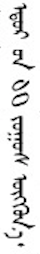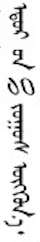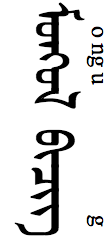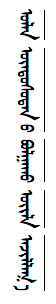This page brings together basic information about the Mongolian (Hudum) script and its use for the Mongolian language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Mongolian using Unicode.
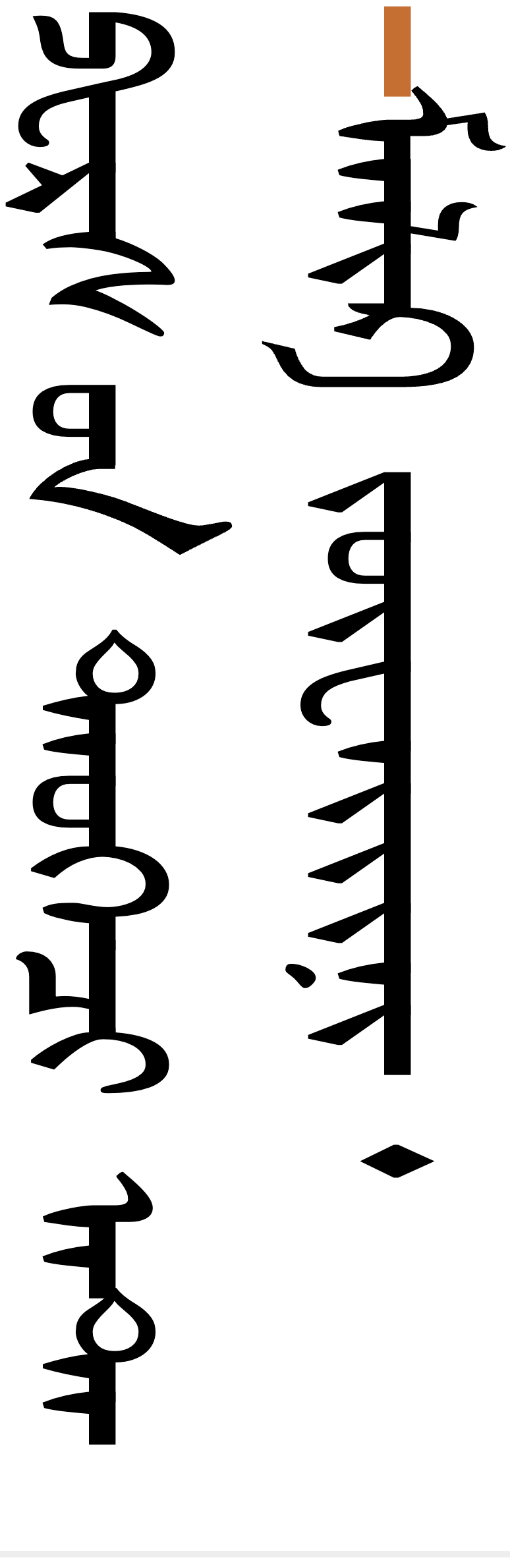
It can be quite difficult at times for novices to identify characters in a string of cursive Mongolian text. Clicking on the orange-coloured examples below can help a lot by opening a panel which matches the code points and sounds to the visible graphemes. In the panel, the word is split into segments approximating grapheme clusters; above it is a transliteration; below is the pronunciation in IPA.
The Mongolian script is used for writing the Mongolian language. In the Mongolian People's Republic (Outer Mongolia), the traditional script was replaced by a Cyrillic orthography since the early 1940s, but revived in the 1990s, so that both scripts are now used in tandem. The script is also used within the Inner Mongolia Autonomous Region of the People’s Republic of China and elsewhere in China.
The traditional writing for Mongolian is known as Hudum Mongol bichig, and was adapted from the Old Uighur alphabet during the reign of Genghis Khan in the 13th century.
There are four other scripts which are derived from and closely related to Mongolian. These are the Galik, Todo (or "clear script"), Manchu and Sibe scripts.
Unicode 17 has 2 dedicated Traditional Mongolian blocks, comprising 171 characters.
The Mongolian script is an alphabet, ie. all vowels are written explicitly, alongside consonants; there is no inherent vowel in a consonant (abugidas), certain vowels are not systematically dropped (abjads), and consonant and vowel are not combined in the same character (syllabaries).
Modern Mongolian can be written using a subset of the letters available in the Mongolian Unicode block. The remainder are used for writing Todo, Sibe, and Manchu, or for writing foriegn words, especially in Tibetan and Sanskrit.
Vowels Vowels are written using 8 vowel letters, including one for foreign sounds.
Mongolian has separate code points for each sound in Mongolian, but many of these look indistinguishable from each other when rendered. This creates difficulties for novices to reproduce Mongolian text without access to the source..
Vowel reduction is a significant feature of Mongolian. Non-initial short vowels are reduced to vestiges or to zero, and non-initial long vowels in the orthography are reduced to short vowel length.
Vowel harmony is another key feature, grouping vowels in a way that indicates a front or back position for the tongue root (ATR).
Zero-onset vowels are written using ordinary vowel letters and no special arrangements.
Vowel absence Since this is an alphabet, vowel absence in consonant clusters or after codas is marked simply by an absence of vowel letters. There is no special shaping or mark to indicate a consonant cluster.
Layout Mongolian text runs top to bottom in vertical lines and (unusually) the lines flow left to right. Words are separated by spaces, but also contain narrow spaces that precede suffixes and may produce shaping differences to the surrounding letters. These are part of the word, and the parts on either side should not be separated. There is no case distinction.
The script is cursive, ie. letters in a word are joined. All letters join both on the left and right.
Punctuation uses a mixture of ASCII and native code points, and some fullwidth characters.
