This page brings together basic information about the Arabic script and its use for the Uighur language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Uighur using Unicode.
See the Arabic page for most of the information about how the Arabic script works, and the orthography used for the Arabic language. This page aims to provide Uighur-specific information.
Sample
Select part of this sample text to show a list of characters, with links to more details. Source
Change size: 38px
The Perso-Arabic orthography described here is one of several alphabets used to write the Uighur language, but has been the official alphabet of the Uyghur language, used primarily by Uighur living in China, since 1982.
Wikipedia provides the following account of the development of the orthography.
The first Perso-Arabic derived alphabet for Uyghur was developed in the 10th century, when Islam was introduced there. The version used for writing the Chagatai language. It became the regional literary language, now known as the Chagatay alphabet. It was used nearly exclusively up to the early 1920s. Alternative Uyghur scripts then began emerging and collectively largely displaced Chagatai; Kona Yëziq, meaning "old script", now distinguishes it and UEY from the alternatives that are not derived from Arabic. Between 1937 and 1954 the Perso-Arabic alphabet used to write Uyghur was modified by removing redundant letters and adding markings for vowels. A Cyrillic alphabet was adopted in the 1950s and a Latin alphabet in 1958. The modern Uyghur Perso-Arabic alphabet was made official in 1978 and reinstituted by the Chinese government in 1983, with modifications for representing Uyghur vowels.
The Arabic alphabet used before the modifications (Kona Yëziq) did not represent Uyghur vowels and according to Robert Barkley Shaw, spelling was irregular and long vowel letters were frequently written for short vowels since most Turki speakers were unsure of the difference between long and short vowels. The pre-modification alphabet used Arabic diacritics (zabar, zer, and pesh) to mark short vowels. ...
The reformed modern Uyghur Arabic alphabet eliminated letters whose sounds were found only in Arabic and spelt Arabic and Persian loanwords, including Islamic religious words, as they were pronounced in Uyghur, not as they were originally spelt in Arabic or Persian.
The Arabic script is normally an abjad, ie. in normal use the script represents only consonant and long vowel sounds. This approach is helped by the strong emphasis on consonant patterns in Semitic languages. However Uighur is not a Semitic language, and the modern version of the Arabic script used for Uighur is an alphabet. See the table to the right for a brief overview of the features of the modern Uighur orthography.
Uighur text is written horizontally, right-to-left, but numbers and embedded Latin text are read left-to-right.
Words are separated by spaces, and contain a mixture of consonants and vowels.
The script is unicameral.
The script is cursive, and some basic letter shapes change significantly, depending on their joining context.
Uighur has 25 consonant letters, including a character that serves as a vowel base. Initial vowels or those preceded by a vowel in a word are preceded by 'hamza on a tooth', eg. ئە.
This section maps Uighur vowel sounds to common graphemes in the Arabic orthography, grouped by word-initial ( i ), medial ( m ), and final ( f ). Click on a grapheme to find other mentions on this page (links appear at the bottom of the page). Click on the character name to see examples and for detailed descriptions of the character(s) shown.
The forms shown above occur within or at the end of a word. When a vowel is alone, initial, or follows another vowel inside a word, it is always preceded by ئ [U+0626 ARABIC LETTER YEH WITH HAMZA ABOVE], which in theory represents the glottal stop, but which is not pronounced as such at the start of a word – rather, it is just a support for the vowel.
Click on the characters in the lists for detailed information.
Consonant sounds to characters
This section maps Uighur consonant sounds to common graphemes in the Arabic orthography. Click on a grapheme to find other mentions on this page (links appear at the bottom of the page). Click on the character name to see examples and for detailed descriptions of the character(s) shown.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc.
The following consonants are used for the Uighur language, which is largely written as it is spoken:
پ␣ب␣ت␣د␣ك␣گ␣قچ␣جف␣ۋ␣س␣ز␣ژ␣ش␣خ␣غ␣ھم␣ن␣ڭۋ␣ر␣ل␣ي
Transcription note
In transcriptions using the Uyghur Latin alphabet (ULY) system, occasionally there can be ambiguities around the digraphs. In such cases, an apostrophe is used, eg. the transcription bashlan’ghuch for the following disambiguates n-gh from ng-h.
