonological transcriptions and descriptions for the five tones.wl§#Tones
high
á
˦˥
live or dead syllables
ค้า; มัก
mid
a/ā
˧
live syllables only
คา
low
à
˨˩
live or dead syllables
ข่า; หมัก
rising
ǎ
˧˨˧
live syllables only
ขา
falling
â
˥˩
live or dead syllables
ค่า; มาก
Structure
Thai syllables allow the following patterns, where V can be a short or a long vowelc§#Thai.
VVCCVCVCCCVCCVC
The long vs. short vowel distinction is phonemically important. Long vowels are approximately twice the length of short ones. All open syllables have long vowels.wl§#Vowel_developments
Consonant clusters only occur in syllable initial position, with the following permissable combinations:c§#Thai
pʰrpʰl
tʰr
kʰrkʰlkʰw
Syllable-final consonants can be one of the following.c§#Thai Stops are unreleased.
-p̚-t̚-k̚-m-n-ŋ-j-w
Vowels
Simple
◌ี,◌ิ,,◌ื,◌ือ,◌ึ,,◌ู,◌ุ
เ◌,เ◌ะ,เ◌็,,เ◌อ,เ◌ิ,เ◌อะ,,โ◌,ⓘ,โ◌ะ,◌็อ
แ◌,แ◌ะ,แ◌็,,อ,◌็,ⓘ,เ◌าะ,◌็อ
◌า,ⓘ,◌ะ,◌ั,รร
Rhymes
◌ำ,รร
Diphthongs
เ◌ีย,เ◌ียะ, ,เ◌ือ,เ◌ือะ, ,◌ัว,◌ัวะ,ว
ไ◌,ใ◌,◌าว,เ◌า,
Vocalics
ฤ,ฤ,ฦ,ฤๅ,ฦๅ
Standalone
อ,อ,อ
ⓘ represents the inherent vowel. ◌ indicates the location of a consonant, but does not necessarily indicate a combining mark. Not listed here are numerous additional diphthongs that are created by adding a ย or ว glide after vowels shown in this table (see Rhymes ending in semivowels).
Inherent vowels
ก
ko ~ ka ~ kɔː
The inherent vowel is pronounced o inside a closed syllable, and a in an open syllable. So ka can be written by simply using the consonant letter ก, and kon by just the 2 consonants, กน. Example of a single word using both inherent vowels:
ถนน
ถ,น,น
A third inherent vowel, ɔː, occurs before a syllable-final RA (which is pronounced n).
eg.
ศร
นคร
น,ค,ร
Since Thai consonants normally include an inherent vowel, the orthography would be expected to have ways to indicate a consonant that is not followed by a vowel sound. For Thai, this is not the case. See novowel.
Post-consonant vowels
กิ
ki
Post-consonant vowel sounds are represented using combining marks, and vowel letters, including 4 consonants, very often combined into composite vowels. This page lists 37 composite vowels (including diphthongs), which can involve up to 4 glyphs (plus a tone mark) at a time, and can surround the base consonant(s) on up to 3 sides simultaneously.
Vowel sounds are often written differently when they appear in a closed vs. open syllable. Thai vowels all come in short and long forms, which are phonemically distinctive. Short vowels in open syllables usually end with a glottal stop. A set of diphthongs end in ə, and most vowels can be followed by either -w or -j.
Thai uses visual placement: only the 8 vowel components that appear above or below the consonant are combining marks; the others are ordinary spacing characters that are typed in the order seen.
There are 5 pre-base vowel glyphs, but no circumgraphs, although the many composite vowel signs have components that often appear on more than one side of the base.
Simple vowels
Some vowel sounds are written differently in open syllables and closed syllables.
The following panel lists monophthongs in open syllables. The dotted circle shows the location of adjacent consonants. Twelve code points are used to write 18 vowel sounds.
The next panel shows how the same vowels are normally written in closed syllables. Eighteen vowel sounds are written using 14 code points. Only 7 of those sounds are written differently from open syllables. Sounds that are written in the same way as for open syllables are in a lighter colour.
The consonant 0E2D can also be pronounced as the vowel ɔː when it appears alone after a base consonant. It is also used as a vowel carrier for standalone vowels (see standalone).
eg.
พอง
The consonant 0E23 is pronounced as a vowel a when doubled in a closed syllable (see doubleRA).
Diphthongs, triphthongs, & complete rhymes
Thai complex vowels are complicated and numerous. The way they are written also varies according to whether they appear in an open or a closed syllable. The following panel shows open syllable.
Most complex Thai vowels involve adding a final -j or -w glide after a vowel. The following panel shows combinations that don't follow that pattern. Except for uə̯, they are spelled the same whether the syllable is open or closed. However, there are 2 ways of spelling each diphthong in open syllables.
เ◌ีย,เ◌ียะ,เ◌ือ,เ◌ือะ,◌ัวะ,◌ัว,◌ว◌
eg.
เจี๊ยะ
กลัว
This next panel shows diphthongs and triphthongs that are produced using a following glide. Nearly all of these simply tack ย or ว onto the end of the vowel. Each of the items shown here constitutes a complete syllabic rhyme.
Note that the above set includes 2 single code points that represent diphthongs: ไ and ใ.
eg.
ไก่
ใบ
The final panel in this section shows some complete Thai rhymes that have special spellings.