Character index
Letters
Show
Basic consonants
ᠫ,ᠪ,ᠲ,ᠳ,ᠴ,ᠵ,ᠬ,ᠰ,ᠱ,ᠭ,ᠨ,ᠩ,ᠮ,ᠯ,ᠶ,ᠷ
Extended consonants
ᠸ,ᠹ,ᠺ,ᠻ,ᠼ,ᠽ,ᠾ,ᠿ,ᡀ,ᡁ,ᡂ
Vowels
ᠢ,ᠦ,ᠤ,ᠡ,ᠧ,ᠥ,ᠣ,ᠠ
Combining marks
Show
Variation selectors
᠋,᠌,᠍,᠏
Other
ᢅ,ᢆ,ᢩ
Numbers
Show᠐,᠑,᠒,᠓,᠔,᠕,᠖,᠗,᠘,᠙
Punctuation
Show᠂,᠄,᠃,?,!,(,),(,),〈,〉,«,»,《,》,〔,〕,᠊,᠁,᠆
Separator & other
Show, ,
To be investigated
%,;,[,],ʼ,͏,᠀,᠅,‑,–,—,‘,’,“,”,‰,‹,›,⁈,⁉,、,。
Items to show in lists
Phonology
These are the sounds of Khalkha Mongolian.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Plain vowels
Diphthongs
A significant feature of Mongolian phonology is that vowel sounds are divided into front (+ATR), back (-ATR), and neutral groups (see harmony). The front and back distinction has to do with the position of the tongue root (ATR means Advanced Tongue Root). The phonology is more complicated, and sounds are somewhat more fluid than described here. See the sources for more detailed information.
In non-stressed positions, most vowels fall back to ə or are elided. See diglossia.
Consonant sounds
labial
dental
alveolar
post-
alveolar
palatal
velar
uvular
glottal
stops
p
t
ɡ
ɢ
aspirated
pʰ
tʰ
kʰ
palatalised
pʲ
tʲ
ɡʲ
aspirated & palatalised
pʲʰ
tʲʰ
kʲʰ
affricates
t͡s
t͡ʃ
aspirated
t͡sʰ
t͡ʃʰ
fricatives
f
s ɮ
ʃ
x
palatalised
ɮʲ
xʲ
nasals
m
n
ŋ
palatalised
mʲ
nʲ
approximants
w
j
palatalised
wʲ
j
Some phonological transcriptions use t and tʰ where others use d and t for the same sounds, respectively. Similar contrasts are applied to the bilabial and affricate pairs in the repertoire (but not to the k/g pairing). Here we use the former, because that is what Wiktionary uses for the IPA transcriptions included in the examples.
Palatalisation appears to be restricted to words containing -ATR (back) vowelswl§#Consonants.
Tone
Mongolian is not a tonal language.
Structure
Prefixes and suffixes
The basic unit of text is a word, however words can contain prefixes and suffixes. Some of the suffixes are separated from the root of the word by a small gap, but they are still considered to be part of the word. See suffixes and mvs for more details.
Vowel harmony
Vowel harmony is an important aspect of the Mongolian language. Vowels are classed under one of the following 3 types:
A native word that begins with a -ATR vowel continues with only -ATR and/or neutral vowels. A word beginning with +ATR vowels continues with only +ATR and/or neutral vowels. Foreign loan words don't follow this pattern, and compound words (especially place names) may be made up of two words of different type.
The -ATR vowels are:
ᠠ,ᠣ,ᠤ
The +ATR vowels are:
ᠡ,ᠥ,ᠦ
The following vowel is neutral, and can appear in words with either +ATR or -ATR vowels.
ᠢ
Grammatical suffixes also differ according to whether the vowels are +ATR or -ATR types.
Vowels
Neutral
ᠢ,ᠡ,ᠧ
ATR+
ᠡ,ᠧ,ᠥ,ᠥ,ᠦ
ATR-
ᠠ,ᠣ,ᠤ
These are nominal pronunciations that don't take into account vowel harmony or vowel reduction. Also, nominal shapes are shown; in practise, the shape will vary according to the joining context.
Post-consonant vowels
Vowels are written using 8 vowel letters, including one for foreign sounds.
Unicode encodes separate characters for the different sounds of the Mongolian language, regardless of whether the glyph shapes used are identical (see encodingprinciples). The ambiguity created by vowel letters that look the same makes it very difficult for people who don't know the language to create or read Hudum text.
Special rendering rules apply to some word-final vowel sounds that, in writing, are separated from the rest of the word by a small gap (see mvs).
Vowel length is phonemically distinctive (see vlength).
Plain vowels
The basic vowel sounds of the Mongolian language are written using the following letters.
ᠢ,ᠦ,ᠤ,ᠡ,ᠧ,ᠥ,ᠣ,ᠠ
The list shows canonical pronunciations for these vowels. In fact, in non-stressed positions most vowels fall back to ə or are omitted. See diglossia.
eg.
ᠠᠶᠢᠮᠠᠭ
ᠠᠶᠢ,ᠮ,ᠠ,ᠭ
ᠪᠦᠢᠯᠡᠰᠦ
ᠪ,ᠦ,ᠢ,ᠯ,ᠡ,ᠰ,ᠦ
ᠧ is used for foreign words.
As previously mentioned, vowel harmony is an important part of the orthography for the Mongolian language, and most of these vowels consist of contrasting pairs.
In actual use, these vowel letters are shaped into joining forms that differ significantly from the nominal shapes shown in the box above. Although joining forms for a single letter can differ significantly, many of the joining forms are identical to those of another letter, which creates difficulty in reading Mongolian text for novices. See encodingprinciples.
Diphthongs
Mongolian diphthongs are written using a combination of basic letters.
eg.
ᠲᠣᠯᠤᠭᠠᠢ
ᠨᠠᠢ᠍ᠮᠠ
Vowel length
Length is phonemically contrastive. Long vowels are commonly indicated by a sequence of letters, such as ᠠᠭᠠ in the example just below.
cf.
ᠴᠠᠰᠤ
ᠴ,ᠠ,ᠰ,ᠤ
ᠴᠠᠭᠠᠰᠤ
ᠴ,ᠠᠭᠠ,ᠰ,ᠤ
The pattern used for long vowels shown just above is common, and works with various combinations of characters. Examples follow; click on them to see the underlying components.
eg.
ᠪᠡᠭᠡᠵᠢᠩ
ᠥᠭᠡᠬᠦ
ᠤᠤᠭᠤᠬᠤ
Sometimes the long vowel is indicated by simply doubling the vowel letter; other times, there is no indication that the vowel is long. Note also that vowels spelled as long in unstressed locations retain their vowel quality (ie. they aren't reduced to a schwa), but they are shortened (see the first example below).