باشلئانگۇچ
Consonant clusters & gemination
Consonant clusters have no special annotation or shaping. The Arabic sukkun is not used to indicate missing vowels.
Geminated consonants are written by simply repeating the consonant twice, there is no use of the Arabic shadda, eg.
تاللاشئاپتاپپەرەسئۇسسۇل
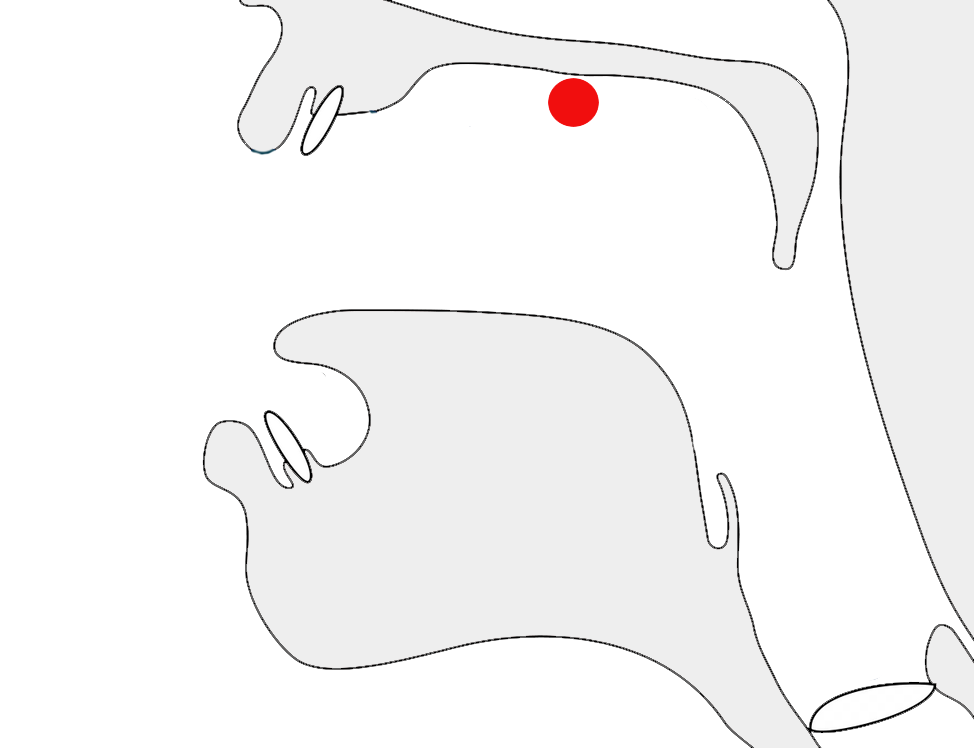
Observation:fig_date_connector shows day-month format using a tatweel-like connector, however the text doesn't connect to the horizontal line.
Day-month date forms using a low horizontal connector.
Text direction
Arabic script is written horizontally and right-to-left in the main, but as with most RTL scripts, numbers and embedded LTR script text are written left-to-right (producing 'bidirectional' text).
Uighur words are read RTL, starting on the right, but numbers and Latin text (highlighted here) are read left-to-right.
This section brings together information about the following topics:
writing styles;
cursive text;
context-based shaping;
context-based positioning;
baselines, line height, etc.;
font styles;
case & other character transforms.
The orthography has no case distinction, and no special transforms are needed to convert between characters.