◌ำ,◌รร
eg.
กรำ
กรรไกร
Doubled RA
The consonant 0E23 is pronounced as a vowel a when doubled medially.
eg.
ธรรม
When doubled at the end of a syllable it is pronounced an.
eg.
กรรไกร
Note, however, that this may also constitute the end and beginning of two syllables.
eg.
ภรรยา
Maitaikhu
0E47 appears alone, like a vowel character, over a consonant in one word only, with the pronunciation ɔ̂ː.
ก็
It is more often used to convert the vowels produced by the following three vowel signs to short vowels when they are followed by a final consonant (dotted circles represent consonants here).
เ◌eː becomes เ◌็◌e
◌อ◌ɔː becomes ◌็อ◌ɔ,
แ◌ɛː becomes แ◌็◌ɛ (not very common).
eg.
เด็ก
ซ็อกเก็ต
น้ำแข็ง
It is also used for the diphthong ewเ◌็ว (eːw > ew).
eg.
เร็ว
Sara AM & nikhahit
0E33 is classed as a vowel, but also contains the final consonant m, represented by a built-in encoding_nikhahit.
eg.
น้ำ
Used in Pali and Sanskrit, 0E4D is not commonly used alone in Thai, except that when letter-spacing Thai text it is necessary to add the space between the circle and the remainder of 0E33. See inter_character_spacing.
The separation is not produced by NFD normalisation (see also encoding_nikahit).
Vowel length
In common with other languages, i, ɯ, u, and a vowels have dedicated characters for long and short sounds. But many composite vowels use 0E30 or 0E47 as shorteners. The following provides one example of the general pattern.
เ◌,เ◌ะ,เ◌็◌
This can be seen clearly by comparing the long and short vowels in vowel_mappings.
Nasalisation
The orthography has no special mechanism to indicate vowel nasalisation.
Standalone vowels
อ
Thai uses 0E2D as a base for vowel signs.
eg.
อิ่ม
อิ่,ม
สะอาด
ส,ะ,อ,า,ด
เออออ
เ,อ,อ,อ,อ
อ on its own represents the same sound as the inherent vowel.
This section describes various vowel components and behaviours associated with this orthography.
Pre-base vowel glyphs
โก
koː
Five vowel glyphs appear to the left of the onset consonant(s).
เ,แ,ใ,ไ,โ
Since Thai uses a visual encoding model, these are not combining marks. They are typed and stored before the base.
eg.
ไข่
ไ,ข่
These vowel characters are actually placed before the start of the syllable. This means that a word with a consonant cluster at the start separates the pre-base vowel from any post-base vowels by more than one consonant character.
eg.
เปล่า
เ,ป,ล่,า
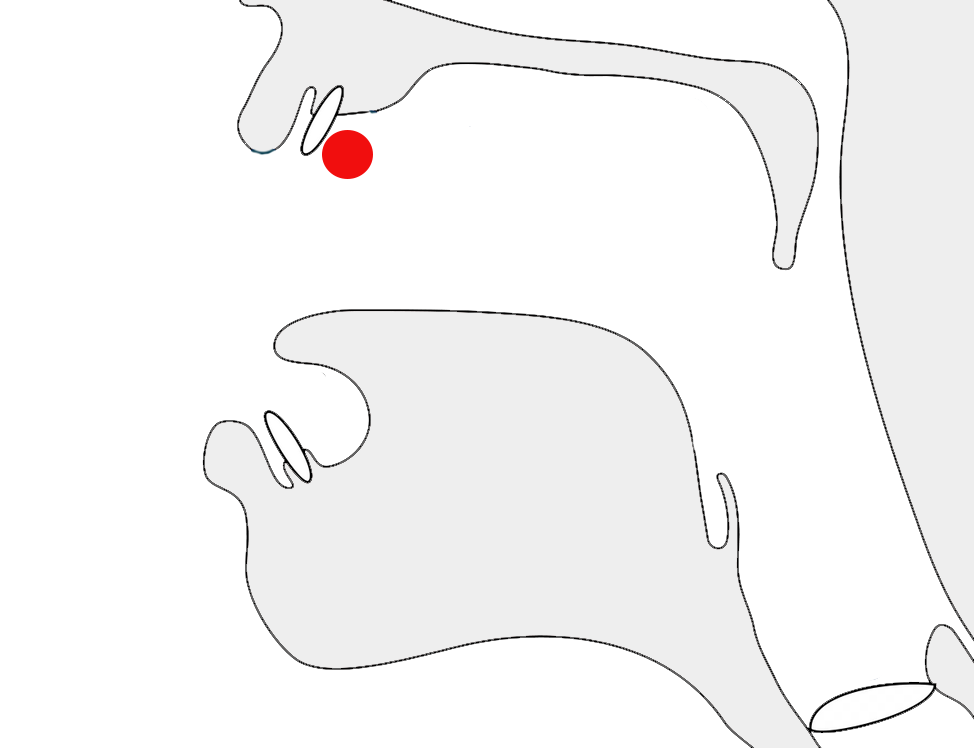
fig_prebase graphically illustrates the arrangement of glyphs for the word program.
Two pre-base glyphs, rendered 2 characters earlier than their pronounced location due to onset clusters.show composition
โปรแกรม
แ should not be typed as two successive เ characters (see encoding_sarah_ae).
