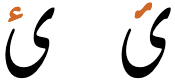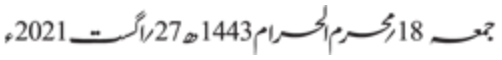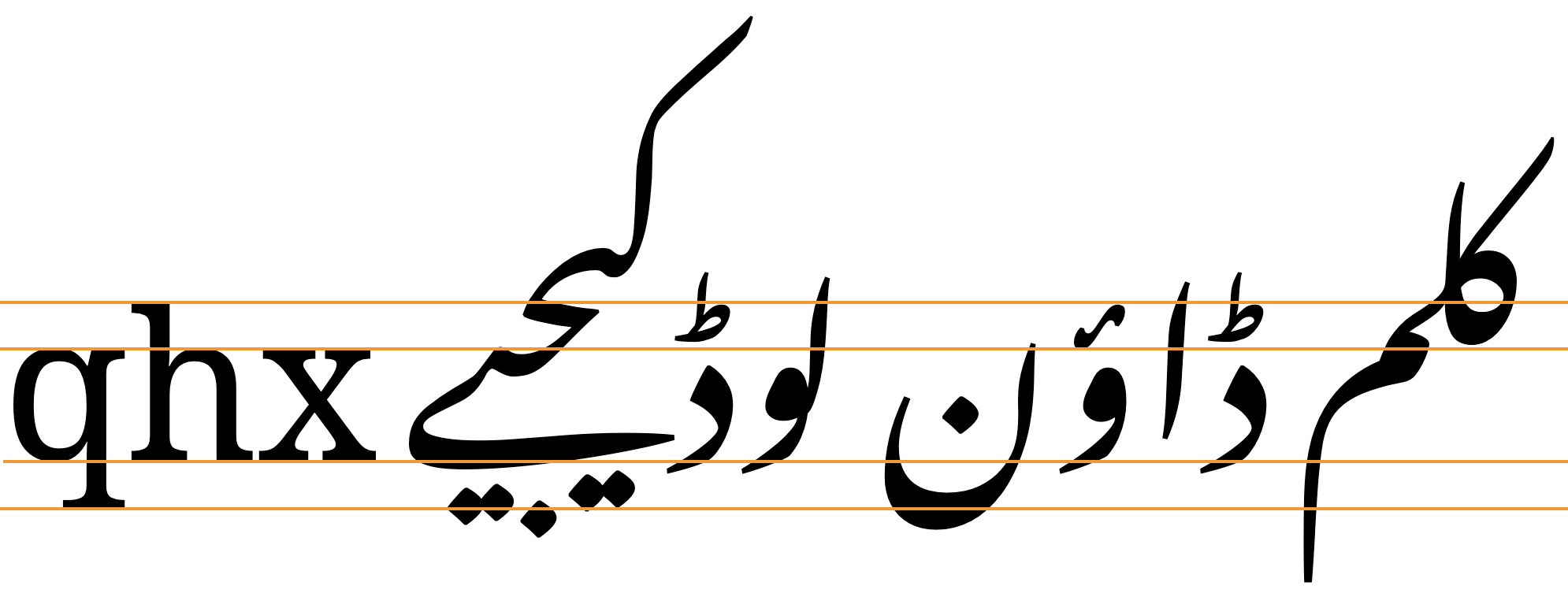This page brings together basic information about the Arabic script and its use for the Urdu language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Urdu using Unicode.
Select part of this sample text to show a list of characters, with links to more details.
Change size: 28px
دفعہ ۱۔ تمام انسان آزاد اور حقوق و عزت کے اعتبار سے برابر پیدا ہوئے ہیں۔ انہیں ضمیر اور عقل ودیعت ہوئی ہے۔ اس لئے انہیں ایک دوسرے کے ساتھ بھائی چارے کا سلوک کرنا چاہیئے۔
دفعہ ۲۔ ہر شخص ان تمام آزادیوں اور حقوق کا مستحق ہے جو اس اعلان میں بیان کئے گئے ہیں، اور اس حق پر نسل، رنگ، جنس، زبان، مذہب اور سیاسی تفریق کا یا کسی قسم کے عقیدے، قوم، معاشرے، دولت یا خاندانی حیثیت وغیرہ کا کوئی اثر نہ پڑے گا۔ اس کے علاوہ جس علاقے یا ملک سے جو شخص تعلق رکھتا ہے اس کی سیاسی کیفیت دائرہ اختیار یا بین الاقوامی حیثیت کی بنا پر اس سے کوئی امتیازی سلوک نہیں کیا جائے گا۔ چاہے وہ ملک یا علاقہ آزاد ہو یا تولیتی ہو یا غیر مختار ہو یا سیاسی اقتدار کے لحاظ سے کسی دوسری بندش کا پابند ہو۔
The Urdu alphabet ( اُردُو حُرُوفِ تَہَجِّی ), in the nastaliq style, is used to write the Urdu language, spoken in Pakistan and India.
The orthography is a modification of Perso-Arabic, which derives from the Arabic alphabet with additions for Indo-European pronunciation. After the Mughal conquest, Nasta'liq became the preferred writing style for Urdu. It is the dominant style in Pakistan, and many Urdu writers elsewhere in the world use it.
The Arabic script is an abjad, ie. short vowels are not normally written.
Urdu uses the Arabic script, with extensions to covers its much wider repertoire of sounds. A number of the extensions are based on those developed for Persian (Farsi).
Vowels Vowels are written using a mixture of combining marks and letters in vocalised text but, because the orthography for the Arabic language is an abjad, the combining mark diacritics are not normally used (and so it is difficult to accurately read the text unless you recognise the consonant patterns). However these diacritics and other phonetic information can be written where needed, and are regularly used for Qur'anic texts, dictionaries, educational materials, and where the pronunciation needs to be made clear.
Post-consonant vowels are written drawing on 5 vowel letters in order to indicate the location of 10 vowel sounds in unvowelled text, but uses an additional 5-10 diacritics when precision is needed. The code points used to represent a given vowel typically differ according to whether it is word-initial, word-medial, word-final, or isolated.
Nasalisation is indicated by a special letter in word-final position, but by a normal n-letter word-medially, although sometimes this has an additional diacritic.
Standalone vowel sounds in Urdu use a hamza diacritic and other diacritics and letters in a somewhat complicated pattern, and to represent the izafat conjunction. The choice between precomposed and decomposed realisations of characters used for these features is also complicated.
Consonants Modern Urdu has 36 basic consonant letters and 18 aspirated digraphs in its alphabet to represent native sounds, but tends to spell words loaned from Persian and Arabic using additional characters. Although it is not always easy to guess the vowel sounds in a word, the consonants are largely reliable phonetically. There is mostly a one-to-one correspondance between consonant letters and sounds. Vowels, however, are a different story.
