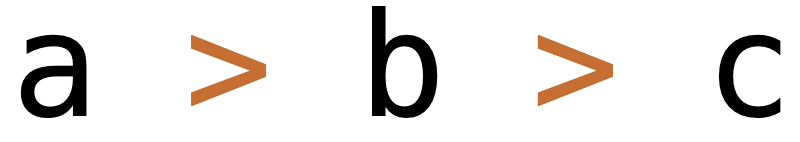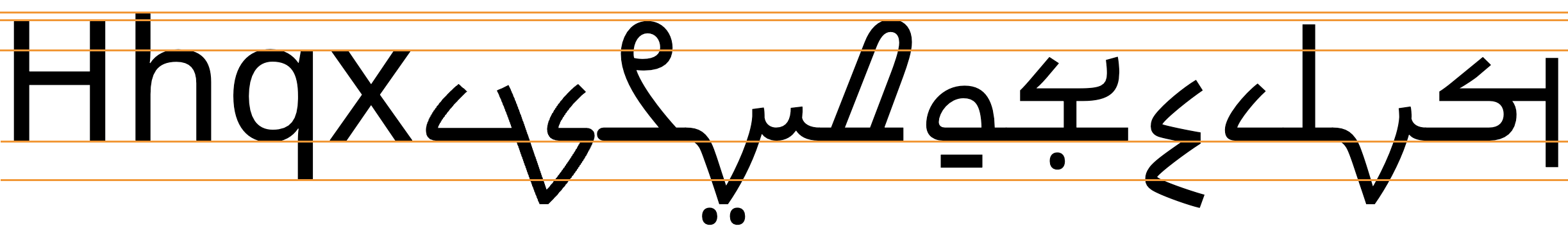This page brings together basic information about the Mandaic script and its use for the Neo-Mandaic language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Mandaic using Unicode.
The relatively small number of letters in Mandaic (especially for vowels) cover a fairly wide set of allophonic sounds. Differences in pronunciation also arise due to the dialect or accent of the speaker. Although these may be spelled out in some of the examples, it is best to assume that many of the letters described here represent more than one sound, and that the pronunciations given for the examples may differ for other speakers.
It was difficult to find word lists that show IPA pronunciations for Neo-Mandaic spellings, although there are lists of words that show IPA for transcriptions that appear to be close to transliterations. A Neo-Mandaic term with † alongside it indicates that the spelling has been guessed at, rather than copied.
Source: Paragraph 1, Unicode UDHR, article 1; paragraph 2, From a Masiqta hymn (Macuch 1967: 54, no.5. lines 1-3) in Daniels.
Usage & history
The Mandaic script ( ࡀࡁࡀࡂࡀābāgāMandaic alphabet ) is used for writing Neo-Mandaic, an Iraqi language spoken by about 5,500 people, and is also the script of Classical Mandaic, the liturgical language of the Mandaean religion. Persecution and war over a long period has reduced the language to a severely endangered level. There may be 200 or less first language speakers of Mandaic.
The origins of the script are not clear, but many scholars believe it to be descended from Aramaic via Parthian. Research has indicated that it has remained relatively unchanged since its initial development between the 2nd and 7th centuries CE.
Unicode 17 has 1 dedicated Mandaic block, comprising just 29 characters.
The Mandaic script is an alphabet, ie. all vowels are written explicitly, alongside consonants; there is no inherent vowel in a consonant (abugidas), certain vowels are not systematically dropped (abjads), and consonant and vowel are not combined in the same character (syllabaries). This is unusual among scripts of semitic origin.
The standard Mandaic alphabet consists of 24 letters, since 24 is a significant number to Mandaeans, however this is only achieved by repeating the first letter of the alphabet, ࡀ, at the end, and including a ligature, ࡗ.
Vowels Vowels are written using 4 vowel letters, derived from consonants. The 4 vowel letters represent 6 phonemes, and various allophonic realisations depending on syllabic context or speaker location (see phonemesV). A seventh phoneme, ə, is unwritten.
Three of the 4 letters representing vowel sounds may represent one of two phonemes; the specific phoneme can be clarified for educational purposes using 085A.
Standalone vowels only occur in word-initial position. The vowel letter, 084F, is used before 0849 and 0845 when they represent standalone vowels.
Consonants Mandaic has 17 basic consonant letters. Similarly to Syriac, many of the consonant letters, especially the stops, represent more than one phoneme – typically a stop and a fricative. Particular phonemes and additional sounds used in Arabic and Persian can be indicated explicitly using an affrication mark added to consonants, and one extra character..
3 more special characters represent the sounds of grammatical syllables.
Gemination is not normally marked, but can be indicated using a combining mark.
Vowel absence Since this is an alphabet, vowel absence in consonant clusters or after codas is marked simply by an absence of vowel letters. There is no special shaping or mark to indicate a consonant cluster.
Numbers Mandaic has no native digits.