Composite vowels
เกียะ
kiəʔ
This page lists 37 composite vowels (including diphthongs) made from 12 dedicated vowel characters, and 4 consonants. Composite vowels can involve up to 4 glyphs (plus a tone mark), and glyphs can surround the base consonant(s) on up to 3 sides.
A composite vowel made up of 4 vowel sign components.show composition
เกี๊ยะ
Some represent plain vowel sounds:
◌ือ,เ◌ะ,เ◌็,เ◌ิ,เ◌อ,เ◌อะ,โ◌ะ,◌็อ,แ◌ะ,แ◌็,เ◌าะ
The other composite vowels represent diphthongs, which generally end in one of ə̯, i, or w.
For some, the spelling isn't completely obvious.
เ◌ีย,เ◌ียะ,เ◌ือ,เ◌ือะ,◌ัว,◌ัวะ
In many other cases, a semivowel is simply added after one of the vowels seen earlier. See diphthongV for a list.
Finally, the two vocalic letters can be lengthened using an additional, special character (see vocalics).
ฤๅ,ฦๅ
Characters that don't appear in the combinations:
ร,◌ำ,◌ึ,ใ◌Show which combinations contain a given character:
The following list shows where vowel sign glyphs are positioned around a base consonant to produce vowels, and how many instances of that pattern there are. The figure after the + sign represents combinations of Unicode characters,
5 pre-base, eg. โกok̯ (ko)
2 post-base, eg. กาk̯ā
5 superscript, eg. กิk̯i
2 subscript, eg. กุk̯u
1+5 sup+post-base, eg. กือk̯ɯ̄ʔ̯kɯːo
+4 post+post-base, eg. กาวk̯āw̱kaːw
+2 sub+post-base, eg. กุยk̯uy̱kuj
+10 pre+post-base, eg. เกะek̯akè
+3 pre+superscript, eg. เกิek̯ikɤː
+2 super+post+post, eg. กัวะk̯äw̱akua
+2 pre+post+post, eg. เกาะek̯āakɔ̀
+3 pre+sup+post-base, eg. เกือek̯ɯ̄ʔ̯kɯːa
+4 pre+sup+post+post-base, eg. เกียะek̯īy̱akiːa
At maximum, vowel components can occur concurrently on 3 sides of the base.
Distribution of vowel elements is as follows:
ั ิ ี ึ ื ็
ำ
เ แ ใ ไ โ
อ ะ า ย ว ๅ
ะ ย
ุ ู
Tones
Tone in Thai is indicated by a combination of the consonant class, the syllable type (live/dead), vowel length (for dead syllables), plus any tone mark.
Each onset consonant is associated with a 'high', 'mid', or 'low' class, which is related to, but not indicative of, tone. (For example, when they appear without tone marks the 'high' class consonants produce a rising tone, and 'mid' or 'low' class consonants both produce a mid tone.)
Tone is also affected by the use of the following combining marks on live syllables, however in 2 cases the result of their use is also context-dependent, due to historical linguistic changes. (For example, 0E48 can produce either a low tone or a falling tone, depending on the class of the onset.)
◌่,◌้,◌๊,◌๋Figure out the tone, depending on the sequence of characters used.
Consonant
Dead?
Tone mark
Tone
high
dead
short
˩˩low
long
˩˩low
live
-
˩˥rising
่
˩˩low
้
˥˩falling
mid
dead
short
˩˩low
long
˩˩low
live
-
˧˧mid
่
˩˩low
้
˥˩falling
๊
˦˥high
๋
˩˥rising
low
dead
short
˦˥high
long
˥˩falling
live
-
˧˧mid
่
˥˩falling
้
˦˥high
Dead syllables
The following table shows the various ways of writing tones in dead syllables. Only 3 tones are available, and no diacritics are used. Vowel length changes the tone after a low register consonant.
consonant
vowel length
high tone
LOW
short
low tone
HIGH
–
MID
–
falling tone
LOW
long
Live syllables
The next table shows the various ways of writing tones in live syllables. All 5 tones are possible.
consonant
diacritic
high tone
MID
0E4A
LOW
0E49
mid tone
MID
–
LOW
–
low tone
HIGH
0E48
MID
0E48
rising tone
HIGH
–
MID
0E4B
falling tone
HIGH
0E49
MID
0E49
LOW
0E48
Tone mark position
The expected typing and storage position for tone marks is immediately after the base consonant of the syllable, or after a superscript or subscript vowel mark if there is one.
eg.
ข้าว
คิ้ว
กว้าง
The tone mark should be typed before ำ, but should be displayed above the nikhahit by the application.
eg.
ก่ำ
Vowel sounds mapped to characters
This section maps Thai vowel sounds to common graphemes in the Thai orthography.
The ◌ indicates the location of a consonant relative to the vowel sign; if there are 2 of these, the vowel is used only in closed syllables.
0E40 25CC 0E37 0E2D 0E22Only found in about 20 common words in Thai.
uj
0E38 0E22
uːj
0E39 0E22
uəj
0E27 0E22
uaːj
0E27 0E32 0E22This is actually Cw+aːj.
ew
0E40 25CC 0E47 0E27
eːw
0E40 25CC 0E27
ɤːw
0E40 25CC 0E22
oːw
0E42 25CC 0E22(rare)
ɛːw
0E41 25CC 0E27
ɔj
0E2D 0E22
ɔːj
0E2D 0E22
aj
0E44 25CC
0E43 25CC
0E31 0E22
0E44 25CC 0E22variant spelling
aːj
0E44 25CC
0E43 25CC
0E32 0E22
aw
0E40 25CC 0E32
aːw
0E32 0E27
Wiktionary provides a very useful table of Thai rhymes.