A mandatory ligature has to be used for combinations of lam + alif.
The diacritic 0651 indicates gemination, but only in vowelled text.
Vowel absenceVowel absence is indicated in normal Urdu text by a simple sequence of consonant letters, and nothing indicates that there is no vowel sound after a word-final coda. When text is vowelled, 0652 can be used over a consonant to indicate that it is not followed by a vowel sound. Like other vowel diacritics, this is typically not used in modern text, unless it is necessary to clarify pronunciation.
NumbersUrdu uses native digits, though the code points are different from those used for the Arabic language, and Arabic code points are used for several of the more common punctuation marks.
Layout Arabic text runs right-to-left in horizontal lines, but numbers and embedded Latin text are read left-to-right. Words are separated by spaces. There is no case distinction.
Urdu is written using the nasta'liq style of Arabic writing. Glyphs are more drawn out, the baseline tends to be sloping from word to word, and there are significant extensions of ascenders and descenders. The nastaliq styling tends to reduce clarity about where one letter ends and the next starts. (The dots and other diacritics associated with letters become particularly useful for the reader.)
The script is cursive, and some basic letter shapes change radically, depending on what they join to. It is also very common for adjacent characters to ligate and to stretch to fill available space. Many of the characters share a common base form, and are distinguished by the number and location of dots or other small diacritics, called i'jam. For example, س ش ݜ ݰ ݽ ݾ ڛ ښ ڜ ۺ.
Punctuation is a mixture of ASCII and local forms.
Notable features
nasta'liq typographic style used by default
hamza plays an important, but complex role for word-medial standalones and izafat word joiners
two ways to write uː in vowelled text
aspirated consonants are written using digraphs
uses extended-arabic digits
Joining forms
Because the Arabic script is 'cursive' (ie. joined-up) writing, letters tend to have different shapes depending on whether they join with adjacent letters or not (see cursive). In addition, vowels can be represented using different characters, depending on where in a word they appear.
In scripts such as Arabic, several characters have no left-joining form. In what follows we'll use the characters ي and د to illustrate shapes. The former can join on both sides, but the latter can only join on the right.
Left-joining glyphs are commonly called initial; dual-joining are called medial; and right-joining are called final. Glyphs that don't join on either side are called isolated. However, these glyph shapes can be found in various places within a single word.
Word-initial characters usually have initial glyph shapes (eg. 064A ). However, characters that only join to the right will use an isolated glyph shape (eg. 062F ).
Furthermore, words beginning with a vowel are always preceded by a vowel carrier, which is normally ا
(eg. 0627 06CC or 0627 064E ).
Word-medial characters will typically join on both sides
(eg. 064A ) but those that only join to the right will use a final glyph (eg. 062F ).
However, if either of those is preceded by another character that only joins to the right, the glyph shapes rendered will be initial (eg. 064A )
and isolated (eg. 062F ), respectively.
Word-final characters will typically use a final glyph shape (eg. 064A and 062F ).
However, if the previous character joins only to the right, they will use isolated glyph shapes (eg.064A and 062F ).
In all this contextual glyph shaping the basic shapes used for a character can vary significantly in a script like Arabic. This also includes some characters that only have ijam dots in certain contexts.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
There are 10 vowel sounds, though there are also allophonic variants. They are usually grouped into pairs of 'short' and 'long' sounds - although the difference is qualitative, rather than just length. The basic phonemes are as follows:
The phoneme ə is often written a in phonemic transcriptions. Its pronunciation may also be slightly lower as far down as ɐ, so it is shown slightly lower than normal on the chart.
iː and uː in word-final position are typically shortened to i and u,whp§#Vowels eg. شَکتیوَستُو
Where ɦ has inherent vowels on either side, those vowels may become ɛ, eg. کَہنا A similar process occurs for word-final ɦ,whp§#Vowels eg. کَہہ
Urdu, like other Indic languages, has four forms of plosives, illustrated here with the bilabial stop: unvoiced p, voiced b, aspirated pʰ, and murmured bʱ. It also has a set of retroflex consonants.
v and w are allophones of ʋ in Urdu. w typically occurs between a consonant and vowel,whp§#Allophony_of_[v]_and_[w] eg. compare پکوانورت
Each table cell shows word-initial, word-medial, and word-final forms from right to left. The glyphs shown are illustrative; alternative shapes may occur (see joining_forms).
These tables summarise only basic vowel to character assignments. Unvowelled (normal) and vowelled forms are shown separately; short vowel diacritics should be ignored when writing normal text in Urdu. A dash signifies that the vowel is not written in that position. Note that some sounds are distinguished in vowelled text by an absence of diacritics, and that there are two possible vowelled alternatives for uː. Click on the phonetic transcriptions for more detail.
The letters ا and و in word-initial position may be replaced by ع in some words.
Post-consonant vowels
The script draws on 5 vowel letters in order to indicate the location of 10 vowel sounds in unvowelled text, but uses an additional 5-10 diacritics when precision is needed. The code points used to represent a given vowel sound typically differ according to whether it is word-initial, word-medial, word-final, or isolated.
Simple vowels
The simple vowels that are written in normal Urdu text are expressed using vowel letters (see vletter). In vowelled text, additional precision can be added using diacritics (see basicdiacritics).
Vowel letters
ا,آ,ی,ے,و
The vowel letters above all represent the location of long vowel sounds, except that 0627 can also be used to indicate short vowels in word-initial position. See the basicV to see how these letters are combined for a given vowel in a given word position.
This table shows the characters and their basic mappings to sounds in unvowelled text. (The table should be read right-to-left.)
initial
medial
final
ا
əɪʊ
ا
ɑː
ا
ɑː
آ
ɑː
ایـ
eːiːɛː
ـیـ
eːiːɛː
ـی
iː
ے
eːɛː
او
oːuːɔː
و
oːuːɔː
و
oːuːɔː
The vowels ə, ɪ, and ʊ are not marked in medial position, and generally do not occur in final position.
When text is unvowelled (as it usually is), there are only a few ways of writing vowels, and a good deal of ambiguity for the novice reader about which sound is represented by a given letter.
In situations where it is necessary to unambiguously indicate the underlying vowel sounds, the following diacritics can be added to base letters.
Click on the characters in the list box below for detailed information and examples.
ِ,ُ,ٗ,َ
As mentioned earlier, these diacritics are rarely used in Urdu content. They may be used on their own to represent short vowel sounds, or combined with the vowel letters listed above to create other sounds. See how to write the basic vowels in the basicV section.
The short vowels are generally not found in word-final position.