Unicode encodes separate characters for the different sounds of the Mongolian language, regardless of whether the glyph shapes used are identical.
This is particularly, though not exclusively, relevant for vowel letters. For example, as shown in fig_o_u_glyphs, the glyph shapes for the 2 sounds ɔ and ʊ are identical, as are those for o and u. The two pairs only differ in shape in isolated and initial forms.
Initial, medial and final forms for characters representing ɔ, ʊ, o, and u, respectively.
The following table shows all of the standard glyph shapes used for joining forms of Mongolian vowels. The order, from top to bottom, is isolate, initial, medial, final. It also shows special forms following an MVS gap for e and a. However, other shapes occur in certain grammatical or other contexts, and these can be achieved using special shaping rules or variation selectors (see context).
Neutral
ᠢ ᠢ ᠢ ᠢ,ᠧ ᠧ ᠧ ᠧ
ATR+
ᠦ ᠦ ᠦ ᠦ,ᠥ ᠥ ᠥ ᠥ,ᠡ ᠡ ᠡ ᠡᠡ
ATR-
ᠤ ᠤ ᠤ ᠤ,ᠣ ᠣ ᠣ ᠣ,ᠠ ᠠ ᠠ ᠠᠠ
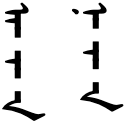
Identical glyphs for different sounds occur across other pairings also. For example, the medial and final shapes for a and n are identical.
Initial, medial and final forms for characters representing a, and n, respectively.
The Unicode Standard provides the following examples of word pairs that cannot be distinguished visually.u§530
These 2 word pairs are confusable in Mongolian. See below for the composition.
ᠠᠳᠠ
ᠠ,ᠳ,ᠠ
ᠡᠨᠳᠡ
ᠡ,ᠨ,ᠳ,ᠡ
ᠣᠷᠳᠤ
ᠣ,ᠷ,ᠳ,ᠤ
ᠤᠷᠲᠤ
ᠤ,ᠷ,ᠲ,ᠤ
The result of this encoding method is that it is impossible to accurately copy Mongolian text from a visual source unless you speak the language well enough to recognise the phonetics of the words involved. It also leads to mistakes when Mongolian speakers type text.
Spelling vs. pronunciation
Mongolian words can be written in a way that looks significantly different from the actual pronunciation. Two factors, in particular, play a role here: (1) vowel stress and reduction, and (2) traditional vs. modern pronunciations.
Click on the following examples in order to see the sequence of characters.
Vowel reduction is a significant feature of Mongolian pronunciation. Non-initial short vowels are reduced to vestiges or to zero, and non-initial long vowels in the orthography are reduced to short vowel length.
eg.
ᠴᠠᠰᠤ
ᠴᠢᠬᠢ
Word stress always falls on the first syllable of a Mongolian word, unless there are long vowels or diphthongs later in the word, in which case those take the stress.
The first vowel in a word is never reduced, even if unstressed, eg.
eg.
ᠴᠠᠭᠳᠠᠭᠠ
ᠤᠯᠠᠭᠠᠨ
If there is more than one long vowel, the first long vowel is long, and the second is short, but not otherwise reduced, eg.
eg.
ᠤᠯᠠᠭᠠᠨᠪᠠᠭᠠᠲᠤᠷ
Different rules apply to foreign loan words, eg.
eg.
ᠠᠦ᠋ᠲ᠋ᠣᠪᠦ᠋ᠰ
ᠮᠠᠱᠢᠨ
Written Mongolian words also use traditional spellings that may not correspond closely to modern pronunciations. For example, the following word is spelled pajarlalʊɢa, but pronounced pajərɮa.
eg.
ᠪᠠᠶᠠᠷᠯᠠᠯᠤᠭᠠ
It is particularly common to drop the sound of ᠭ and convert it and the surrounding vowels to a single long vowel sound. For example, click on the following words to see the elided characters:
eg.
ᠬᠠᠭᠠᠨ
ᠤᠤᠭᠤᠬᠤ
Sometimes vowels appear to move to places they are not in the orthography during the reduction process. The following word is spelled uʤəgulxu, whereas the modern pronunciation is ut͡suːləx.
eg.
ᠤᠵᠡᠭᠦᠯᠬᠦ
For non-stressed, non-initial syllables, some sources group consonants into those which need to be preceded or followed by a vowel:
ᠮ,ᠨ,ᠭ,ᠯ,ᠪ,ᠸ,ᠷ
And those which don't:
ᠳ,ᠵ,ᠽ,ᠰ,ᠲ,ᠬ,ᠼ,ᠴ,ᠱ
However, Mongolian pronunciation can still appear to be very different from the written text because unstressed vowels are typically reduced or omitted when a word is pronounced, eg.