Vocalics
ฤ,ฦ,ๅ
In Wiktionary all the words that are written with ฦ are described as obsolete spellings.
The long forms of both are created using ๅ. That character is only used in this context.
eg.
ฤตู
อังกฤษ
ฤๅษี
ระฦก
ฦๅชา
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Given that consonants normally include an inherent vowel, the orthography normally needs a way to indicate when a consonant is not followed by a vowel, but Thai doesn't.
Thai doesn't have conjuncts, or any way of generally indicating where an inherent vowel is cancelled. As described in finals, this can lead to ambiguous parsing of text, since it's not clear whether a consonant represents a syllable coda or a new syllable with inherent vowel.
0E3A is used as a virama when writing Pali. It is not used in modern Thai.
One exception is the use of the ◌ำ rhyme for syllables with an m coda (see nikhahit).
The first few rows are for initial consonants. The later rows are for syllable-final consonants.
Basic consonants
Each of the basic consonants is associated with one of 3 classes (high, mid, and low), that play a part in indicating the tone of the syllable (see tones). In not all cases does this lead to more than one letter for a given consonant.
The pronunciation of a letter often differs when the consonant is the onset or coda of a syllable. The hyphens indicate where a pronunciation is that of a syllable coda.
Click on the letters below for more detailed information and examples of use. If no dash appears with the IPA transcription, it indicates the pronunciation in syllable-initial position; a dash before indicates the pronunciation for syllable codas.
high
ผ,ถ,ฐ,ข,ฉ,ฝ,ส,ศ,ษ,ห
mid
ป,บ,ต,ฏ,ด,ฎ,ก,จ
low
พ,ภ,ท,ธ,ฑ,ฒ,ค,ฆ,ช,ฌ,ฟ,ซ,ฮ,ม,น,ณ,ง,ว,ร,ล,ฬ,ย,ญ
High class nasals & liquids with HO
A silent ห is added before the characters in the list below to make their default tonal class high.
หม,หน,หง,หว,หร,หล,หย,หญ
eg.
หมา
หยุด
See onsets for further details about how these are presented.
The letter O ANG
อ
อ represents a glottal stop or is silent when used as a base for vowels at the beginning of a syllable (see standalone).
eg.
อ่าง
When it appears alone after a base consonant it becomes the vowel ɔː (see plainV).
eg.
พอง
It is also used in combination with other characters to produce additional vowel sounds (see compositeV).
Obsolete characters
These consonants are now regarded as obsolete.
ฃ,ฅ
0E03 is replaced by 0E02.
eg.
ฃวา
0E05 is replaced by 0E04.
eg.
ฅน
Onsets
Consonant letter clusters at the start of a syllable usually represent medial glides, tone markers, or an initial s.
Medial glides
An initial stop may be followed by one of -r-, -l-, or -w-. These sounds can be represented using the normal letters, 0E23, 0E25, and 0E27.
eg.
ประฏัก
ปลา
ควาย
There are no dedicated code points for glides when they are used after an initial consonant, so it is feasible that ปลา could be pronounced pà laː in a different context.
The vocalics can also be used after an initial consonant, and again can create ambiguity for pronunciation
cf.
พฤหัส
พ,ฤ
พฤษภา
พ,ฤ
Tone markers
The silent 0E2Bis used to affect tonal values (see highclass).
eg.
หมา
Similarly, a silent 0E2D is used before an initial 0E22 in 4 words to change the tone of the syllable to low.
eg.
อย่าง
Initial s
The word-initial combination 0E17 0E23 is pronounced s.
eg.
ทราย
Tone & vowel positioning
Tone marks and/or super-/subscript vowel marks are attached to the second consonant.
eg.
เปลี่ยน
กรุงเทพฯ
Pre-base vowel glyphs are placed before the first consonant in the cluster, ie. at the start of the syllable, eg. (where this occurs twice):
eg.
โปรแกรม
Codas
Only the phonemes p, t, k, m, n, ŋ occur at the end of a syllable, however many more consonant letters can appear in final position.
The following consonant letters are pronounced differently in syllable-initial and syllable-final positions.
จ,ช,ศ,ษ,ส,ร,ล,ญ
For example,0E25 in:
ลิง
ตำบล
Consonants at the end of a syllable use ordinary code points.
eg.
ตื่น
This can create some ambiguity, since there is no distinction between the sequence in the previous example and one where น is a new syllable with an inherent vowel.
The one exception is the character that is normally regarded as a vowel but that in fact represents a rhyme: 0E33, which includes the final -m sound.
eg.
ห้องน้ำ
However, a final -m is not always represented using sara am).
eg.
ห้าม
Final+initial consonant folding
A consonant that appears at both the end of one syllable and the beginning of the next may be expressed with a single character, even if the sounds in each phonetic location differ, eg. ส in
พิสดาร
พิ,ส,ดา,ร
Or ล in
จุลทัศน์
จุ,ล,ทั,ศ,น์
Only the following set of consonants behave in this way.