0657 is used to indicate that the vowel is uː or ʊ rather than ɔ. It is not usually needed, and serves only to emphasise that this is a vowel.
eg.
ہندو
Hamza
ء,ٔ,ئ,ؤ,ۂ,ۓ
A hamzā plays more than one role in Urdu, related to vowels. It is used within a word to separate standalone vowel sounds from a preceding vowel (see standalone). It is also used at the end of a word to express a short ɛ sound between 2 words, which is typically translated 'of' (see izafat).
An isolated form of hamza, ء, is occasionally used, but generally hamza is written above a preceding base letter using 0654 or a precomposed character with a hamza.
A number of precomposed combinations of base letter and hamza are encoded in Unicode. Many of these decompose and recompose under normalisation as canonical alternatives, but a few do not and need to be treated with care. For information about which precomposed characters are used or not used here see hamza_choices.
When represented by a combining character, hamza can also have one of two different shapes, depending on the font used: one like the initial form of 'ain and the other more like an italic 's'.
Two alternative shapes of hamza.
Other diacritics
ً,ٌ,ٍ,ٰ,ٖ,ٓ
The doubled vowel diacritics, 064B, 064C, and 064D are used at the ends of certain Arabic adverbs in vowelled text. The doubled zabar (fathatan) is the most common of the three marks of this type, and is usually written over an alif, although the vowel sound is short.
eg.
یقیناً
مثلاً
0670 is used in a few Arabic words over the final form of 06CC to produce the sound ɑ:.
eg.
اعلیٰ
دعویٰ
The similar diacritic 0656 is (rarely) used to indicate that a vowel is iː or i rather than e.
eg.
نُحْیٖnuhī
0653 is only found in decomposed text, and is associated only with alef. Usually the atomic character 0622 would be used.
AIN and vowels
ع
0639 is used in words of Arabic origin. In these words it is typically not pronounced but can support vowels. In this way, at the beginning of a word it can fulfill the same function as the alif, but the spelling can distinguish homophones, eg. compare:
عرب
ارب
Note, in particular, that the equivalent of آɑː is عا, as in عادت
A following ع may also affect a short vowel diacritic to produce a long vowel sound as follows:
ɑː from zabar followed by 'ain, eg. بَعد
eː from zer followed by 'ain, eg. شِعر
oː from peʃ followed by 'ain, eg. شُعلہ
Sound changes before HE
ہ,ح
ہ and ح can also modify preceding short vowels as follows:
ə → ɛ (zabar followed by he), eg.
اَحمدرَہنا
i → ɛ (zer followed by he), eg.
مِہربانیواضِح
u → ɔ (peʃ followed by 'ain), eg.
شُہرتتوجُّہ
The so-called 'silent' he that appears at the end of many words of Arabic or Persian derivation is pronounced ɑː, مکہ
Vowel length
Long vowels are generally distinguished from short vowels by the use of vletter.
Vowels may be nasalised, like at the end of the French word élan.
ن,ں,٘
Word-medially, this is written using the normal ن.
eg.
سانپ
انگریزی
Word-finally, this is indicated in Urdu by 06BA (nun ghunna), which looks like the letter nun except that it has no dot.
eg.
ماں
کروں
If it is necessary to make it clear that a medial noon character represents nasalisation rather than the sound n, the diacritic 0658 can be added above it.
eg.
ٹان٘گ
It is not used in a standard way, just when the user prefers, and is fairly uncommon.
Standalone vowels
Word-initial
Standalone vowels at the beginning of a word are normally written using, or preceded by 0627. The various forms can be seen in the chart in the section basicV. Basically, in unvowelled text, short vowels are written using alef, and long vowels are written using aleph followed by yeh or waw.
eg.
اتحاد
اوپر
There are two general exceptions. A word-initial long aː is written using 0622, and loan words from Arabic may use 0639 rather than the alef (see ain).
eg.
آرام
علم
Word-internal
A vowel that follows another vowel, with no preceding consonant, is commonly marked with a hamzā diacritic. This generally applies to words where the second vowel is one of the following: iː e ɪ uː oː, and the graphemes used are:
ئ,ؤ
See hamza_choices for notes on the use of precomposed characters, especially ئ.
Yeh. When the second vowel is an iː or e represented by ی or ے, the hamzā 'sits on a chair' before it. The hamza on its chair is written using ئ.
eg.
کئیتیئیسکوئیگئےگائے
The short vowel ɪ as a second vowel is also represented by hamzā 'on its chair' alone.
eg.
کوئلہلائن
Waw. When the second vowel is an uː or oː represented by و, the hamzā typically sits directly on top of the و. To represent this in Unicode use ؤ.
eg.
آؤجاؤں
Unmarked. Often the hamzā is omitted in this situation. Many words have the vowel combinations iːɑ̃ iːe iːo, where hamzā is not typically used.
eg.
لڑکیاںچلیےلڑکیوں کا
Izāfat
ِ,ٔ,ۂ,ۓ
Izāfatɪzɑːfat is the name given to the short vowel ɛ used to describe a
relationship between two words. It may be translated of, eg. as in the Lion of Punjab, and appears at the end of the initial word in a 2-word sequence.
See hamza_choices for notes on the use of precomposed characters, especially ئ.
Word ending:
Use:
ی
ئ
ے
ۓ
ہ
ۂ
unless it produces h in which case use the following in vowelled text: ہِ
ا
ائے
و
وئے
otherwise
add 0650 in vowelled text, or nothing at all, in unvowelled text.
Summary of how to write izafat.
ZerIzāfat is mostly represented using zer, although in unvowelled text the combining mark is commonly not shownub§99we.
eg.
شیرِ پنجاب
شیر,ِ,,پن,جاب
طالبِ علم
Heh If ہ is pronounced as h at the end of a word, then zer is used, as for any other consonant sound.
eg.
براہِ راست
ب,راہ,ِ,راست
However, when it represents a vowel sound or is silent, izafat is represented by ۂ (or its decomposed form, 06C1 0654)ub§99.
eg.
قطرۂ آب
قط,رۂ,آب
درجۂ حرارت
Yeh When the preceding word ends in ی or ے, izafat is represented by the respective letter with a hamzaub§99we.
eg.
آزادئ مذہب
آ,زا,دئ,م,ذہب
Alef or waw When the preceding word ends in a vowel written with ا or و, izafat is represented using hamza 'on it's chair' followed by baɽiː je, ie. ئےdmt§250ub§99we.
eg.
صدائے بلند
ص,دا,ئے,ب,لند
روئے زمین
رو,ئے,ز,مین
Vowel sounds to characters
This section maps Urdu vowel sounds to common graphemes in the Arabic orthography.