Final vowel separation
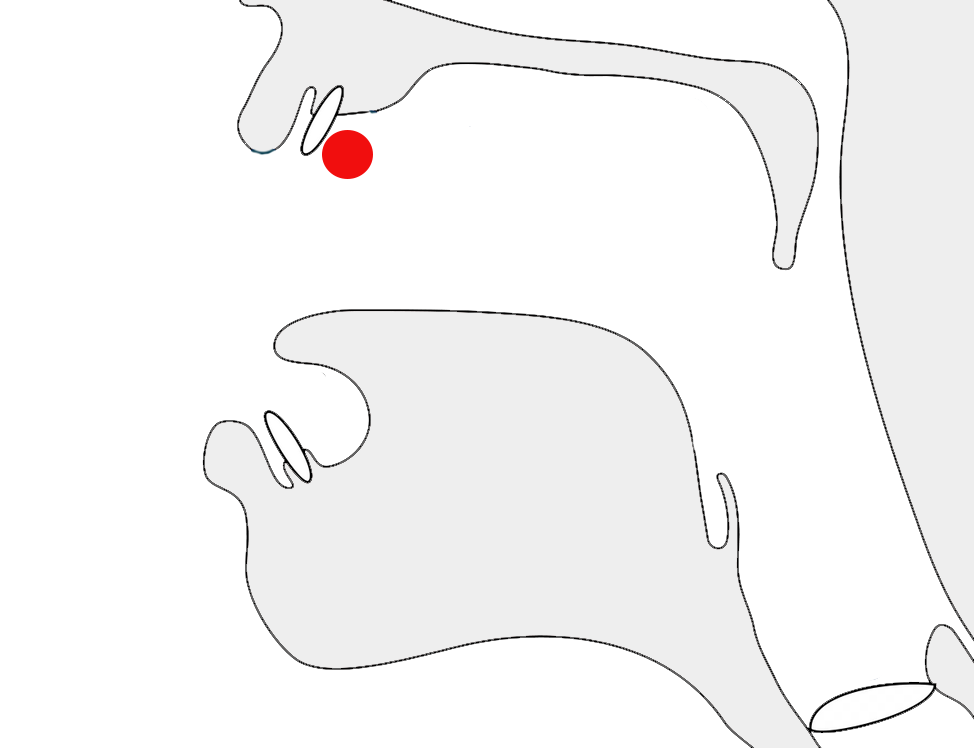
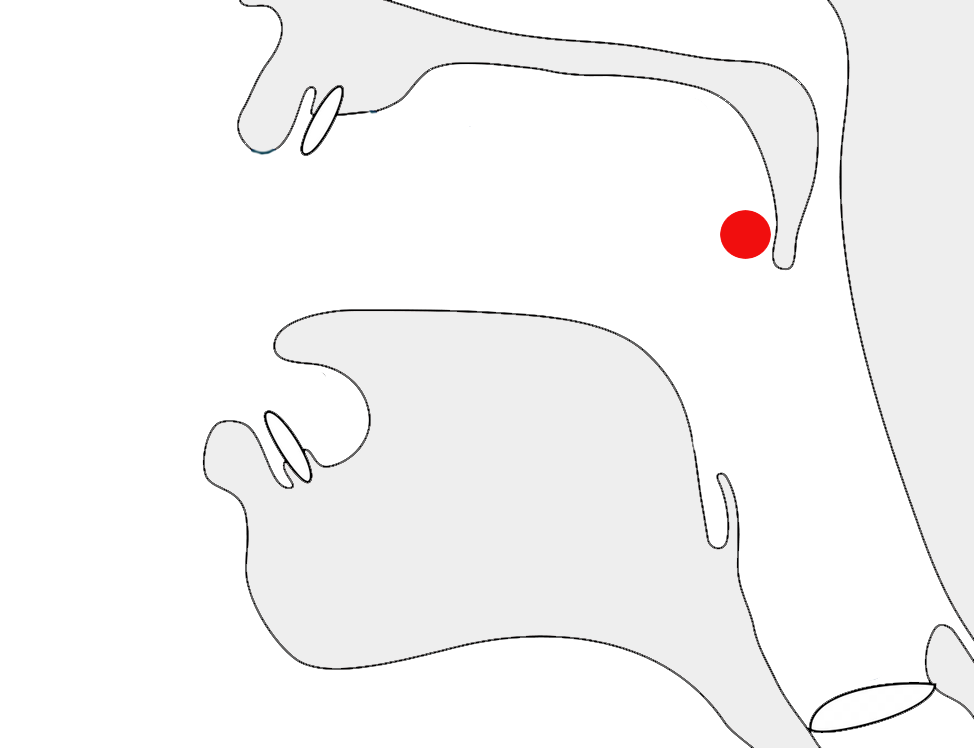
In some Mongolian words that end with ᠠ or ᠡ a special 'forward tail' glyph shape is used, and the glyph is slightly separated from the rest of the word (see fig_mvs). The shape of the previous letter may also change, when this occurs, depending on the letter and sometimes whether this is a traditional or modern orthography. Whether this special shaping is applied or not depends on the word – there are no rules to determine when to apply it. In fig_mvs the n before the MVS is written using a final glyph, but the normal glyph, ᠨ, becomes ᠨ.
The final letter is not a suffix, but is an integral part of the word, and line breaking, word selection, etc. should not split the start of the word from the last letter, even though there is a gap.
To achieve this effect in Unicode, use 180E (MVS) immediately before the last letter.
The same sequence of characters with MVS before the last letter (left), and without (right). See the composition just below.
cf.
ᠬᠠᠨᠠ
ᠬ,ᠠ,ᠨ,,ᠠ
ᠬᠠᠨᠠ
ᠬ,ᠠ,ᠨ,ᠠ
The MVS is also used to create a small gap before suffixes.
Not used for Todo, Manchu or Sibe.
Zero-onset vowels
Zero-onset vowels are written using ordinary vowel letters and no special arrangements.
eg.
ᠠᠪᠬᠤ
ᠡᠨᠳᠡ
ᠤᠰᠤ
However, what appear to be word-initial sounds may not be the initial characters in a word.
eg.
ᠠᠭᠤᠯᠠ
ᠠ,ᠭ,ᠤ,ᠯ,ᠠ
Vowel characters for other languages
In addition to the set of Mongolian vowels, the Mongolian block also includes additional vowel characters for use with Todo, Sibe, Manchu and Ali Gali vowels.
Todo
ᡃ,ᡄ,ᡅ,ᡆ,ᡇ,ᡈ,ᡉ
Sibe
ᡝ,ᡞ,ᡟ,ᡠ,ᡡ
Manchu
ᡳ
Ali gali
ᢇ,ᢈ
Vowel sounds to characters
This section maps Mongolian vowel sounds to common graphemes in the Traditional Mongolian orthography.
Plain vowels
i
ᠢ
ᠢᠳᠡᠬᠦ
ᠡ
ᠡᠬᠡ
ᠧ Used for foreign loanwords.
ᠾᠧᠵᠢᠩ
ʊ
ᠤ
ᠤᠷᠲᠤ
u
ᠦ
ᠦᠵᠡᠬᠦ
e
ᠡ
ᠡᠮᠡᠭᠲᠡᠢ
ᠧ Used for foreign loan words.
ᠾᠧᠵᠢᠩ
ɵ
ᠥ
ᠥᠨᠳᠡᠭᠡ
o
ᠥ
ᠥᠭᠬᠦ
ə
Several vowels are reduced to this sound when not accented.