Layout Ukrainian text runs right to left in horizontal lines, but numbers and embedded Latin text are read left-to-right. Words are separated by spaces. There is no case distinction.
The script is cursive, but basic letter shapes don't change radically. In some letters, the joining edge of the glyph adapts to join with an adjacent character.
Punctuation is limited, and uses native and Arabic code points.
Notable features
vowels and some consonants represent more than one phoneme
diacritics can disambiguate phonemes in educational texts
some short vowels are elided in the text
the alphabet has 24 letters because that is a significant number in Mandaean, but to reach that number the alphabet includes a ligature and the first letter is repeated at the end of the alphabet.
Character index
Letters
Show
Consonants
ࡐ,ࡁ,ࡕ,ࡃ,ࡈ,ࡊ,ࡂ,ࡒ,ࡎ,ࡆ,ࡑ,ࡔ,ࡄ,ࡌ,ࡍ,ࡓ,ࡋ
Vowels
ࡉ,ࡅ,ࡀ,ࡏ
Other
ࡖ,ࡇ,ࡗ,ࡘ,ـ
Combining marks
Show࡙,࡛,࡚
Punctuation
Show࡞
Other unconfirmed
،,؛,«,»,؟,﴾,﴿
Other
Show,,,,,,,,,,,,͏
To be investigated
(,),,,.,/,{,},٠,١,٢,٣,٤,٥,٦,٧,٨,٩,٪,۔,‘,’
Items to show in lists
Phonology
These sounds are for the Neo-Mandaic language.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones
.
Vowel sounds
Plain vowels
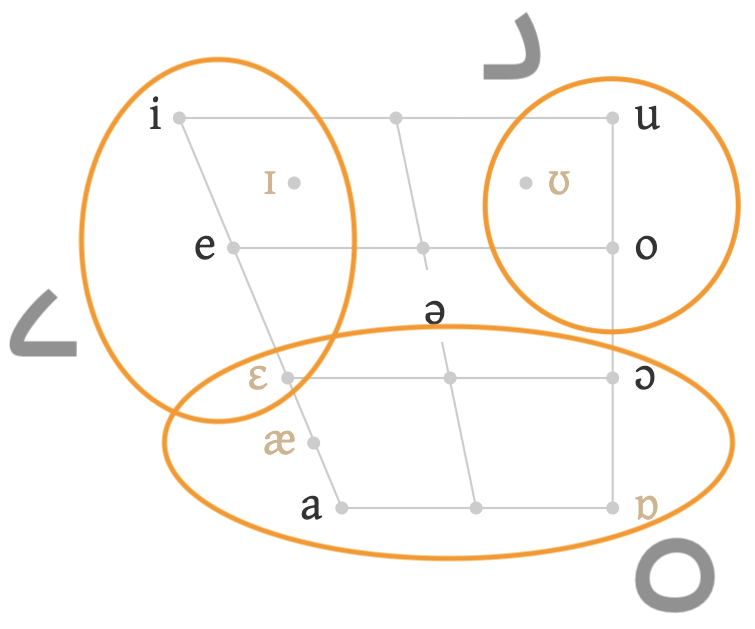
There is considerable allophonic variation in Neo-Mandaic vowels. fig_vowel_allophones shows common realisations of the basic sounds listed above, based on syllable type. Note that o, e, and a are very rare in open, accented syllables.h
Open syllable
i
u
ɔ
oː
e
a~æ
Open, accented syllable
iː
uː
ɔː
o
e
a~æ
Closed syllable
ɪ
ʊ
ʌ
ɛ
ɑ
Typical allophones based on syllable type for the primary vowels in Neo-Mandaic.h§59
Complex vowels
Häberlh§59 describes 5 diphthongs.
ɛɪ
ɔɪɔʊ
aɪaʊ
Consonant sounds
labial
dental
alveolar
post-
alveolar
palatal
velar
uvular
pharyngeal
glottal
stop
pb
td
kɡ
q
ejectives
ðˤ
tˤ
affricate
t͡ʃd͡ʒ
fricative
fv
θð
sz sˤzˤ
ʃʒ
ɣ
χʁ
ħʕ
h
nasal
m
n
approximant
w
l
j
trill/flap
r
Tone
Neo-Mandaic is not a tonal language.
Structure
tbd
Alphabet
Click on the characters to find where they are mentioned in this page.
The Mandaic alphabet has 24 letters, since that number is symbolic to Mandaeans. To reach that number, the alphabet includes the ligature ࡖ and the first letter is repeated at the end of the alphabet.