Urdu follows Arabic in using diacritics to express short vowel sounds, but also rarely uses them in normal text. Given the extra phonetic sounds in Urdu, compared to Arabic, the way characters are used to express vowels is much more complicated. The three short vowels are not typically found in final position.
Vowel diacritics are shown here, but are not normally shown in Urdu text. The items indicate typical word-initial, word-medial, and word-final usage. The joining forms shown are illustrative; alternative shapes may occur (see joining_forms).
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
iː
initial0627 0650 06CCeg. اینٹ
medial0650 06CCeg. تین
final0650 06CCeg. گاری
ɪ
initial0627 0650eg. انسان
medial0650eg. دن
standalone0626After another vowel with no intervening consonant, eg. کوئلہ
ʊ
initial0627 064Feg. اڑنا
medial064Feg. سست
special0648In two very common words: خود, and خوش.
uː
initial0627 064F 0648eg. اُوپَر
medial064F 0648eg. پورا
final064F 0648eg. ہِنْدُو
initial0627 0648 0657eg. اوٗپر
medial0648 0657eg. پوٗرا
final0648 0657eg. ہِنْدوٗ
eː
initial0627 06CCeg. ایک
medial06CCeg. بیٹا
final06D2eg. بجے
e
medial0650 06CCeg. شعر
final0650 06CCeg. واقع
oː
initial0627 0648eg. اوس
medial0648eg. ٹوپی
medial064F 0639In Arabic loan words, eg. شُعلہ
final0648eg. کو
o
medial064F 0639eg. شُعلہ
final064F 0639eg. تَوَقُّع
ɛː
initial0627 064E 06CCeg. ایسا
May also replace inherent vowels alongside ɦ, per the description above.
medial064E 06CCeg. کیسا
final064E 06D2eg. ہے
ɛ
izafat0650eg. شیر پنجاب
izafat06C2when the preceding word ends in a silent06C1, eg. درجۂ حرارت
izafat0654when the preceding word ends with 06CC or 06D3, eg. آزادئ مذہب
izafat0626 06D2when the preceding word ends in 0627 or 0648, eg. روئے زمین
other0650 06C1eg. لہذا
other064E 06C1eg. رہنا
other0650 062Deg. واضح
other064E 062Deg. احمد
ɔː
initial0627 064E 0648eg. اور
medial064E 0648eg. شوق
final064E 0648eg. نو
ɔ
medial064F 06C1eg. شہرت
final064F 06C1eg. توجہ
medial064F 062D
final064F 062D
ə
initial0627 064Eeg. اب
medial064Eeg. سر
medial0626after another vowel with no intervening consonant, eg. ہیئت
ɑː
initial0622eg. آج
medial064E 0627eg. باغ
medial064E 0639in Arabic loan words, eg. بعد
final064E 0627eg. لکھنا
final06C1at the end of many words derived from Arabic or Persian, eg. مکہ
final06CC 0670at the end of a few Arabic words, eg. اعلی
◌̃
Nasalisation
medial0646eg. دانت, اونچا
medial0646 0658if the author wishes to emphasise that this is nasalisation, eg. دان٘ت
final06BAeg. نہیں
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
eg.
انش
بالکل
When it is desirable to explicitly mark the absence of a vowel sound it can be indicated by the diacritic 0652, called sukūn or jazm, but this diacritic is not normally shown in text.
eg.
سَخْت
It has various possible forms, including a small round circle, something that looks like peʃ, and something like a circumflex, see fig_sukun.
Three alternative shapes of sukun.
This diacritic is never written above the final character in a word, mainly because as a rule a short vowel is not pronounced in this position.
Consonants
Non-aspirated
Aspirated
پ,ب,ت,ط,د,ٹ,ڈ,ک,گ,ق
پھ,بھ,تھ,دھ,ٹھ,ڈھ,کھ,گھ
چ,ج
چھ,جھ
ف,و,س,ث,ص,ز,ذ,ض,ظ,ش,ژ,خ,غ,ہ,ح
وھ
م,ن
مھ,نھ
و,ر,ر,ڑ,ل,ی
رھ,ڑھ,لھ,یھ
Basic letters
The alphabet standardised in 2004 by the National Language Authority in Pakistan counts 39 letters, and 18 digraphs representing aspirated consonants.
Follow the links to the character notes for the letters described below to find examples and detailed information.
و and ی represent both consonants and vowels. See vowel_mappings.
ہ normally represents the sound
ɦ
in Urdu, but it is also pronounced ɑː or is silent in certain contexts. ح is used for words of Arabic origin.
There are 3 letters for s, and 4 for z, due the retention of Arabic spelling for words of Arabic origin. The most common letter for s is س, and for z is ز.
Aspirated consonants
Aspirated consonant sounds are written using the following digraphs.
ۃ is rarely used except in certain loan words from Arabic. It is not pronounced. When replaced with an Urdu letter in naturalised loan words ہ is normally used.
Onsets
Urdu does have word-initial consonant clusters, but there are no special mechanisms in the script.
eg.
سواگت
س,و,ا,گ,ت
کیا
ک,ی,ا
Codas
Apart from nasalisation, Urdu has no special mechanisms for handling syllable- or word-final consonants.
eg.
اینٹ
برکها
Consonant length
Most native consonants may be lengthened, but not bʱ, ɽ, ɽʱ, or ɦ. Geminate consonants are always medial and preceded by one of ə, ɪ, or ʊ.whp§#Consonants
In vowelled text, which is very rare, this is shown using the diacritic 0651, called taʃdiːd.
eg.
ستر
More often than not, this is not written.
Arabic definite article
The pronunciation of ال (alif followed by lām) varies when it represents the Arabic definite article. This affects many words in Urdu that have come from Arabic, in particular names and adverbial expressions.
The lām is not pronounced if it precedes one of the following characters:
ت,ث,د,ذ,ر,ز,س,ش,ص,ض,ط,ظ,ل,ن
Instead, the following sound is doubled. A tašdīd may sometimes be used to indicate this.
eg.
السلام علیکم
ال,س,ل,ا,م
Often the alif is not pronounced after a short preceding word that ends in a vowel. If the preceding vowel was long, it is shortened in this process.
eg.
بالکل
فی الحال
Often the vowel is pronounced ʊ.
eg.
دارالحکومت
Consonant sounds to characters
This section maps Urdu consonant sounds to common graphemes in the Arabic orthography.