จ,ช,ศ,ษ,ส,ล
Consonant length
The Thai orthography has no special features for dealing with geminated or long consonant sounds, however see also folding.
Consonant sounds mapped to characters
This section maps Thai consonant sounds to common graphemes in the Thai orthography.
The list shows letters used for high, mid, and low class onsets, and for codas.
p
mid class
0E1B
coda
–0E1B
coda
–0E1A
coda
–0E1E
coda
–0E20
pʰ
high class
0E1A
low class
0E1E
low class
0E20
b
mid class
0E1A
t
mid class
0E15
mid class
0E0FRare as an onset.
coda
—0E16
coda
—0E10
coda
—0E2A
coda
—0E28
coda
—0E29
coda
—0E15
coda
—0E14
coda
—0E0F
coda
—0E08
coda
—0E17
coda
—0E18
coda
—0E11
coda
—0E0A
coda
—0E0EAlmost obsolete as a coda.
coda
—0E12Almost obsolete as a coda.
tʰ
high class
0E16
high class
0E10Rare as an onset.
low class
0E17
low class
0E18
low class
0E12
low class
0E11Rare as an onset.
t͡ɕ
mid class
0E08
t͡ɕʰ
high class
0E09
low class
0E0A
low class
0E0COnly used in a few words.
d
mid class
0E14
mid class
0E0E
k
mid class
0E01
coda
—0E02
coda
—0E01
coda
—0E04
coda
—0E06
kʰ
high class
0E02
low class
0E04
low class
0E06
f
high class
0E1D
low class
0E1F
s
high class
0E28
high class
0E29Less common. Mostly in foriegn words.
high class
0E2ALess common. Mostly in foriegn words.
high class
0E17 0E23
low class
0E0B
h
high class
0E2B
low class
0E2EOnly used in a few words.
m
high class
0E2B 0E21
low class
0E21
coda
—0E21
n
high class
0E2B 0E19
low class
0E13Mostly used in coda.
low class
0E19Rare as onset.
coda
—0E23
coda
—0E25
coda
—0E2C
coda
—0E0D
coda
—0E13
coda
—0E19
ŋ
high class
0E2B 0E07
low class
0E07
coda
—0E07
w
high class
0E2B 0E27
low class
0E27
r
high class
0E2B 0E23
low class
0E23
ri
vocalic
0E24
rɯ
vocalic
0E24
rɯː
vocalic
0E24 0E32
l
high class
0E2B 0E25
low class
0E25
low class
0E2CNow almost obsolete.
j
high class
0E2B 0E22
high class
0E2B 0E0D
low class
0E22
low class
0E0D
Other features
Cancellation mark
0E4C can be used above a consonant or syllable when it is not pronounced (usually at the end of a syllable).
Click on the words to see the pronunciation more clearly.
eg.
รถเมล์
ร,ถ,เ,ม,ล์
ศักดิ์สิทธิ์
ศั,ก,ดิ์,สิ,ท,ธิ์
It is often used for foreign loan words.
eg.
คอมพิวเตอร์
โปสการ์ด
สแตมป์
Encoding choices
This section offers advice about characters or character sequences to avoid, and what to use instead. It takes into account the relevance of Unicode Normalisation Form D (NFD) and Unicode Normalisation Form C (NFC)..
Although usage is recommended here, content authors may well be unaware of such recommendations. Therefore, applications should look out for the non-recommended approach and treat it the same as the recommended approach wherever possible.
SARA AE
In complex scripts, visually similar or identical glyph patterns can often be made from a sequence of code points rather than the single code point that Unicode provides. These are not made the same by normalisation, and they are not semantically equivalent. These inappropriate sequences should be avoided because they will cause the meaning of the text to change; searches, matching and other aspects of the text will fail to be understood by the application or the font.
Only one such is listed in the table below, The single code point on the left should be used, and not the sequence on the right. In some cases, fonts will indicate that there is a problem by forcing the appearance of a dotted circle or otherwise failing to render the text correctly, but this may not always be the case.
Use
Do not use
แ
เเ
Nikhahit
The combination of nikahit and sara aa is normally written with the precomposed character in the Thai block. It is possible to use 2 code points to create something that may visually look identical (and is in fact used during justification), but the single character and the sequence are not converted to each other during normalisation; therefore, the text will be read as different by normalisation-based matching algorithms.
Recommended
Not recommended
ำ
ํา
Code point sequences
As already mentioned, Thai is visually encoded so pre-base glyphs are associated with ordinary spacing characters, and these need to be typed and stored in visual order relative to the base consonant(s) in a syllable. If the syllable begins with a consonant cluster such as pr, the pre-base code points must be typed before the p, even though they are pronounced after the r.
Tone marks should be typed and stored after any combining vowel mark. Fonts will typically indicate visually that the order is incorrect because the tone mark will appear below the vowel mark if they are the wrong way around.
Numbers, dates, currency, etc.
Thai has a set of decimal digits, that are used regularly.
๐,๑,๒,๓,๔,๕,๖,๗,๘,๙
The CLDR standard-decimal pattern is #,##,##0.###. The standard-percent pattern is #,##,##0%.cldr
Currency
The currency symbol for baht is encoded in the Unicode Thai block.