ࡀ,ࡁ,ࡂ,ࡃ,ࡄ,ࡅ,ࡆ,ࡇ,ࡈ,ࡉ,ࡊ,ࡋ,ࡌ,ࡍ,ࡎ,ࡏ,ࡐ,ࡑ,ࡒ,ࡓ,ࡔ,ࡕ,ࡖ,ࡀ
Vowels
Normal vowels
Disambiguated vowels
Plain
ࡏࡉ,ࡉ,ࡏ,ࡉࡀ,ࡇ, ,ࡏࡅ,ࡅ
ࡏ,ࡉ, ,ࡏࡅ,ࡅ
ࡉ࡚, ,ࡅ࡚
ࡀ
ࡀ
ࡀ࡚
Special
ࡇ
The table shows only phonemic vowels, unless indicated otherwise. These vowels represent a variety of allophones – see vrange for more information. Hyphens are used to indicate word-initial or word-final forms. The right-hand column shows where the vocalisation mark can be used in educational texts to disambiguate the vowel sound.
Post-consonant vowels
Vowels that follow consonants are written using 4 vowel letters, derived from consonants. The 4 vowel letters represent 6 phonemes, and various allophonic realisations depending on syllabic context or speaker location (see phonemesV). A seventh phoneme, ə, is unwritten.
Three of the 4 letters representing vowel sounds may represent one of two phonemes; the specific phoneme can be clarified for educational purposes using 085A.
Vowel letters
The Mandaic Unicode block uses just 4 characters for vowels, however each vowel letter represents 2 phonemic vowel distinctions and a number of allophonic realisations, both in quality and vowel length (see vrange).
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
ࡉ,ࡅ,ࡀ,ࡏ
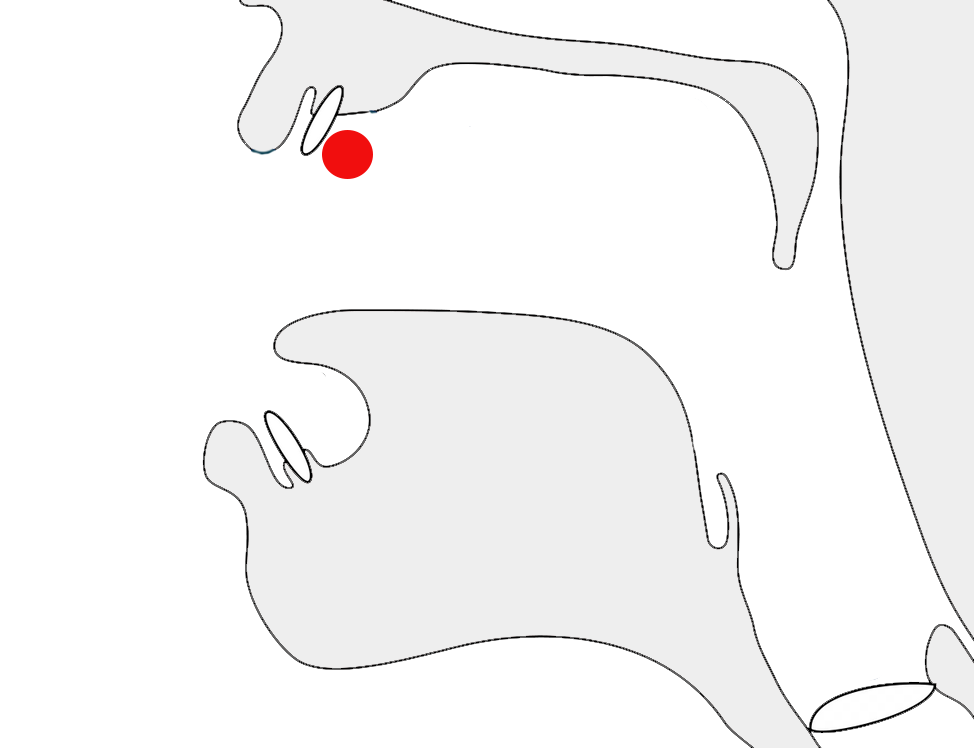
The first example just below shows ASKA representing the phoneme i. The second example shows it representing the other phoneme, ɛ, but also used to write a medial consonant in the sound ja. The third example shows it as part of the diphthong aj.