The right-hand side of each item shows its various joining forms.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
067E067E067E067Econsonantپ
pʰ
067E067E067E067Eپھ
b
0628062806280628consonantب
bʱ
0628062806280628بھ
t
062A062A062A062Aconsonantت
0637063706370637consonantطOnly used in words of Arabic origin.
t̪ʰ
062A062A062A062Aتھ
ʈ
0679067906790679consonantٹ
ʈʰ
0679067906790679ٹھ
t͡ʃ
0686068606860686consonantچ
t͡ʃʰ
0686068606860686چھ
d
062F062Fconsonantد
d̪ʱ
062F062F062F062Fدھ
d͡ʒ
062C062C062C062Cconsonantج
d͡ʒʰ
062C062C062C062Cجھ
ɖ
06880688consonantڈ
ɖʱ
0688068806880688ڈھ
k
06A906A906A906A9consonantک
kʰ
06A906A906A906A9کھ
ɡ
06AF06AF06AF06AFconsonantگ
ɡʱ
06AF06AF06AF06AFگھ
q
0642064206420642consonantق
f
0641064106410641consonantف
v
06480648consonant+vowelوAn allophone of ʋ.
s
0633063306330633consonantس
0635063506350635consonantصUsed in words of Arabic origin.
062B062B062B062BconsonantثUsed in words of Arabic & Persian origin.
z
06320632consonantز
0636063606360636consonantضUsed in words of Arabic origin.
0638063806380638consonantظUsed in words of Arabic origin.
06300630consonantذUsed in words of Arabic & Persian origin.
ʃ
0634063406340634consonantش
ʒ
06980698consonantژ
x
062E062E062E062Econsonantخ
ɣ
063A063A063A063Aconsonantغ
ɦ
06C106C106C106C1consonantہ
062D062D062D062DconsonantحUsed in words of Arabic & Persian origin.
m
0645064506450645consonantم
mʱ
0645 06BE0645 06BE0645 06BE0645 06BEمھ
n
0646064606460646consonant/nasalisation markerن
nʱ
0646 06BE0646 06BE0646 06BE0646 06BEنھ
w
06480648وAn allophone of ʋ commonly occuring between a consonant and vowel.
ʋ
06480648و
ʋʱ
0648 06BE0648 06BEوھ
r
06310631consonantر
ɾ
06310631consonantرAllophone of r that tends to occur between vowels.
rʱ
0631 06BE0631 06BE0631 06BE0631 06BEرھ
ɽ
06910691consonantڑ
ɽʱ
0691 06BE0691 06BE0691 06BE0691 06BEڑھ
l
0644064406440644consonantل
lʱ
0644 06BE0644 06BE0644 06BE0644 06BEلھ
j
06CC06CC06CC06CCconsonant+vowelی
Symbols & other features
Symbol
This is one of the few characters in the presentation forms blocks that is valid for use in normal content.
﷽ is used by Muslims in various contexts including the constitutions of countries where Islam has a significant presence. The shape varies significantly from font to font and usage to usage.
Honorifics
A number of combining marks are used with names as honorifics, eg. قاضی نور محمّدؒqɑẑy nvr mhmᵚdؒkaziː nur mamed rahmatulla alayheQazi Nur Muhammad, may God have mercy upon him! They are combining characters that appear over the name at a point chosen by the author.
◌ؔ,◌ؓ,◌ؒ,◌ؑ,◌ؐ
Formatting characters
The Arabic script uses a number of Unicode characters that affect the way that other characters are rendered. Many of those have no visible form of their own. The following set of characters used in Urdu text does have a visual representation.
Click on the following characters and follow the ↓ links to find out more about them.
,,,,,
Urdu text also makes use of a relatively large set of invisible formatting characters, especially in plain text, many of which are used to manage text direction (see directioncontrols), and others are used to control cursive shaping behaviour (see shapingcontrols).
Encoding choices
In the Urdu orthography different sequences of Unicode characters may produce the same visual result. Here we look at those, and make notes on usage.
Hamza & precomposed characters
Unicode support for the various uses of the hamza is somewhat complicated.u§384 For notes on the usage of the hamza in Urdu, see standalone and izafat.
Canonically equivalent alternatives
A number of combinations with the hamza diacritic can be represented as either an atomic character or a decomposed sequence, where the parts are separated in Unicode Normalisation Form D (NFD) and recomposed in Unicode Normalisation Form C (NFC), so both approaches are canonically equivalent. These include the following:
Atomic
Decomposed
آ
0627 0653
ؤ
0648 0654
ۂ
06C1 0654
ۓ
06D2 0654
The single code point per vowel-sign is the form preferred by the Unicode Standard and the form in common use for Urdu, but either could be found.
Yeh with hamza
This item is a special case. Yeh with a hamza is used in particular for 'hamza on its chair', but also for word medial standalone vowels.
Atomic
Decomposed
ئ
064A 0654
Urdu uses ی and doesn't use ي because the latter produces dots below in all positions, whereas yeh in Urdu only has dots below in initial and medial forms. However, the canonical decomposition of 0626 maps to the Arabicyeh and a combining hamza.
Nevertheless, the atomic character is widely used in Urdu text. To mitigate the issues, the Unicode Standard recommends that any time ي is combined with a hamza the font should drop the dot glyphs. This ensures that the text looks correct in decomposed form, but applications need to be aware that decomposed text will contain an Arabic yeh which is not otherwise used for Urdu.
Glyphs that are not canonically equivalent
The following alternatives are not converted to each other during normalisation. The precomposed characters represent letters in languages such as Pashto, Ormori, and Adamawe Fulfulde where the hamza is an ijam (ie. part of the letter) rather than a combining diacritic. These precomposed characters are therefore not appropriate for use with Urdu.
Decomposed (Recommended)
Atomic (Not recommended)
حٔ
ځ d͡z in Pashto
0631 0654
076C
voiced alveolo-palatal laminal fricative in Ormuri
0628 0654
ࢡ
implosive bilabial stop in Adamawa Fulfulde
The decomposed forms are recommended for use with Urdu. However, if the font supports them, both approaches may yield exactly the same result when displayed, so applications will need to recognise both precomposed and decomposed alternatives as the same grapheme in case users use the precomposed character. Input mechanisms, on the other hand, can produce one rather than the other, and that choice should be made with advisement.
Confusables & spelling errors
The following lists some common errors found in Urdu text due to the similarity of Unicode characters, or perhaps sometimes due to problems inputting the correct character. Wikipedia is a rich source of such.
Correct
Incorrect
Notes
ی
ي
The Arabic YEH doesn't drop the dots below in isolate and final positions. As mentioned above, ي is only found in decomposed text representing yeh with a hamza; in those circumstances the font should not display the dots below.
ہ
ه
Urdu uses heh goal rather than these other types of HEH.
Common fonts tend not to show the difference between these two characters, but the ability to search and compare text is impaired unless the application is aware of and takes counter-measures against this substitution.