Cursive script
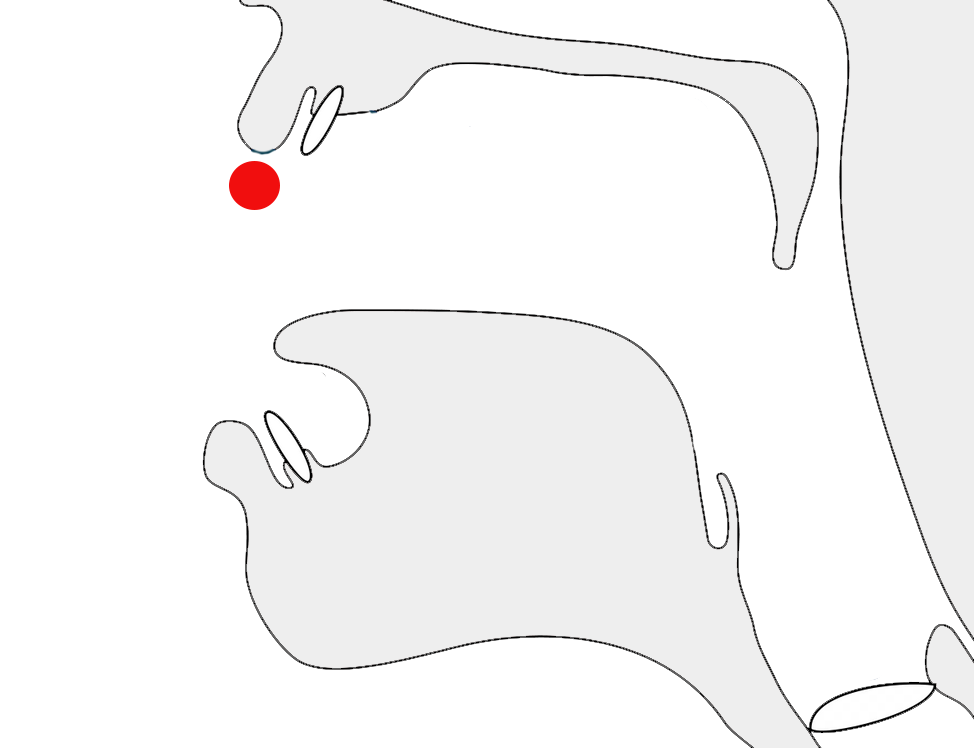
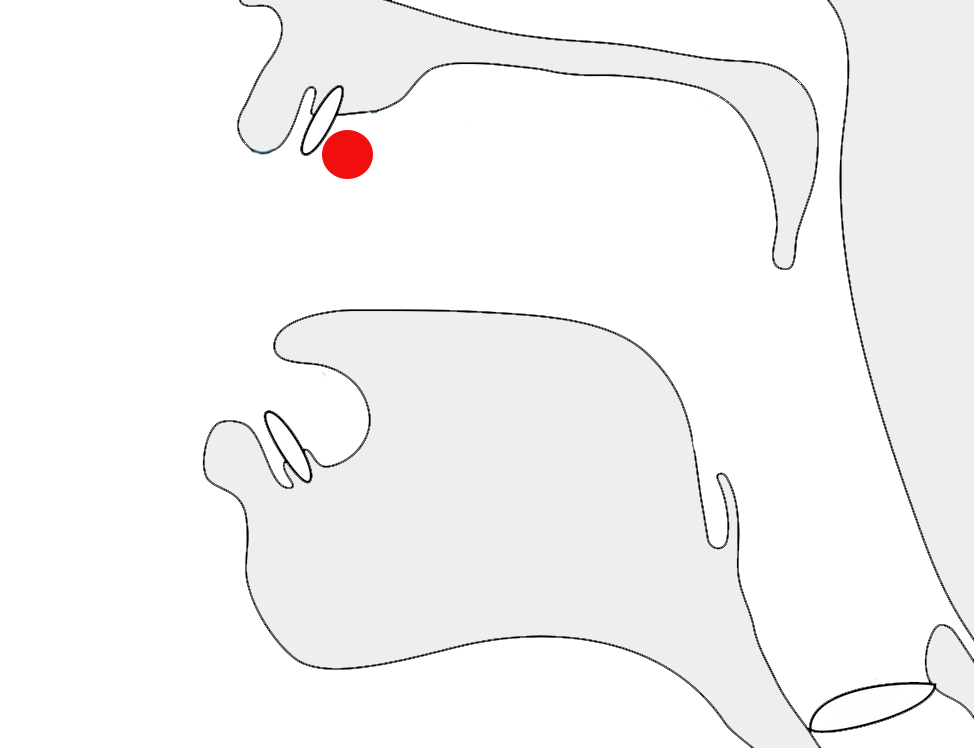
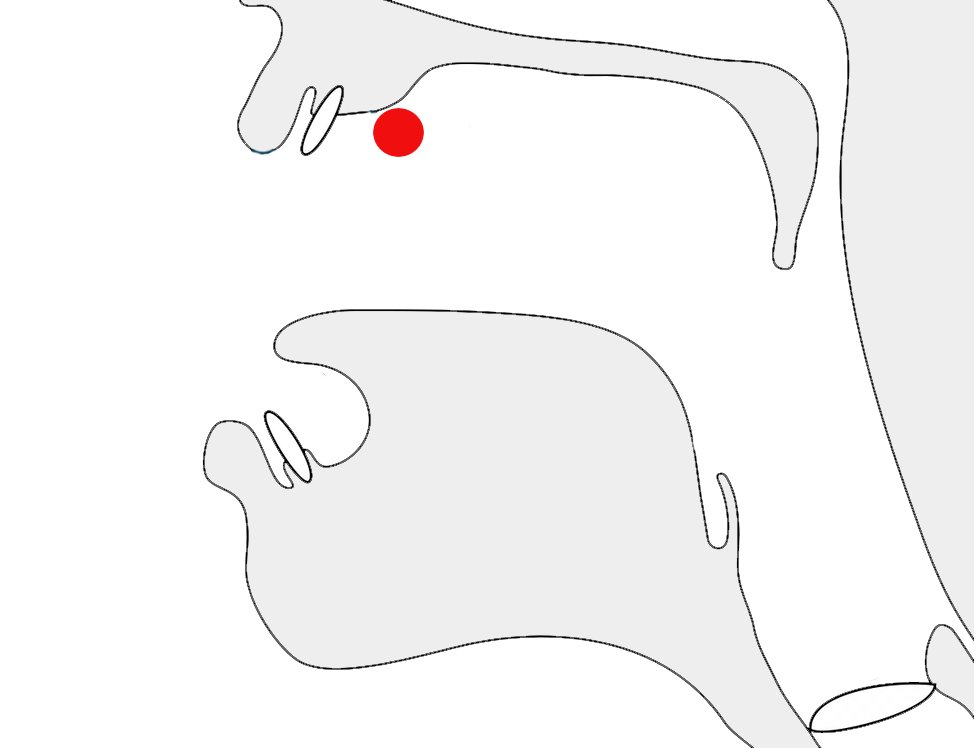