ࡌࡉࡑࡓࡀ
ࡌ,ࡉ,ࡑ,ࡓ,ࡀ
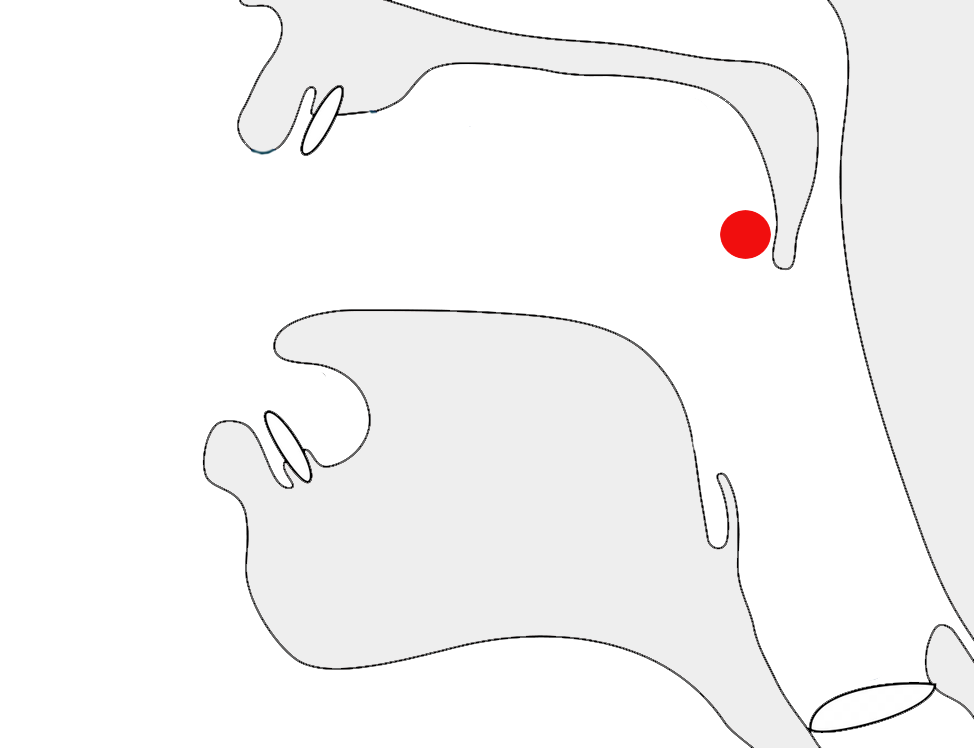
ࡋࡉࡋࡉࡀ
ࡋ,ࡉ,ࡋ,ࡉ,ࡀ
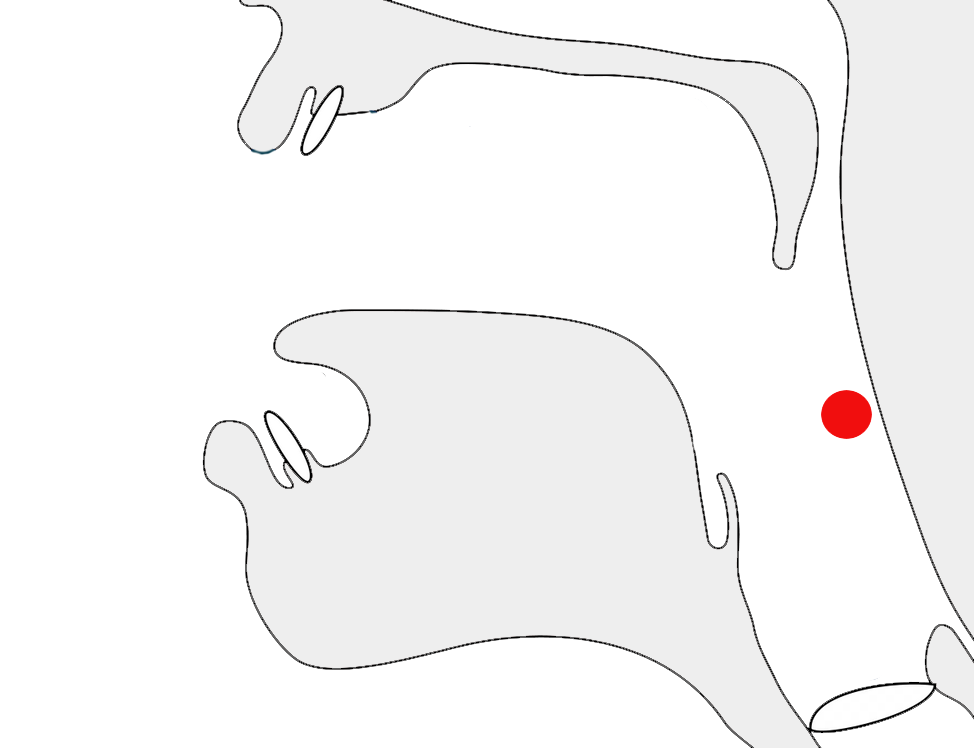
ࡀࡌࡀࡉ
ࡀ,ࡌ,ࡀ,ࡉ
All the letters used for vowels have their origin in consonants, but 0840 and 084F are now only used for vowels. They are available to use as vowels because the language dropped the glottal and pharyngeal sounds. However, 0849 and 0845, are still also used as both consonants or vowels, or may occur as glides j and w, respectively, alongside other vowels.
084F is also used as a vowel carrier for word-initial standalone vowels (see standalone). Other uses, according to Danielsh§512, include replacing two adjacent 0849 vowels, and use after consonants with a point below the line (such as 084A). It can apparently also be used instead of 0849 0840 at the end of a word to indicate that this is not the sound -ja.
Observation: Looking at text samples (such as the UDHR, for which i have no IPA transcription) it's not clear that the above covers all the uses of 084F adequately. More information is needed.
Although the script is basically alphabetic, vowel sounds are not always shown. For example, the i is not shown in ࡌࡍmnminfrom
Two ligatures encoded in the Unicode block have unwritten vowel sounds, ie.