The function of this glyph is that of the sukun, so the correct semantic character should be used. Although ٛU+065B VOWEL SIGN INVERTED SMALL V ABOVE looks like the Urdu jazm, as described in the name of the character, it was introduced to Unicode to serve as a vowel sign for African languages §.
Observation: In the Noto Nastaliq Urdu and SIL Awami Nastaliq fonts the sukun is automatically displayed with the inverted-v shape if the language of the content is declared to be Urdu (ur). It is therefore important to ensure that the language of content is correctly declared for web pages if you expect to see this shape.
Codepoint sequences
When typing and in storage, combining marks always follow the base character they are associated with.
Special rendering rules
In principle, if more than one combining mark appears on the same side of the base character, Unicode expects applications to render the marks such that those marks closer to the base character in memory appear closer to the base character when rendered. (This is called the inside-out rule.) However, due to the reordering applied by the Unicode normalisation forms, some of the Arabic script diacritics end up in an inappropriate order on display.
For example, if a user types the sequence of characters in fig_amtra, the order of the marks will be changed such that applying the inside-out rule would render the shadda above the vowel (which is incorrect). (In fact, most application renderers have special rules to correct this.)
The Unicode Standard formally addresses this anomaly in the Technical Annex Unicode® Arabic Mark Rendering (AMTRA), with a set of rules for how to render sequences of Arabic characters. The rules generally move shadda, hamza, round dots, etc. so that they are close to the base character.
User input
Post-normalisation output
بُّ
ب
ّ
ُ
بُ͏ّ
ب
ُ
ّ
A sequence of shadda and damma as the user is likely to input it (left), and how it could potentially be arranged after normalisation (right).
In the rare exceptions where the AMTRA rules should not change the rendering, this can be achieved by placing an invisible 034F character between the combining marks. (In fact, this is what was done to simulate the incorrect appearance in fig_amtra, because otherwise the browser rendering engine would have automatically produced the same output as in the first column. Clicking on the example will show the sequence used.)
Numbers
Urdu may use ASCII digits, or may use the extended arabic-indic digits in the Arabic block.
۰,۱,۲,۳,۴,۵,۶,۷,۸,۹
This is a separate set of characters from those used for Arabic, to accommodate different shaping and directional behaviour. Shapes differ from those of Arabic for the digits 4, 5, and 7.
Persian also uses the same characters for digits, but there are some systematic shape differences between Persian and Urdu for the digits 4, 6, and 7.
Arabic
Persian
Urdu
Sindi
Arabic-indic numerals, as used in Arabic, Persian, Urdu and Sindhi language text.
Urdu also has special characters for the thousands and decimal separators: ٬ and ٫ (see fig_percent_sign), although the ASCII full stop and comma may also be used.
See expressions for a discussion of how to handle numeric ranges.
Percentages
Urdu may use the Arabic percent sign, ٪.
۵٬۴۳۲٫۱٪
The figure 5,432.1% using Urdu characters.
The percent sign is typed and stored after the numbers. Like the numeric sequences using the ASCII hyphen (mentioned in expressions), it will appear to the left of a number if that number is preceded by Urdu characters. However, if the percentage appears alone or at the beginning of a line it is necessary to use an ALM formatting character just before it to prevent the sign appearing on the right.
Observation:Wikipedia uses an ASCII percent sign with ASCII digits
Number sign
Urdu has a sign which can be used to indicate a number. As shown in fig_number_sign, its length varies with the number of digits in the number.
The Arabic number sign runs below the numbers it is used with.
To use this sign, type it before the digits. Even though it displays beneath the digits, it is a formatting character, and not a combining mark.
Dates
؍,ء,ھ,,
Dates in Urdu may be based on the Gregorian calendar or the Hijri calendar. Dates in the Gregorian calendar are followed with this word (usually represented by the abbreviation ء):عیسویʿysvyiːsviːChristian Era
Dates using the Muslim calendar are followed by this word (abbreviated as ھ):ہجریḫʤryhɪʤriː
The word hijri in Arabic is written with ه rather than ہ (see the Urdu spelling just above), and the abbreviation in Arabic is ه, whereas in Urdu it is ھ. Here is the Arabic spelling:
هجري
یکم جمادی الاول 1423 ھ
An Urdu date (12 July 2002) in the Hijri calendar.
Dates may also be indicated by placing the long sweep of below the year digits.
An Urdu date (2014), with a SANAH sign running below it, and a hamza to indicate the Gregorian calendar.
Like the number sign, SANAH is typed before the digits (see fig_sanah). It is not a combining character, even though it displays beneath the digits. The length of the symbol may vary according to the number of digits. It is terminated by a non-digit character.
is another subtending mark, intended to indicate a year in the Śaka calendar.
؍ is used in Urdu between the date and the month nameu§379.
The date in a newspaper masthead, showing the date separator between date and month name in two calendars.
Text direction
Urdu is written horizontally and right-to-left in the main, but (as with most RTL scripts) numbers and embedded LTR script text are written left-to-right (producing 'bidirectional' text).
رکھتا ہے اور 2009ء میں UEFA کپ کے
Urdu words are read right-to-left, starting from the right of this line, but numbers and Latin text are read left-to-right.
The Unicode Bidirectional Algorithm automatically takes care of the ordering for all the text in fig_bidi, as long as the 'base direction' (ie. the surrounding directional context) is set to right-to-left (RTL).
Characters are all stored in the order in which they are spoken (and typed). This so-called 'logical' order is then rendered as bidirectional flows by the application at run time, as the text is displayed or printed. The relative placement of characters within a single directional flow is based on strong directional properties (RTL or LTR) assigned to each Unicode character by the Unicode Standard. There exist, however a set of neutral direction property values, mostly for punctuation, where the placement of characters depends on the base direction.
If the base direction is not set appropriately, the directional runs will be ordered incorrectly as shown in fig_bidi_no_base_direction, making it very difficult to get the meaning.
رکھتا ہے اور 2009ء میں UEFA کپ کے
رکھتا ہے اور 2009ء میں UEFA کپ کے
The exact same sequence of characters with the base direction set to RTL (top), and with no base direction set on this LTR page (bottom).
In some circumstances the Unicode Bidirectional Algorithm requires additional assistance to correctly render the directionality of bidirectional text. For such cases the Unicode Standard provides invisible formatting characters for use in plain text. See directioncontrols.
In HTML the base direction and higher level controls can be set using the dir or bdi attributes. CSS should not be used to control direction. Unicode formatting codes should also not be used where markup is available.
For authoring HTML pages, one of the most important things to remember is to use <html dir="rtl" … > at the top of a right-to-left page, and then use the dir attribute or bdi tag for ranges within the page, but only when you need to change the base direction. Also, use markup to manage direction, and do not use CSS styling.