฿
The CLDR standard format for currency is ¤#,##0.00.cldr
Dates
Thailand commonly uses the Buddhist Era calendar. The Gregorian year 2000 was 2543 in the Buddhist calendar.
Buddhist era date at the top of a Thai newspaper: 15 March 1995.
In fig_thai_date the abbreviation พ.ศ.p̱ʰ.ś. stands for Buddhist era.
This section brings together information about the following topics:
font/writing styles;
cursive text;
context-based shaping;
context-based positioning;
letterform slopes, weights, & italics;
case & other character transforms.
Modern type styles often omit the loops found in more traditional typefaces. See an article that explores this in depth.
Loopless is considered to be more contemporary and modern, and is mainly used for advertising and titling. The distinction doesn’t necessarily map to that of serif vs sans – Noto, for example, provides both serif and sans Thai font faces, but they both have loops. On the other hand, Neue Frutiger Thai offers traditional (looped) and modern (loopless) alternatives as part of the same font family (each with both regular, italic and bold substyles).
The Silom font uses the traditional looped glyphs.The Sukhumvit Set font uses modern unlooped glyphs.
Context-based shaping & positioning
Thai has no stacking or conjunct behaviour, but the following are a few selected examples of contextual shaping and positioning.
Most of the combining characters in Thai are used for vowel signs and tone marks. Combining characters need to be placed in different positions, according to the visual context. The example below shows the same tone character displayed at different heights, according to what falls beneath it.
The same tone mark displayed at different heights.
Thai regularly combines multiple combining characters above a base consonant. There are two examples in the text below, both of which show a base character with a vowel sign and then a tone mark on top.
Multiple diacritics (vowel sign + tone mark) attached to the same base character.
Although Thai has very little in the way of shaping, fig_shaping shows a number of small glyph adaptations that occur in some fonts (here, Noto Serif Thai) when certain tall or deep consonant letters have vowel marks attached. The 2 examples on the left show a slight reduction in the downward extent of the consonant glyph; in the middle 2 examples the part of the consonant glyph that lies below the baseline is removed altogether and replaced by the vowel sign; and in the right-most example, the height of the consonant glyph is reduced when a vowel sign appears above it.
Shaping changes in the Noto Serif Thai font. Each example shows an unadorned consonant glyph on the left, and on the right a shaped version when a vowel sign is attached.
Letterform slopes, weights, & italics
Ben Mitchell describes how italicisation is used for meta text and to convey the ‘about’ voice, rather than for emphasis or names of things (for which bold is used).
Italicisation tends to be applied to whole paragraphs or groups of paragraphs, for such things as picture captions, bylines, and other labels, commentaries, summaries such as standfirsts in magazines or news stories, and signposting. It is also regularly used for direct speech between quote marks.
Observation: Thai newspapers appear to use italic text for captions and by-lines. There is no evidence of the use of inline italicisation, but there is inline bolding.
Typographic units
Word boundaries
Thai doesn't separate words in a phrase.
Spaces are used in Thai as phrase separators, but Thai doesn't separate words in a phrase using visible spaces.
There is, however, a concept of words in the text. For example, lines are supposed to be broken at word boundaries.
Word boundaries occur where the vertical lines appear, though they are not marked by the script.
Word boundary detection
The main difficulty arises when dealing with compound words. It can often be difficult to decide whether a given string of syllables represents multiple words or a single compound word.
Alternative line break opportunities for Thai text using compound nouns.
The variation may be related to the operation being performed on the text (eg. line breaking in narrow newsprint columns, vs. double-click selection, vs. cursor movement, etc.), or it may just be down to personal preference,
The difference may also be contextually dependent. Wirote Aroonmanakun describes how
คนขับรถ
should be viewed as a single word in the context
คนขับรถนั่งคอยอยู่ในรถ
whereas in the phrase
คนขับรถผ่านแยกนี้ไม่มากนัก
it would be viewed as 3 words, referring to anyone who is driving.at
Proper names, which are composed from multiple words, are also problematic, especially because there are no capital letters to distinguish them from other pieces of text.g2455§#issuecomment-375162188
ZWSP & WJ
In order to manually fine-tune word-boundary detection, the invisible character 200B (ZWSP) can be used to create breaks.u§625
To prevent a break between syllables, 2060 (WJ) can be used.
It is also important to bear in mind that Thai may be used to write various languages, in particular minority languages for which different dictionaries are needed. Since such dictionaries may not available in a given browser or other application, there is a tendency to use ZWSP in order to compensate.
Large-scale manual entry of ZWSP and WJ has potential downsides because the user cannot see them; this leads to problems with ZWSP being inserted in the wrong position, or multiple times. However, these don't set a state, so it doesn't create major issues. It would be useful, however, if an editor showed the location of these characters.
Care should also be taken when trying to match text, eg. for searching in a page. WJ should be ignored. ZWSP may or may not be ignored, depending on whether word boundaries are significant for the search.
Parsing syllables
Automatically adding spaces (zero-width or other) around Thai syllables is problematic because syllable-final consonants are not easy to identify. Thai segmentation may have to deal with ambiguous situations. Take for example the word
ถนน
Because syllable-final sounds are ordinary letters, with no special indication, this could be parsed as ta.non, ton.na, or even ta.na.na, and indeed some words are written the same but pronounced differently, eg.
นม
Similarly, because medial consonants are written with normal characters, there is a possibile ambiguity about whether a sequence contains an inherent vowel, eg.