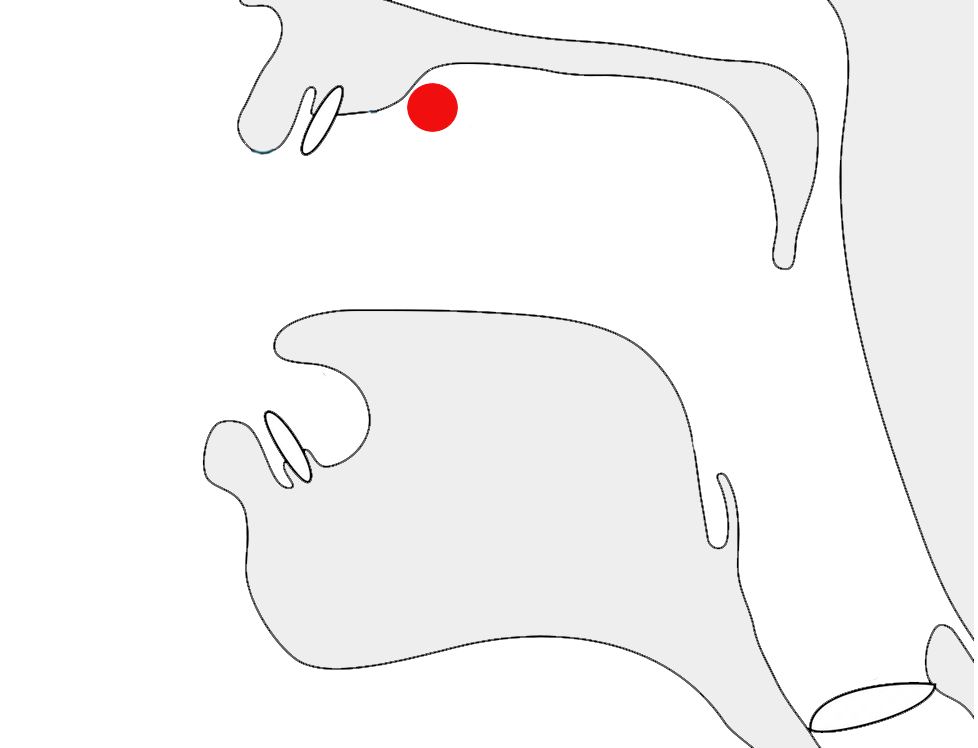
Arabic script joins letters together. This results in four different shapes for most letters (including an isolated shape).