For other aspects of dealing with right-to-left writing systems see the following sections:
Unicode provides a set of 10 formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction of a range of characters. RLE/LRE come at the start, and PDF at the end of a range of characters for which the base direction is to be set.
More recently, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2069 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
061C (ALM) is used to produce correct sequencing of numeric data. Follow the link and see expressions for details.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
A sequence of numbers separated by hyphens (for example a range) runs from right to left in Urdu.
fig_range shows some Urdu text, which is right-to-left overall, containing a numeric range that is also ordered RTL, ie. it starts with 100 and ends with 999.
100–999 تصدیق شدہ کیس
A numeric range in Urdu language text.
When a list uses the ASCII hyphen as a separator, the Unicode Bidirectional Algorithm automatically produces the expected ordering only when a sequence or expression follows Urdu characters. However, a sequence that appears alone on a line will be ordered left-to-right. To make the sequence read right-to-left you should, in this case, add the formatting character 061C (ALM) at the start of the line (see and click on each line in fig_ALM).
10-01-2018
10-01-2018
A numeric date alone on a line of RTL text, with ALM before it (top), and without (bottom). (Click on each line to see the code points.)
Note that the required order cannot be achieved by simply setting the base direction, nor by using 200F.
Alternatively, you could use a different separator, such as – (as in fig_range) or ‐U+2010 HYPHEN. No special arrangements are then necessary.
Similar RTL ordering is applied to numbers in equations, such as 1 + 2 = 3, for Urdu language text.
This section brings together information about the following topics:
font/writing styles;
cursive text;
context-based shaping;
context-based positioning;
letterform slopes, weights, & italics;
case & other character transforms.
You can experiment with examples using the Urdu workbench.
The orthography has no case distinction, and no special transforms are needed to convert between characters.
Typographic styles
Urdu is normally written in a nasta'liq writing style. Key features include a sloping baseline for joined letters, and overall complex shaping and positioning for base letters and diacritics alike. There are also distinctive shapes for many glyphs and ligatures.
مستحقشخصکیفیت
Three words illustrating sloping baselines and complex joining behaviours in Urdu nastaliq text.
This is achieved in Unicode by applying the correct font – the underlying characters used are not different for nasta'liq vs. other styles.
کوئی شخص محض حاکم کی مرضی پر اپنی قومیت سے محروم نہیں کیا جائے گا اور اس کو قومیت تبدیل کرنے کا حق دینے سے انکار نہ کیا جائے گا۔
Urdu is normally written in the nasta'liq writing style.
کوئی شخص محض حاکم کی مرضی پر اپنی قومیت سے محروم نہیں کیا جائے گا اور اس کو قومیت تبدیل کرنے کا حق دینے سے انکار نہ کیا جائے گا۔
The same text, written in a standard naskh writing style.
Not only does the baseline slope for connected glyphs in a word, but the sloping sequences can overlap, as shown in fig_overlap, which uses the Awami Nastaliq font.
Sloping baselines and complex joining behaviours in Urdu nastaliq text.
Cursive script
Arabic script joins letters together. Fonts need to produce the appropriate joining form for a code point, according to its visual context. This results in four different shapes for most letters (including an isolated shape). The highlights in fig_cursive below show the same letter, ع, with two different joining forms.
The letter ع in 2 different joining contexts.
A few Arabic script letters only join on the right-hand side.
There are 2 Unicode blocks containing Arabic presentation forms: these contain individual characters corresponding to the various joining forms and ligatures. With only a handful of exceptions, characters in those blocks should not be used for text content; they are only for managing legacy encodings. Instead, characters in the main Arabic block should be used, and the font will manage the necessary cursive shaping.
Cursive joining forms
Most dual-joining characters add or become a swash when they don't join to the left. A number of characters, however, undergo additional shape changes across the joining forms. fig_joining_forms and fig_right_joining_forms show the basic shapes in Urdu and what their joining forms look like.
Two pairs of characters in the first table have base shapes that are identical, but they manage the dots differently in different joining forms. These have been put onto separate rows.
isolated
right-joined
dual-join
left-joined
Urdu letters
ب
ـب
ـبـ
بـ
ب,ت,ث,پ,ٹ
ن
ـن
ـنـ
نـ
ن
ں
ـں
ـںـ
ںـ
ں
ق
ـق
ـقـ
قـ
ق
ف
ـف
ـفـ
فـ
ف
س
ـس
ـسـ
سـ
س,ش
ص
ـص
ـصـ
صـ
ص,ض
ط
ـط
ـطـ
طـ
ط,ظ
ک
ـک
ـکـ
کـ
ک,گ
ل
ـل
ـلـ
لـ
ل
ہ
ـہ
ـہـ
ہـ
ہ,ۂ
ھ
ـھ
ـھـ
ھـ
ھ
م
ـم
ـمـ
مـ
م
ع
ـع
ـعـ
عـ
ع,غ
ح
ـح
ـحـ
حـ
ح,خ,ج,چ
ی
ـی
ـیـ
یـ
ی
ئ
ـئ
ـئـ
ئـ
ئ
Joining forms for shapes that join on both sides.
isolated
right-joined
Urdu letters
ا
ـا
ا,آ
ر
ـر
ر,ڑ,ز,ژ
د
ـد
د,ڈ,ذ
و
ـو
و,ؤ
ے
ـے
ے
Joining forms for shapes that join on the right only.
Managing glyph shaping
200D (ZWJ) and 200C (ZWNJ) are used to control the joining behaviour of cursive glyphs. They are particularly useful in educational contexts, but also have real world applications.
ZWJpermits a letter to form a cursive connection without a visible neighbour. It can be used for illustrating cursive joining forms.
eg.
ان س ان
Characters from the Presentation Forms blocks in Unicode should not be used in such cases.
ZWNJprevents two adjacent letters forming a cursive connection with each other when rendered.
eg.
انسان
034F is used in Arabic to produce special ordering of diacritics. The name is a misnomer, as it is generally used to break the normal sequence of diacritics.
Context-based shaping & positioning
Context-based shaping is everwhere in Urdu due to the combination of the cursive behaviour of the script plus the strong tendency to arrange joined characters in cascades or vertical arrangements.
As in Arabic, lam followed by alef ligates.
اسلام
and there are other such commonly ligated forms. There are also common rules about special joining arrangements when certain characters appear side by side, for example a KA followed by an ALEF takes the special shape
کا
Positioning of cursive joining forms is already complicated in the nastaliq style because of the vertical placement; adding dots and hamzas then complicates matters in that they need to be aligned with the appropriate base character without overlapping adjacent character glyphs or other dots, etc. Positioning vowel diacritics, shadda, etc. then adds to the complexity.