ᠭᠡᠷᠡᠯᠲᠦᠨᠡ
ɔ
ᠣ
ᠣᠷᠳᠤ
a
ᠠ
ᠢᠮᠠᠭᠠ
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Since this is an alphabet, the absence of vowel sounds in consonant clusters or after codas is marked simply by an absence of vowel letters. There is no special shaping or mark to indicate a consonant cluster, eg.
eg.
ᠥᠷᠭᠡᠨ
ᠥ,ᠷ,ᠭ,ᠡ,ᠨ
However, the written text of a word doesn't always map directly to its sound. For example, many words end with a vowel letter that is not pronounced, and many vowel letters in the middle of a word can be omitted or reduced in the pronunciation. Nothing indicates visually when these vowels are not pronounced.
eg.
ᠥᠨᠳᠡᠭᠡ
ᠥ,ᠨ,ᠳ,ᠡ,ᠭ,ᠡ
ᠰᠣᠨᠤᠰᠬᠤ
ᠰ,ᠣ,ᠨ,ᠤ,ᠰ,ᠬ,ᠤ
Consonants
Onsets
Codas
ᠪ,ᠫ,ᠳ,ᠲ,ᠭ,ᠺ,ᠻ,ᠭ,ᠭ
ᠭ
ᠵ,ᠽ,ᠴ,ᠼ,ᠵ,ᠴ
ᠹ,ᠰ,ᡂ,ᡁ,ᠿ,ᠱ,ᠰ,ᠬ,ᠾ
ᠮ,ᠨ
ᠩ,ᠨ
ᠸ,ᠷ,ᠯ,ᡀ,ᠶ
ᠪ
Nominal shapes are shown; in practise, the shape will vary according to the joining context. The finals shown are just a few that are dedicated finals, or whose pronunciation changes when syllable-final.
Basic Mongolian consonants
The Mongolian language has a basic set of 16 consonants.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
ᠪ,ᠫ,ᠳ,ᠲ,ᠴ,ᠵ,ᠰ,ᠱ,ᠬ,ᠭ,ᠨ,ᠩ,ᠮ,ᠷ,ᠯ,ᠶ
Glyph shaping
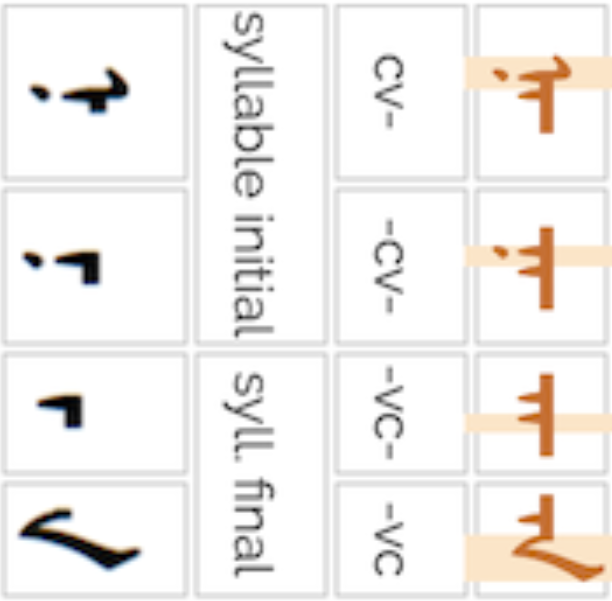
Each Mongolian letter usually has multiple shapes, and the differences in glyph shape are not solely dependent on the cursive interactions, as is the case in Arabic.
The choice of shape often depends on whether the letter is used in syllable-initial or syllable-final position. But there are typically differences between the shape used for a syllable-initial letter at the beginning of a word, and one that occurs within a word. A similar situation applies for syllable-final shaping: is the letter followed by more letters, or word final?
Furthermore, a particular shape may be used before an MVS space, or after a NNBSP gap. All of this shaping should normally be handled automatically during the rendering process.
On the other hand, there are sometimes other, unpredictable changes in shape for letters in certain words. In this case, the content author needs to add an appropriate Free Variation Selector (FVS) formatting character after the letter to be shaped. See context.
QA and GA
In the current Mongolian encoding model, the code points ᠬ and ᠭ each have both masculine and feminine forms. The different forms have different shapes and different pronunciations.
The masculine form is used before a masculine vowel, and vice versa.
masculine
feminine
masculine
feminine
initial
medial
Initial and medial forms for QA and GA followed by masculine then feminine vowels.
The font is expected to automatically select the appropriate glyph form for these velar consonants. This becomes more complicated, however, where these consonants occur without a following vowel (ie. before another consonant, or in final position).
In Sibe and Manchu, the form is selected based on the previous vowel. In Mongolian and Todo, however, the shape depends on the gender of the word, as described in harmony, and this may not be detectable from the previous vowel. The Unicode Standard gives examples of 2 words where it is necessary to look at the beginning of the word to determine the shape at the end of the word.u§534
The words ʤarlig and čerig, showing different forms of the final letter GA.show composition: ᠵᠠᠷᠯᠢᠭ
ᠵᠠᠷᠯᠢᠭ
show composition: ᠴᠡᠷᠢᠭ
ᠴᠡᠷᠢᠭ
This puts a significant strain on the capabilities of the font itself and of the font developers, and some fonts do not achieve this correctly. In addition, exceptional circumstances have to be taken into account. In consequence, fonts may need 100 or more rules to handle this.
Suffixes
Many Mongolian suffixes are separated from the root by a small gap. Multiple suffixes may be attached to the word stem, each with their own initial gap. The gap is narrower than an ordinary space, but it also produces some typographic effects on the surrounding text.
eg.
ᠵᠠᠷᠢᠮᠳᠠᠭᠠᠨ
ᠵ,ᠠ,ᠷ,ᠢ,ᠮ,,ᠳ,ᠠ,ᠭ,ᠠ,ᠨ
Characters immediately following the gap may take on special shapes. In addition, lines and word selections, etc. should not be broken where these gaps appear; the word and its suffixes should be kept together.
180E should be used for this gap. Apart from being the right size, it should also indicate that shaping and typographic effects are needed.
The Unicode Standard used to recommend 202F (NNBSP) for this gap, because it is thinner than a normal space, and prevents line-breaking. However, that advice has now changed. Nontheless, legacy text may still contain NNBSP.
eg.