The letter غ [U+063A ARABIC LETTER GHAIN] in 2 different joining contexts.
A few Arabic script letters only join on the right-hand side.
Context-based shaping & positioning
As in Arabic, lam followed by alef ligate, eg. ئىسلام
Font styling & weight
Observation: The image in fig_italic_forward show italicisation where the glyphs lean in the direction of text (ie. to the left).
In the italicised text of the heading the glyphs lean to the left.
Graphemes
Uighur principally uses word boundaries for line-breaking and basic justification, but uses grapheme boundaries for other operations that work at the sub-word level.
Phrase, sentence, and section delimiters are described in phrase.
Grapheme clusters
Base (Combining_mark)*
In Uighur, segmentation can be realised using Unicode grapheme clusters. A typographic unit is almost always equivalent to a letter, since precomposed code points are available for all letter and diacritic combinations. However, in decomposed text a combining hamza may be attached to the base letter. In that case, the typographic unit includes both the base letter and the combining mark.
Examples, that apply to both precomposed and decomposed text:
ئاچقۇچ
ئۆيمۇئۆي
This kind of typographic unit can be used for forwards deletion, cursor movement & selection, character counts, text spacing, and text insertion.
Observation: The comma can be found immediately after the previous word, but as shown in fig_comma_gap, it may also be surrounded by space.
Commas (in different documents) without (top) and with (bottom) leading space. 🗋
Bracketed text
(␣)
Uighur commonly uses ASCII parentheses to insert parenthetical information into text.
Observation:fig_bracketed_text shows double angle brackets being used to a kind of quotation mark, for examples.
Examples, bracketed with double angle brackets.
Quotations & citations
«␣»
Uighur text uses guillemets around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks. Note, however, that the order of use is different from that in LTR text, because they are not automatically mirrored.
Observation:fig_quotation appears to show double angle brackets being used as a quotation mark.
Quotation marks (?) using double angle brackets.
Emphasis
tbd
Abbreviation, ellipsis & repetition
tbd
Inline notes & annotations
tbd
Other punctuation
tbd
Other inline text decoration
tbd
Line & paragraph layout
Line breaking & hyphenation
Common practice is to break the sentence at any point when it reaches the end of a line.
The glyphs before the hyphen and at the start of the next line are joined forms. A very small gap appears between the hyphen and the last letter of the word at the end of the line.
Observation: The actual 'hyphen' looks like ـ [U+0640 ARABIC TATWEEL]. That would produce the expected joining form at the end of the line, although some additional mechanism would be needed to produce the form at the start of the next line. However, scans of various documents show a very small gap between the horizontal line and the last joining form at the end of the line, as can be seen in fig_hyphenation, which would negate the joining produced by a tatweel.
Text alignment & justification
fig_hyphenation not only shows hyphenation, but also shows kashida being used for justification. Kashida is an elongation of the baseline to make words wider.
Text spacing
tbd
Baselines, line height, etc.
Font baselines should match the alphabetic baseline of Latin script text, and arabic and uighur fonts should have relative sizes that match. However, Uighur also needs to look right alongside Chinese text, which has a slightly lower baseline and generally larger characters than Latin.
Counters, lists, etc.
tbd
Styling initials
tbd
Page & book layout
This section is for any features that are specific to Uighur and that relate to the following topics:
general page layout & progression;
grids & tables;
notes, footnotes, etc;
forms & user interaction;
page numbering, running headers, etc.