ࡖḏdi
ࡗkḏi
Vowel ranges
fig_vowel_cloud shows how 3 of the vowel letters encompass a range of sounds, rather than representing a single, specific sound. The 6 darker phones within the circles are phonemic vowel distinctions, whereas the lighter phones are allophonic realisations. In each circled case, two primary vowel sounds are associated with a given letter. There can also be long and short versions of the primary vowels.
Sound ranges associated with vowel letters.
Observation: Need to confirm that ɛ falls within 2 circles.
Vowel disambiguation
Where needed in educational texts, 085Aw can be used to distinguish primary vowel sounds for two letters, and the length of the third.
e is indicated by 0849 085A, thereby distinguishing between ࡁࡉbiࡁࡉ࡚be
o is indicated by 0845 085A, thereby distinguishing between ࡁࡅbuࡁࡅ࡚bo
a is indicated by 0840 085A, thereby distinguishing between ࡁࡀbɔࡁࡀ࡚ba
Vowel length
According to Häberlh§75, vowel length is entirely predictable in Neo-Mandaic and depends entirely upon the placement of the accent and the syllable structure. Vowels in open, accented syllables are long, and pretonic, open syllables have short vowels.
Mandaic has no regular mechanisms in the orthography to indicate vowel length.
Standalone vowels
Standalone vowels only occur in word-initial position in Neo-Mandaich§72. Two of the vowel letters are commonly preceded by ࡏ in word-initial position. That letter on its own represents an e sound, however Danielsd§512 says that this usually represents a prothetic vowel before the t-prefix in passive verbs or before a monoconsonantal word.
Observation: Does 084F on its own therefore represent the vowel ə rather than one of the sounds covered by the 0849 range?
This gives the following typical forms:
ࡏࡉ,ࡏࡅ,ࡏ,ࡀ
eg.
ࡏࡉࡍࡂࡋࡉࡆࡉࡀ
ࡏࡅࡓࡀࡔࡋࡀࡌ
ࡏࡕࡌࡀࡋ
ࡀࡌࡀࡉ
Vowel sounds to characters
This section maps Neo-Mandaic vowel sounds to common graphemes in the Mandaic orthography.
Code points shown are for typical word-initial, word-medial, and word-final usage.
i iː ɪ
initial084F 0849
medial0849
medial084Fis preferred after a consonant with a point below the line, ie. ࡊࡏkʿ, ࡍࡏnʿ, ࡐࡏpʿ, and ࡑࡏᵴʿ.
final0849 0840
final084Ffor long iː.
final0847exclusively as the 1st person singular marker iː.
iːʷ
ࡇOnly appears at the end of personal names or at the end of words to indicate the third person singular suffix.
u uː ʊ
initial084F 0845
medial0845
final0845
e ɛ
initial084F
medial0849
medial084F 0849when it appears alongside i.
medial0849 085Ain educational texts to indicate that the sound is e rather than i.
oː o ʌ
initial084F 0845
medial0845
medial0845 085Ain educational texts to indicate that the sound is o rather than u.
finalDoes not occur.h§72
ɔː ɔ
initial0840
medial0840
final0840
aː a æ ɑ
initial0840
medial0840
medial0840 085Ain educational text to indicate a short a.
final0840
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
As for most alphabets, Mandaic has no special way of indicating that a vowel doesn't occur between two consonants. The two consonants are simply written together.
eg.
ࡊࡋࡀࡕࡀ
ࡉࡀࡄࡓࡀ
ࡖࡍࡐࡀࡒࡕ
Häberlh§729 provides some detailed information about rules for consonant clusters.
Consonants
Native sounds
Sounds in loan words
Disambiguated
ࡐ,ࡁ,ࡕ,ࡃ,ࡈ,ࡊ,ࡂ,ࡒ
ࡔ
ࡔ
ࡔ࡙,ࡔ࡙
ࡐ,ࡁ,ࡕ,ࡎ,ࡆ,ࡑ,ࡔ,ࡊ,ࡂ,ࡄ
ࡃ,ࡈ,ࡑ,ࡄ,ࡘ
ࡐ࡙,ࡕ࡙,ࡃ࡙,ࡈ࡙,ࡑ࡙,ࡊ࡙,ࡂ࡙,ࡄ࡙,ࡘ
ࡌ,ࡍ
ࡁ,ࡅ,ࡓ,ࡓ,ࡋ,ࡉ
ࡖ,ࡇ,ࡗ
The right-hand column lists sounds that only occur in words from other languages, principally Arabic or Persian.
Basic consonants
Native Mandaic sounds include 26 basic consonants (see consonantSummary). They are written using the following consonant letters. (The pronunciations in the list below show only native sounds.)