ᠵᠠᠷᠢᠮ ᠳᠠᠭᠠᠨ
Repertoire extension
The full set of consonants used for Mongolian includes 11 letters that are normally used for writing foreign sounds.
ᠸ,ᠹ,ᠺ,ᠻ,ᠼ,ᠽ,ᠾ,ᠿ,ᡀ,ᡁ,ᡂ
See a couple of examples below, but click on the items in the above list to see more.
No special mechanisms for representing doubled consonants
Consonant sounds to characters
This section maps Mongolian consonant sounds to common graphemes in the Traditional Mongolian orthography.
p
ᠪ
ᠪᠠᠷᠰ
pʰ
ᠫ Mostly used for foriegn words. One source says mostly used at the beginning of foreign wordsws, but another indicates use in medial and final positions only.
ᠫᠢᠸᠣ᠋
t
ᠳ
ᠳᠠᠯᠠᠢ
tʰ
ᠲ Not used in word or syllable final position for Mongolian words.
ᠲᠥᠮᠦᠰᠦ
t͡s
ᠵ
ᠵᠤᠵᠠᠭᠠᠨ
ᠽ Used to transcribe foreign words. (Originally used to transcribe Tibetan dz ཛ; Sanskrit ज).
ᠪᠤᠤᠽ
t͡sʰ
ᠴ
ᠴᠠᠰᠤ
ᠼ Used to transcribe foreign words. (Originally for Tibetan ཚ tsʰ and Sanskrit छ cha.)
t͡ʃ
ᠵ
ᠡᠯᠵᠢᠭᠡ
t͡ʃʰ
ᠴ
ᠴᠡᠴᠡᠭ
k
ᠭ before front vowels or non-vowels.
ᠥᠷᠭᠡᠨ
ᠺ Used to transcribe foreign words (originally for Tibetan ག ga and Sanskrit ग ga).
ᠺᠢᠨᠣ᠋
ᠻ Used for transliterations.
ᠻᠠᠷᠲ᠋
ɡ
ᠭ before front vowels or non-vowels.
ᠭᠡᠷᠭᠡᠢ
ɢ
ᠭ before back vowels.
ᠭᠠᠬᠠᠢ
f
ᠹ Used to transcribe foreign words, such as Tibetan ཕ pʰ.
ᠺᠣᠹᠧ
s
ᠰ
ᠰᠠᠯᠬᠢ
ʃ
ᠱ
ᠱᠣᠩᠬᠤᠷ
ᠰ Pronounced ʃ before i, but also occurs before other vowels.
ᠰᠢᠪᠠᠭᠤ
ʐ
ᠿ Used in Inner Mongolia to transcribe Chinese rɻ ~ ʐ, always followed by an i. Transliterates ʒ in Tibetan ཞ ʒa.
ɕ
ᡂ Transcribes Chinese chi - used in Inner Mongolia.
ʑ
ᡁ Transcribes Chinese zhi - used in Inner Mongolia.
x
ᠬ Mostly used in masculine words.
ᠬᠠᠭᠠᠨ
h
ᠾ Used to transcribe foreign words. (Originally used to transcribe Tibetan /h/ ཧ, ྷ; Sanskrit ह).
ᠾᠧᠵᠢᠩ
m
ᠮ
ᠮᠤᠤᠷ
n
ᠨ
ᠨᠣᠭᠤᠭᠠᠨ
ŋ
ᠩ Only used at end of word (medial form used for composites).
ᠮᠠᠨᠠᠩ
-ŋ
ᠨ in syllable-final position.
ᠣᠯᠠᠨ
w
ᠸ Used to transcribe foreign words. (Originally used to transcribe Sanskrit वU+0935 DEVANAGARI LETTER VA.) Not used in syllable final position, except before MVS.
ᠸᠠᠩ
w̜
ᠪ Coda.
ᠠᠷᠪᠠ
r
ᠷ Not normally used at the beginning of Mongolian words. Transcribed foreign words usually get a vowel prepended, for example, transcribing Русь (Russia) results in ɔ.rʊs.
ᠢᠷᠡᠬᠦ
ɮ
ᠯ
ᠯᠢᠷ
lʰ
ᡀ Transcribes Tibetan lh.
ᡀᠠᠰᠠ
j
ᠶ Not used in syllable final position, except before MVS.
ᠶᠠᠰ
Other features
Combining marks
The Mongolian block contains 3 visible combining characters.
ᢅ,ᢆ,ᢩ
It also contains 3 invisible control characters, also classed by Unicode as combining characters, which can be used to indicate specific alternative forms for letters. See Context-based shaping.
Numbers
Mongolian often uses ASCII digits, however there is a set of Mongolian digits.
᠐,᠑,᠒,᠓,᠔,᠕,᠖,᠗,᠘,᠙
Traditionally, Mongolian digits run horizontally within the vertical lines, but it is common in modern text for them to run down the line instead.u
Digits arranged so they run down the line (left) and across the line (right).
Text direction
Mongolian script is written vertically, top to bottom, in columns that flow left to right. This is an unusual configuration. (Chinese, Japanese and Korean vertical text columns are read right to left). It derives from the fact that this script descended from a script (Old Uyghur) that was written right to left.
Fullwidth Latin alphabetic and digit characters are seen in traditional Mongolian text, as are fullwidth Chinese characters and punctuation (see mixed_text). When used, the latter are displayed upright. The fullwidth series of Unicode characters may be used as an easy way to achieve this.g5
Mixed Mongolian and Chinese text. (Click on the image to see larger.)
Cyrillic characters may also be seen, used in a way that resembles fullwidth characters, but this is actually a property of the font used to display the characters, since there are no fullwidth cyrillic code points in Unicode. Emoji are also expected to be displayed upright.g5
Non-fullwidth letters and numbers tend to be written sideways.g5 See mixed_text_sideways.
Sideways Latin text and numbers in vertical Mongolian.
Upright digits may be used for list counters. And Mongolian also has the feature referred to in Japanese as tate chu yoko, whereby small sequences of non-fullwidth numbers or punctuation may run horizontally within the vertical flow.g5 See fig_digits_tate_chu_yoko.
Certain punctuation marks are upright, and others are rotated.g5 (See inline.)