กรี
Graphemes
Non-combining Thai vowel characters are treated as independent grapheme clusters. Only combining characters are grouped together with their base into a cluster.
Grapheme clusters
Base SARA_AM? Combining_mark*
Combining_mark may include zero or more of the following types of character, grouped by labels that correspond to Unicode Indic syllabic category values.
Dependent vowels [9] (see plainV) Thai has many composite vowels that are made of combinations of ordinary letter characters and combining marks clustered around a base, but in the modern Thai language only one of these dependent vowels is used per base. (Other languages may use more than one. The letter characters are ordinary spacing characters, that are manually positioned in the text stream.)
Tone marks [4] (see tones) Tone marks should be typed and stored immediately after a dependent vowel, if there is one, and immediately after the base otherwise.
Consonant killer (májtʰantʰákʰâːt) [1] (see novowel) Used after other elements in the grapheme cluster to indicate cancelling of a consonant or syllable.
The spacing letters used for vowel signs are all individual grapheme clusters, with the exception of ำ (see nikhahit), which has the general category of Letter, but it is treated like a combining mark during segmentation.
The following examples show a variety of grapheme clusters:
Click on the text version of these words to see more detail about the composition.
ได้กลิ่น
ห้องน้ำ
โปรแกรม
ศักดิ์สิทธิ์
The grapheme cluster boundaries are convenient for justification algorithms, which insert equal amounts of space between non-combining letters, including between non-combining vowel sign components and their consonants (see justification).
One exception is the aforementioned ำ, which is split across 2 typographic units for the purpose of justification (see inter_character_spacing).
Browser behaviour
Test in your browser.The words test units that equate to grapheme clusters only, and others that include conjuncts. First, the text is displayed in a contenteditable paragraph, then in a textarea. Results are reported for Gecko (Firefox), Blink (Chrome), and WebKit (Safari) on a Mac.
ได้กลิ่นห้องน้ำโปรแกรมศักดิ์สิทธิ์
The first word in the sample text contains 2060 and the first and third words are followed by 200B.
Cursor movement.Move the cursor through the text.
Gecko and WebKit browsers step through the text using grapheme clusters with one exception: they take 2 steps to get through ำ. Blink steps through all words using standard grapheme clusters. In all cases, the WJ and ZWSP are skipped separately; the cursor doesn't appear to move as the arrow key is pressed for Gecko and Blink browsers, but WebKit pauses halfway through the preceding character when it encounters ZWSP.
Selection.Place the cursor next to a character and hold down shift while pressing an arrow key.
The behaviour is the same as for cursor movement.
Deletion. Forward deletion works in the same way as cursor movement. The backspace key deletes code point by code point, for all browsers.
Line-break.See this test. The CSS sets the value of the line-break property to anywhere. Change the size of the box to slowly move the line break point.
Gecko, WebKit and Blink browsers all wrap on grapheme cluster boundaries.
Punctuation & inline features
Phrase & section boundaries
Thai uses space as a phrase marker, rather than to delimit words, often in places where English text would use commas or periods. Latin-based punctuation such as comma, period, and colon are also used in text, particularly in conjunction with Latin letters or in formatting numbers, addresses, and so forth.
phrase
0020
,
:
sentence
0020
.
?
!
section
๚
chapter/document
๛
๚ is used to mark the end of a long segment of text. It can be combined as follows to mark a larger segment of text; typically this usage can be seen at the end of a verse in poetry.u§625
๚ะ
๛ marks the end of a chapter or document, where it always follows the ๚ะ combination.u§625
Dashes include
‐,–,—
Space widths
It is possible to find two different sizes of space in Thai: large spaces between sentences, and small spaces in other places (eg. for separating sub clauses). The width of the small space is the same as ก, and the larger space is double that size.GitHub§https://github.com/w3c/sealreq/issues/46
Most people no longer make this distinction, but some may want to. It also occurs in other Southeast Asian scripts.
An example of how multiple width spacing may look.
Observation: It is currently not clear how to achieve this on the Web, where multiple space characters are collapsed to a single space by default. One suggestion is to use [U+2003 EM SPACE], but that is not well supported by Thai fonts, and doesn't expand during justification. See GitHub§https://github.com/w3c/sealreq/issues/46 for a discussion.
Bracketed text
Thai commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Quotations & citations
Thai texts use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
“
”
nested
‘
’
Abbreviation, ellipsis & repetition
Repetition
ๆ is used to mark repetition of preceding letters.u§625 It is typically preceded and followed by a space.
eg.
ทุกวัน ๆ
However, some publishers prefer to publish without a leading space,g19§#issuecomment-579378205
ie.
ทุกวันๆ
This character shouldn't be wrapped to the beginning of a new line on its own, and should be kept not far from the preceding text that it duplicates during justification.g19§#issuecomment-579378205
Abbreviation
ฯ is used to indicate elision or abbreviation of letters; it is viewed as a kind of letter, however, and is used with considerable frequency because of its appearance in such words as the Thai name for Bangkok.
กรุงเทพฯ
Which is short for
กรุงเทพมหานคร
It is followed by a space.
Ellipsis
Paiyannoi is also used in the combination ฯลฯ to create a construct called paiyanyai , which means “et cetera, and so forth.”u§625
Some abbreviations are written using a full stop.
eg.