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
ࡐ,ࡁ,ࡕ,ࡃ,ࡈ,ࡊ,ࡂ,ࡒ,ࡎ,ࡆ,ࡑ,ࡔ,ࡄ,ࡌ,ࡍ,ࡓ,ࡋ
Like other orthographies in the region such as Syriac and Hebrew, some letters represent both 'hard' and 'soft' consonants, although 2 of the soft sounds in Mandaic are only used for loan words (see extendedC). fig_hardsoft shows the correspondences between hard and soft sounds. The sounds with asterisks are non-native.
Letter
ࡐ
ࡁ
ࡕ
ࡈ
ࡃ
ࡊ
ࡂ
Hard
p
b
t
tˤ
d
k
ɡ
Soft
f
v
θ
ðˤ*
ð*
χ
ʁ
Correspondences between hard sounds and soft sounds.
These sounds are not usually distinguished in writing, although they can be, if needed (such as in educational texts), by a diacritic (see Cdisambuators).
w is generally written using ࡁ, typically in the vicinity of u, o, or ɔ. It is less commonly represented using ࡅ, eg. compare:
ࡁoࡁo
ࡊࡀࡅࡊࡀ
Repertoire extension
Neo-Mandaic is heavily influenced by Arabic and Persian languages, and they can bring additional sounds into the text via loan words or dialectal variations. Mostly, the non-native sounds are written using ordinary Mandaic letters, but diacritics can be used to point out particular pronunciations (see Cdisambuators). The list below shows the main non-native sounds and the letters used to write them.
ࡔ,ࡃ,ࡈ,ࡑ,ࡄ,ࡘ
This list includes one special letter that was added to the repertoire. ࡘ is borrowed from عU+0639 ARABIC LETTER AIN to represent the Arabic sound ʕ.
Consonant disambiguator
0859 can be used to disambiguate letter sounds in educational texts, two of which sounds are typically used only in loan words (with asterisks).
ࡔ࡙,ࡐ࡙,ࡕ࡙,ࡃ࡙,ࡈ࡙,ࡑ࡙,ࡂ࡙,ࡊ࡙,ࡄ࡙
For example, compare:
ࡑࡅࡐࡓࡀ
ࡑࡅࡐ࡙ࡓࡀ
Also, although gemination is not usually marked, 085B can be used to indicate gemination of a consonant and what is referred to by native writers as 'hard' pronunciation. See clength.
Observation: It's not clear from the sources whether this means that the gemination marker can be used to indicate gemination but can also be used to indicate 'hard' sounds in the sense used in the comparison table above, where 'hard' is contrasted with 'soft'. The examples given in the sources all show gemination, implying that gemination is referred to as 'hard pronunciation'.
Special characters
ࡖ,ࡇ,ࡗ
ࡇẖ only appears at the end of personal names or at the end of words to indicate the third person singular suffix.
ࡖ is a letter of the alphabet, but it has a morphemic function, being used to write the relative pronoun and genitive exponent ḏ-, eg.
ࡖࡍࡐࡀࡒࡕ
ࡖࡎࡉࡍࡀ
ࡗ is used to write the word
ࡗ
It was derived from the digraph ࡊࡖ.
Consonant length
Gemination occurs in Neo-Mandaic words, but is not usually marked.
In educational texts 085B can be used to indicate gemination of a consonant.
eg.
ࡋࡉࡁ࡛ࡀ
ࡀࡊ࡛ࡀ
Geminated ࡕ is pronounced χt.h§728
Consonant sounds to characters
This section maps Neo-Mandaic vowel sounds to common graphemes in the Mandaic orthography.
The right-hand side shows the various joining forms for each letter.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
0850085008500850ࡐ
b
0841084108410841ࡁ
t
0855085508550855ࡕ
tˤ
0848084808480848ࡈ
t͡ʃ
0854085408540854ࡔNot common in native words.
ࡔ࡙In educational texts only.
d
0843084308430843ࡃ
d͡ʒ
0854085408540854ࡔOccurs only in some loan words.
ࡔ࡙In educational texts only.
di
0856085608560856ࡖ
k
084A084A084A084Aࡊ
kḏi
0857085708570857ࡗ
ɡ
0842084208420842ࡂ
q
0852085208520852ࡒ
f
0850085008500850ࡐ
ࡐ࡙In educational texts only.
v
0841084108410841ࡁgenerally between or following vowels such as e or i.
0845084508450845ࡅ
θ
0855085508550855ࡕ
ࡕ࡙In educational texts only.
ð
ࡃIn loan words (not common).
ࡃ࡙In educational texts only.
ðˤ
ࡈIn loan words.
ࡈ࡙In educational texts only.
s
084E084E084E084Eࡎ
sˤ
0851085108510851ࡑʒ pronunciation only occurs in some non-native words.
z
084608460846ࡆ
ʃ
0854085408540854ࡔ
ʒ
ࡑIn some non-native words.
ࡑ࡙In educational texts only.
χ
084A084A084A084Aࡊ
ࡊ࡙In educational texts only.
ʁ
0842084208420842ࡂ
ࡂ࡙In educational texts only.
ħ
ࡄOnly occurs in loan words from Arabic and Persian.
ࡄ࡙In educational texts only.