Many of the conventions seen in actual digital text may be determined more by the available technology than by what the content author wants to achieve.g5
When Mongolian excerpts are shown in text that is set horizontally (such as on this page), the Mongolian is sometimes represented as a sequence of single vertical words, eg. ᠮᠣᠩᠤᠯ ᠪᠢᠴᠢᠭ, but in other cases it is rotated left and joins horizontally, eg. ᠮᠣᠩᠤᠯ ᠪᠢᠴᠢᠭ.
Mongolian text written horizontally is read left-to-right. This means that if it contains embedded text from another language, such as English, there is no bidirectional behaviour (as there would be in Arabic-script text).
Note also that it is not possible to produce a page of vertical text by printing it horizontally and then rotating the page, This is because the order of lines in the rotated page will be right-to-left, whereas it should be left-to-right.
Most of the complexity of the Mongolian traditional script has to do with two things: (1) characters are allocated on the basis of phonemic differences, but many characters share identical shapes, and (2) there are many variant forms for a given character, some of which cannot be produced automatically.
Cursive shaping
Similarly to the Arabic script, Mongolian letters within a word tend to be joined cursively along the centre baseline, and the shapes of joined characters can vary significantly in various positions. Unlike Arabic, and many other cursive scripts, there are no characters that only join on one side.
Letters following a Mongolian suffix space may need to be displayed using a joining form, however that is not always the case. It depends on the suffix.
The base shape of a letter can change significantly, depending on the position in a word. On the other hand, a number of letters have adopted identical shapes in the same, or sometimes different joining contexts.
Context-based shaping & positioning
Certain letters ligate with adjacent letters.
In addition to the cursive shaping mentioned just above, individual letters may have context-dependent variant forms, that can be quite different from the standard forms. Where the alternative form can be determined algorithmically, the font should produce the change.
An unusual feature of the Mongolian traditional script is that the shape of a letter may depend on the vowel harmony of the word, and so may be determined at some distance from the character in question.
For unpredictable variants, the Mongolian block has three 'free variation selectors' which can be used to indicate which variant form should be used. The variant selector is used immediately after the character to be changed.
᠋,᠌,᠍,᠏The word for 'bus' (left) contains 3 free variation selectors. The right hand side shows what the word would look like without variation selectors.show composition
ᠠᠦ᠋ᠲ᠋ᠣᠪᠦ᠋ᠰ
Unfortunately, variation selector usage is still not completely standardised across Mongolian fonts. For a set of tables summarising current standardisation proposals and major font support see Mongolian variant forms.
Typographic units
Word boundaries
The concept of 'word' is difficult to define in any language (see What is a word?). Here, a word is a vaguely-defined, but recognisable semantic unit that is typically smaller than a phrase and may comprise one or more syllables.
Words are separated by spaces. The gaps before certain suffixes are not considered to be word delimiters. Those gaps are created using 180E (or 202F in older texts).
Compound words or names are sometimes hyphenated. In such cases ᠆ should be used (since it wraps to the beginning of a new line, unlike the ordinary hyphen which remains at the end of the first line – see hyphenation).
eg.
ᠠᠯᠢ᠆ᠤᠮᠠᠷᠢ
Graphemes
Grapheme clusters
A grapheme is a user-perceived unit of text. The Unicode Standard uses generalised rules to define 'grapheme clusters', which approximate the likely grapheme boundaries in a writing system.
tbd
Punctuation & inline features
Phrase & section boundaries
Mongolian uses a mixture of local punctuation and punctuation from Chinese.
phrase
᠂
᠄
sentence
᠃
?
!
Question marks and exclamation marks are fullwidth, upright characters (ee an example). Mongolian punctuation is horizontally centred in each vertical line.n§#punctuation_rules
Bracketed text
Mongolian commonly uses parentheses or brackets to insert parenthetical information into text. Parentheses and brackets may be fullwidth or may not be. They are rotated.g5
start
end
standard
(
)
(
)
alternate
〔
〕
Quotations & citations
A variety of brackets are used around quotations. Quotation marks are often fullwidth but may not be. Quotation marks are rotated, as in Chinese.g5
start
end
initial
《
》
«
»
nested
〈
〉
Abbreviation, ellipsis & repetition
᠁ is used for ellipsis.
Inline notes & annotations
Like Chinese and Japanese, Mongolian text uses ruby annotations to express the pronunciation of words for beginners or in ambiguous situations. This is useful in Mongolian because many characters look identical in cursive text.
Annotations are typically written in the Latin script, and run down the right side of the line.g1
Ruby in Mongolian text.
Other inline features
Underlines run down the right side of vertical lines of Mongolian text. Lines down the left side are equivalent to overline in English text.n§#h_text_decoration
The side of the vertical line for underlines doesn't change for embedded Latin text. Since Latin text runs down the page, this makes the underline run across the top of the Latin letters. See the red line in text_decoration_mixed.n§#h_text_decoration
Underline in Mongolian text with embedded Latin content.
There are a number of different styles of underlining in use, as shown in underline_styles.g10
Various underline styles in Mongolian text. (Click on the picture to see larger.)
If an underline is styled so that it leaves a gap below spaces that separate words, the underline should not also leave gaps below the narrow spaces used to separate some suffixes from the word root. The desired outcome is that shown here, however implementations may vary.g9
Underlining with gaps doesn't leave a gap between roots and suffixes.
Other punctuation
᠊ is used to extend the baseline.
Line & paragraph layout
Line breaking & hyphenation
Line-breaking normally occurs at word boundaries (indicated by spaces). Words are not normally broken, but compound words separated by a hyphen can be broken before the hyphen (see hyphenation, just below).
Lines should also not break on gaps between words and their suffixes when separated by 180E (or 202F in older texts).n§#mongolian_space
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for some of the characters used in modern Mongolian. Context may affect the behaviour of some of these and other characters.
Click/tap on the characters to show what they are.
« ( 〈 《 〔 should not be the last character on a line.
᠆ the Mongolian hyphen, should also appear at the start of a line, and not the end.
» ) 〉》〕 . , ; ! ? । ॥ % should not begin a new line.
Some characters prevent line-breaks both before and after them. These include 180E, 202F, and 2011.
In-word line-breaks
Words are not normally broken across line endings.