สนง.ตปท.sṉŋ̱.t̯p̯ṯʰ.Office of the Royal Thai Police
0E4E is an ancient punctuation mark used to mark clusters, such as in พ๎ราห๎มณp̱ʰ๎ṟāh๎m̱ṇ̱pʰraːmǒn
Line & paragraph layout
Line breaking & hyphenation
Even where Thai doesn't indicate word boundaries, when Thai text is wrapped at the end of a line it should break at word boundaries.
As the width of a browser window changes, the text in fig_thai_wrap should break at the points shown if the browser supports Thai wrapping:
Break points detected in a sequence of Thai characters by an automatic word segmenter.
Because Thai doesn't separate words, applications typically look up word boundaries in a dictionary, however, such lookup doesn't always produce the needed result, especially when dealing with compound words and proper names (see word). For more details, see wordBoundary.
To counteract these deficiencies, authors may use 200B and 2060 (see zwsp).
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for characters used in modern Thai. Context may affect the behaviour of some of these and other characters.
Click on the Thai characters to show what they are.
“ ‘ ( should not be the last character on a line
” ’ ) ? ! ๚ ๛ % should not begin a new line
฿ should be kept with any number, even if separated by a space or parenthesis.
The repetition character, ๆ is always preceded by space, however it should not wrap to the next line on its own.Github§https://github.com/w3c/sealreq/issues/45
Text alignment & justification
Justification in Thai primarily adjusts the blank spaces between phrases, rather than expanding the text between words or syllables. The fact that lines break at word boundaries helps reduce the size of the gaps produced.
Thai may also make certain adjustments to inter-character spacing. The character-based spacing is most common in narrow columns, such as newsprint, where there is no space except at the end of a line.
Any 200B (ZWSP) is used to separate words is ignored during justification. Justification proceeds as if it wasn't there.u§625
Inter-character spacing
The justification in fig_justification_intercharacter_spacing shows equal spacing across a phrase where there are no space characters to stretch. Note how the equal spacing separates pre-base and post-base vowel sign components from their consonants by the same amount as consonants are separated from each other; they are not kept together with the base consonant they modify.
A line with no spaces applies inter-character spacing to justify the text.
This kind of spacing requires a special behaviour for ำ. The small circle is kept with the preceding consonant, and space is added before the spacing part of the vowel, as shown in fig_am_spacing.
Sara AM before (left) and after (right) inter-character spacing has been applied.
(To facilitate this, applications tend to convert ำ to the sequence ํา before stretching. Some care has to also be taken to correctly order the superscript glyphs, since in memory the tone mark precedes the nikhahit. The nikhahit character is not otherwise used for modern Thai.)
Paragraph indentation
Thai does indent the initial line of a paragraph.
Indentations at paragraph start in a Thai newspaper.
Baselines, line height, etc.
Thai uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
Thai places vowel and tone marks above base characters, one above the other, and can also add combining characters below the line. The complexity of these marks means that the vertical resolution needed for clearly readable Thai text is higher than for English, or most Latin text. In addition, Thai tends to adds more interline spacing than Latin text does.
To give an approximate idea, fig_baselines compares Latin and Thai glyphs from Noto fonts. The basic height of Thai letters is typically around the Latin x-height, however extenders and combining marks reach well beyond the Latin ascenders and descenders, creating a need for larger line spacing. In other fonts, the basic height of the Thai letters tends to be between the Latin x-height and cap-height, and the overall height of the Thai line is therefore greater.GitHub§https://github.com/w3c/sealreq/issues/55#issuecomment-1356183447 See for example the Angsana New and FreesiaUPC font samples below.
Font metrics for Latin text compared with Thai glyphs in the Noto Serif Thai (top) and Noto Sans Thai (bottom) fonts.
fig_baselines_other shows similar comparisons for the Thonburi and Angsana New fonts.
Latin font metrics compared with Thai glyphs in the FreesiaUPC (top) and Angasana New (bottom) fonts.
Counters, lists, etc.
You can experiment with counter styles using the Counter styles converter. Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
The modern Thai orthography uses numeric and alphabetic styles.
Bullets
๏ is the Thai bullet, which is used to mark items in lists or appears at the beginning of a verse, sentence, paragraph, or other textual segment.u§625
Numeric
The thai numeric style is decimal-based and uses the digits shown below.
๐,๑,๒,๓,๔,๕,๖,๗,๘,๙
eg.
๑,๒,๓,๔,๑๑,๒๒,๓๓,๔๔,๑๑๑,๒๒๒,๓๓๓,๔๔๔
Alphabetic
The thai-alphabetic style uses the letters shown below.
It is possible to find the first letter in a paragraph styled so that it is larger and sits alongside several lines of the continuing paragraph text.
Observation: All combining characters are included in the selections shown in fig_drop_caps.
Any punctuation such as opening quotes and opening parentheses should also be included in the initial styling. ?
Two example paragraphs showing dropped highlighted initials with combining characters.
Observation: In the figures shown, the alphabetic baseline of the highlighted letter falls slightly below the bottom of the row that determines the size of the highlighted letter. It's not clear whether that's a general trend, or just related to this specific publication.
Observation: In fig_drop_caps_2, the selection picks out only แ from the syllable แฉ.
Another example paragraph, showing a pre-base vowel sign alone as a highlighted initial.