ħuᵘ
ࡇOnly appears at the end of personal names or at the end of words to indicate the third person singular suffix.
ʕ
085808580858ࡘUsed for Arabic loans.
h
0844084408440844ࡄħ pronunciation only occurs in loan words from Arabic and Persian.
m
084C084C084C084Cࡌ
n
084D084D084D084Dࡍ
ŋ
ࡍbefore a velar consonant.
w
0841084108410841ࡁtypically in the vicinity of u, o, or ɔ.
0845084508450845ࡅRare.
r
0853085308530853ࡓ
ɹ
ࡓin word-internal and syllable-final positions.
l
084B084B084B084Bࡋ
j
0849084908490849ࡉ
Numbers
The Unicode Mandaic block has no native digits. How numbers are represented in Mandaic text is TBD.
Text direction
Mandaic text runs right to left in horizontal lines.
Normally, the Unicode Bidirectional Algorithm automatically takes care of the ordering of text, as long as the 'base direction' (ie. the surrounding directional context) is set to right-to-left (RTL).
Characters are all stored in the order in which they are spoken (and typed). This so-called 'logical' order is then rendered as bidirectional flows by the application at run time, as the text is displayed or printed. The relative placement of characters within a single directional flow is based on strong directional properties (RTL or LTR) assigned to each Unicode character by the Unicode Standard. There exist, however a set of neutral direction property values, mostly for punctuation, where the placement of characters depends on the base direction.
If the base direction is not set appropriately, the directional runs will be ordered incorrectly, making it very difficult to get the meaning.
In some circumstances the Unicode Bidirectional Algorithm requires additional assistance to correctly render the directionality of bidirectional text. For such cases the Unicode Standard provides invisible formatting characters for use in plain text. See directioncontrols.
In HTML the base direction and higher level controls can be set using the dir or bdi attributes. CSS should not be used to control direction. Unicode formatting codes should also not be used where markup is available.
For authoring HTML pages, one of the most important things to remember is to use <html dir="rtl" … > at the top of a right-to-left page, and then use the dir attribute or bdi tag for ranges within the page, but only when you need to change the base direction. Also, use markup to manage direction, and do not use CSS styling.
For other aspects of dealing with right-to-left writing systems see the following sections:
Unicode provides a set of 10 formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction of a range of characters. RLE/LRE comes at the start, and PDF at the end of a range of characters for which the base direction is to be set.
In Unicode 6.1, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2069 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
Mandaic is cursive, ie. letters in a word are joined up. Fonts need to produce the appropriate joining form for a code point, according to its visual context.
The cursive treatment doesn't produce significant variations of the essential part of a rendered character (unlike Arabic). In some letters, the joining edge of the glyph adapts to join with an adjacent character. Two examples show how strokes away from the baseline are typically shortened to create joining shapes.
Two examples of small tweaks to glyphs when joining.
Other small adaptations may occur between certain adjacent characters, such as kl, wt and mn.d§512
Cursive joining forms
The cursive treatment produces only minor changes to glyph shapes in most cases. fig_joining_forms and fig_right_joining_forms show all the basic shapes in Mandaic and what their joining forms look like.
isolated
right-joined
dual-join
left-joined
Mandaic letters
ࡐ
ـࡐ
ـࡐـ
ࡐـ
ࡐ
ࡁ
ـࡁ
ـࡁـ
ࡁـ
ࡁ
ࡕ
ـࡕ
ـࡕـ
ࡕـ
ࡕ
ࡃ
ـࡃ
ـࡃـ
ࡃـ
ࡃ
ࡈ
ـࡈ
ـࡈـ
ࡈـ
ࡈ
ࡊ
ـࡊ
ـࡊـ
ࡊـ
ࡊ
ࡂ
ـࡂ
ـࡂـ
ࡂـ
ࡂ
ࡒ
ـࡒ
ـࡒـ
ࡒـ
ࡒ
ࡎ
ـࡎ
ـࡎـ
ࡎـ
ࡎ
ࡑ
ـࡑ
ـࡑـ
ࡑـ
ࡑ
ࡄ
ـࡄ
ـࡄـ
ࡄـ
ࡄ
ࡌ
ـࡌ
ـࡌـ
ࡌـ
ࡌ
ࡍ
ـࡍ
ـࡍـ
ࡍـ
ࡍ
ࡓ
ـࡓ
ـࡓـ
ࡓـ
ࡓ
ࡋ
ـࡋ
ـࡋـ
ࡋـ
ࡋ
ࡅ
ـࡅ
ـࡅـ
ࡅـ
ࡅ
ࡏ
ـࡏ
ـࡏـ
ࡏـ
ࡏ
Joining forms for shapes that join on both sides.
isolated
right-joined
Mandaic letters
ࡆ
ـࡆ
ࡆ
ࡔ
ـࡔ
ࡔ
ࡉ
ـࡉ
ࡉ
ࡀ
ـࡀ
ࡀ
ࡖ
ـࡖ
ࡖ
ࡇ
ـࡇ
ࡇ
ࡘ
ـࡘ
ࡘ
ࡗ
ـࡗ
ࡗ
Joining forms for shapes that join on the right only.