However, compound words that contain hyphens may be split at the hyphenMWG/2-N13§https://www.unicode.org/mwg/mwg2docs/mwg2-13Summaryimprovementstophonetic-RoozbehPournader.pdf. When that happens, however, the hyphen should move to the next line, and should not stay at the end of the current line.u§545
Unicode provides a special Mongolian hyphen for this: 1806, which should produce the correct line wrap behaviour. Despite the name, it is not a formatting character that becomes visible only at line breaks; it is always visible. It is also not specific to Todo.
An example of a hyphenated word, split at the hyphen, with the hyphen moved to the next line.
Text alignment & justification
To justify the text on a line, the spaces between words are adjusted.
When Chinese characters are embedded in Mongolian text and justification applied, space is not added between the Chinese characters (as it would be in a Chinese document).n§#mixed_arrangement_cjk
Space is added around embedded Chinese text during justification, not between.
Paragraphs
A new paragraph may be signalled by indentation of the first line, or by paragraph leading.
Baselines, line height, etc.
The default baseline for Mongolian-script text runs down the centre of the vertical line spacing, as shown in centre_baseline.n§#h_text_decoration
The Mongolian baseline runs down the centre of the vertical line.
When mixed with other languages, the text in those languages should also be centre-aligned along the Mongolian baseline.n§#mixed_arrangement_alphanum
Counters, lists, etc.
You can experiment with counter styles using the Counter styles converter. Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
The Mongolian orthography uses ASCII and native numeric styles. It also uses fixed styles based on circled numbers.
Numeric
The mongolian numeric style is decimal-based and uses these digits.rmcs
᠐,᠑,᠒,᠓,᠔,᠕,᠖,᠗,᠘,᠙
eg.
᠑,᠒,᠓,᠔,᠑᠑,᠒᠒,᠓᠓,᠔᠔,᠑᠑᠑,᠒᠒᠒,᠓᠓᠓,᠔᠔᠔
Fixed
The circled-decimal fixed style uses these numbers. It is only able to count to 50.
The dotted-decimal fixed style uses these numbers. It is only able to count to 20.
⒈,⒉,⒊,⒋,⒌,⒍,⒎,⒏,⒐,⒑,⒒,⒓,⒔,⒕,⒖,⒗,⒘,⒙,⒚,⒛
The Baiti and Noto fonts show the first 20 counters for the circled style lie on their side, instead of upright. The Mongolian White font fixes this, but doesn't appear to handle dotted digits above 9.
As list counters, these digits are generally used upright, as shown in fig_circled_counters.g5
List counters rotated. (Click on the image to see larger.)
Page & book layout
General page layout & progression
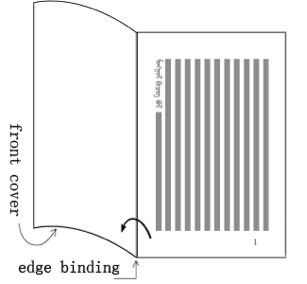
Generally, book binding is on the left, and pages are turned towards the left, unlike books set vertically in Chinese or Japanese.n§#h_binding
Mongolian books are bound on the left, and pages turn to the left.
Columns run horizontally, rather than vertically as in Western typography.n§#h_columns
Columns run horizontally. (Click on the image to see larger.)
It is common for the default orientation of pages to be landscape, rather than portrait.n§#h_paper_direction
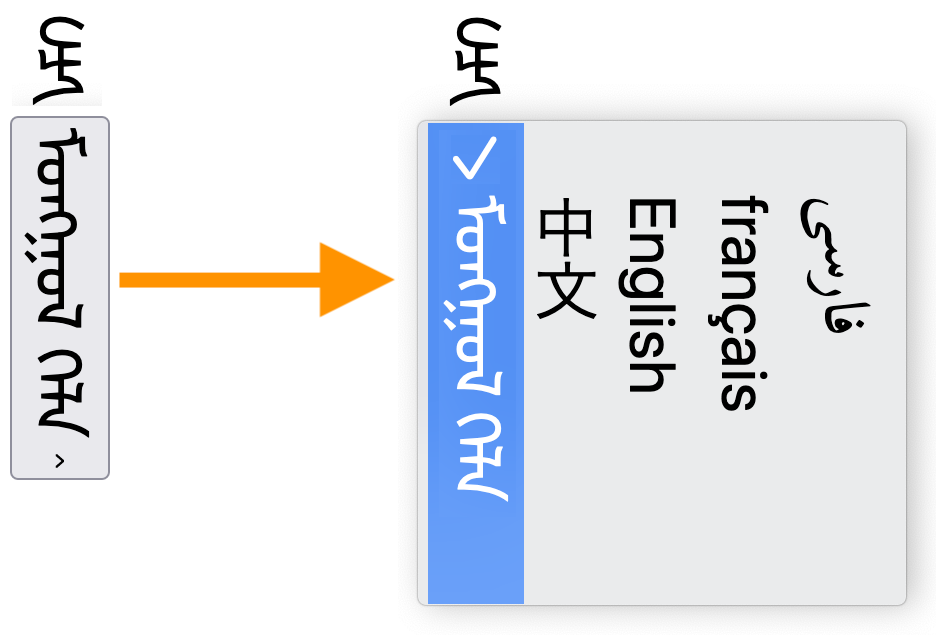
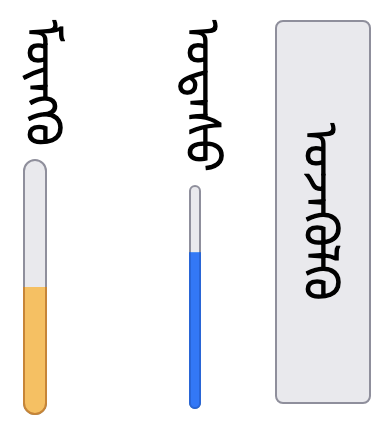
Forms & user interaction
Form controls on Web pages should be rotated 90 degrees clockwise, compared to the form controls for Western languages.9→
The following figures show examples of what is expected. Major browsers don't fully support forms with this orientation at the time of writing.
Text entry form controls.A select control closed (right) and then open while the user makes a choice (left).Meter, progress, and button elements (right to left).
Page numbering, running headers, etc
Page numbers should be displayed on the upper or lower side of the page.n§#h_page_numbering