Unicode 13 changed the joining properties of 0858 and 0857. Previously they didn't join on either side. Now they join to the right. It is actually possible to find examples of the former that do join, and other examples (sometimes in the same paragraph) that do not join. To prevent joining, 200C should be used.aas
Observation: Although that isn't obvious from the font used in the table, because the line isn't continuous, you can see the behaviour in a sequence such as ࡍࡘ, where the left-hand stroke of the initial letter is shortened.
Context-based shaping & positioning
In addition to the cursive shaping described just above, the position of diacritics may vary according to whether or not the glyph of the base character extends below the baseline. The diacritic also needs to be positioned horizontally underneath the character in the appropriate place. Several such variations are shown here:
Diacritic placement varying horizontally and vertically.
The 3 combining marks found in Neo-Mandaic are normally only used for educational texts.
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
Grapheme clusters
As just mentioned, Neo-Mandaic normally uses no combining marks. When they are used, it is typically in educational texts.
Graphemes in Neo-Mandaic therefore consist of single letters or letters with a combining mark. This means that text can be segmented into typographic units using grapheme clusters.
Phrase, sentence, and section delimiters are described in phrase.
Punctuation & inline features
Phrase & section boundaries
Mandaic uses sentence punctuation sparselye. ࡞ is used to start and end text sections. Everson describes a smaller version of this symbol that is used like a comma.e There is no Unicode character for the smaller version.
The smaller size is also used in colophons (historical lay text added to religious text).d§512
Observation: The keyboard at MandeanNetwork.com suggests that writers of Mandaic use Arabic punctuation, such as the following, in addition to western punctuation such as colon, full stop, etc. This is TBC.
Mandaic uses ornate parentheses, such as the following (the shape may vary).
﴾,﴿
Mirrored characters
The words 'left' and 'right' in the Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use >U+003E GREATER-THAN SIGN, but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some of the more common ones.
(,),<,>,[,],{,},«,»,‹,›
Quotations & citations
Observation: The keyboard at MandeanNetwork.com suggests that writers of Mandaic use the following. This is TBC.
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines upwards.
latin-line-breaks shows how this happens in Arabic text, which works in the same way. Two Latin words are apparently reordered in the flow of text to accommodate this rule. Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
In this Arabic language text, the lower of these two images shows the result of decreasing the line width, so that text wraps between a sequence of Latin words.
Text alignment & justification
When text is fully justified the baseline may be stretched, as in Arabic. The Unicode Standard saysu that ـ may be used to achieve that effect, however this is not a good solution in text where the line width varies, eg. in a web browser whose window can be stretched. (The reason being that as the paragraphs reflow words will wrap into different positions on the line.)
The whole document is justified on both sides of the text. In many cases the final word is stretched internally to make the line fit the width of the available space. Only rarely are words earlier in the line stretched.
Lines where justification is achieved by stretching the last word internally.
A difference from Arabic is that many lines are stretched to the end of the available space by a trailing baseline extension. The choice of internal vs trailing extension appears to be related to the character at the end of the word.
Lines where justification is achieved by extending the baseline from the last character in a word to the end of the line.
On a good number of lines, final letters in a word appear to be squeezed onto the line by writing them above the preceding part of the line. A short example can be seen in fig_justification_hr.
Another notable feature is the use of a 'rule' such as
ࡎـــــࡀ U+084E MANDAIC LETTER AS + baseline extension + U+0840 MANDAIC LETTER HALQA, where the baseline extension can cause the combination to span all or a large part of the line. In some cases, the letter ࡔ or ࡄ may appear at the midpoint of the rule. If this combination doesn't fill a whole line, it appears at the end of a line and is long enough to fill the remaining space.
A rule drawn across a whole line.A rule drawn from the end of the text to the end of the line.
Further research is needed to ascertain whether these justification techniques are generally applicable to Mandaic text, rather than unique to this document.
Daniels saysd that 0847 can sometimes be 'manipulated calligraphically in an otherwise pedestrian manuscript in order to fill out a line'.
Baselines, line height, etc.
Mandaic uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
A few Mandaic characters have glyphs that rise above the main height, and a few more that descend below the baseline. Diacritics are attached below the letters.
To give an approximate idea, fig_baselines compares Latin and Mandaic glyphs from the Noto font. Many Mandaic letters are less high than the Latin x-height, however some extend well below the Latin descenders, especially when they have combining marks attached. A few character glyphs reach the Latin cap-height.
Font metrics for Latin text compared with Mandaic glyphs in the Noto Serif Mandaic font.
Page & book layout
General page layout & progression
Mandaic books, leaflets, etc., are bound on the right-hand side, and pages progress from right to left.
Columns are vertical but run right-to-left across the page.