The table in fig_gpos selects just a handful of situations to illustrate the kinds of positioning that take place.
nastaliq
naskh
notes
A
حیثیت
حیثیت
A relatively straightforward arrangement, except for the positioning (and context-based shaping) required to achieve the sloping baseline.
B
ویکیپیڈیا
ویکیپیڈیا
Here, the dots have been arranged vertically so that they don't crash into each other. More radical arrangements of this kind will be seen in the following examples.
C
پیٹی اؔبِیجیل
A similar situation, where additional horizontal and vertical spacing has been applied in order to allow room for the dots and other diacritics to appear without crashing into other glyphs or dots, etc.
D
چاہیئے
چاہیئے
It is common for diacritics of characters preceding BAREE HEH to be rendered below the latter character's glyph. Here we see part of both an initial HEH and the 2 dots of aYEH separated from the other glyphs that make up those characters.
E
تصدیق
تصدیق
In this word, the 2 dots below the YEH create most of the horizontal space between the preceding DAL and following QAF. In the Nafees Nastaleeq font, the 2 dots are moved below and slightly under the QAF, reducing the overall horizontal with of the word.
F
اسلام
اسلام
Note the convention that the word-final MEEM here starts above the baseline, even though nothing follows it.
G
دلچسپی
A highly vertical arrangement using the Nafees Nastaleeq font, where dots are stacked together. In the Awami and Noto nastaliq fonts this looks less vertical, ie. دلچسپی
Examples of glyph positioning in the nastaliq style.
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
tbd
Punctuation & inline features
Phrase & section boundaries
Urdu uses a mixture of ASCII and Arabic punctuation.
phrase
،
؛
:
sentence
۔
.
؟
!
poetry
؎
؏
معاشرے، … پڑے گا۔
Urdu text using an Arabic comma, and an Arabic full stop.
Poetry
In poetry, ؎ is used to mark the beginning of poetic verse, and ؏ is used to indicate a single line (misra) of a couplet (shayr) from an Urdu poem, when quoted in text. It is used at the beginning of the line, and is followed by the line of verse. For more information and examples, follow the links on the character names.
Bracketed text
Urdu commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Mirrored characters
The words 'left' and 'right' in the Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use > [U+003E GREATER-THAN SIGN], but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some more common ones.
The following type of quotation mark can be found in Urdu texts.
(Of course, depending on ease of input, quotations may also be surrounded by ASCII double and single quote marks.)
start
end
primary
”
“
Unlike brackets, these quote marks are notmirrored during display. As a result, LEFT means use on the left, and RIGHT means use on the right.
Line & paragraph layout
Line breaking & hyphenation
Basic line-break opportunities occur between the space-separated words.
They are not broken at the small gaps that appear where a character doesn't join on the left.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for characters affected by these rules. Context may affect the behaviour of some of these and other characters.
« “ ‘ ( should not be the last character on a line
» ” ’ ) ۔ . ، ؛ ؟ ! should not begin a new line
Breaking between Latin words
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines upwards.
latin-line-breaks shows how two Latin words are apparently reordered in the flow of text to accommodate this rule. Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
Urdu with embedded Latin text. The lower of these two images shows the result of decreasing the line width, so that text wraps between a sequence of Latin words.
Text alignment & justification
Calligraphic justification It is difficult to find information in English about justification of Urdu text in a nastaliq font. The following information is from Asad et al.ma, and is based on studies of calligraphy. It's not clear that it is currently possible to achieve the results described in web pages.
Interword spacing is only used as a last resort for Urdu justification. It is also noteworthy that, unlike it use in Arabic language text,
0640
is not used, and moreover is not even functional in some fonts. For example, it is completely ignored by Noto Nastaliq Urdu, and while it actually produces a glyph for Awami Nastaliq, it doesn't join with adjacent characters.
According to Asad et al. there are 2 main ways to deal with justification: by stretching certain letter shapes (to increase line width), or by positioning some letters above the word they appear in (to decrease line width). Some of the examples they use, such as fig_justification include both.
An example of a justified Urdu line from Asad et al.
The rules about which letters can be stretched or repositioned, and when, and how, are somewhat complex. For some additional detail, see Asad et al, page 594ff (page 4 in the PDF). Some letters are never stretched, and others only stretched in certain positions within a word. Given those constraints, it is then necessary to apply rules about which of the set of available letters to stretch within a word and across a line in order to achieve the desired line length.
Other rules or judgement calls are also involved.
Variations in stroke thickness between adjacent letters contribute to decisions about how to stretch letters.
In some contexts, such as poetry, all lines may be stretched at the same location in the line.
Given that there is usually only one stretched letter per word, certain letters are prioritised over others for stretching, based on how commonly they are stretched.
The last line in a paragraph of ordinary text is never normally stretched, however a final line in a poem is likely to be stretched.
Newspaper justificationfig_justification_newspaper shows part of a column from a newspaper. The majority of columns in the newspaper are fully justified, but don't employ the stretching and positioning techniques described just above. Instead, they appear to use inter-word spacing. Note that very little spacing tends to be needed, given that Urdu words are usually short and the diagonal baseline and glyph shaping tend to further reduce the amount of horizontal space taken by a word. This means that it is relatively easy to fit approximately the right number of words on a line before applying the additonal spacing needed.
An example of a fully justified column of Urdu newspaper content.
Text spacing
tbd
This section looks at ways in which spacing is applied between characters over and above that which is introduced during justification.
Complex, two-dimensional arrangements of letters in words are common in newspaper titles. See fig_newspaper_titles. They are normally created by hand.
Complex arrangements of characters in a newspaper heading.
Baselines, line height, etc.
The alphabetic baseline is a strong feature of Arabic script on the whole, since characters tend to join there. The nastaliq style of the script, on the other hand, uses arrangements of joined glyphs that cascade downwards from right to left, and ressemble a strongly sloping baseline. See the examples in fig_baseline and fig_gpos.
fig_overlap shows overlapping baselines in the Nafees Nastaliq font. (In the Awami and Noto fonts, there is no overlap for that text.)
This cascading effect can lead to a need for quite large line height settings, compared to many other orthographies.
An example of a cascade that requires a large line height.
fig_baselines shows Urdu text glyphs from the Noto Serif and Noto Nastaliq Urdu fonts compared to the basic metrics of Latin text. The figure clearly shows the potential differences in line height requirements for the two scripts.
Font metrics of Latin text the Noto Serif compared with text in the Noto Nastaliq Urdu font. Both fonts have the same font size.
Page & book layout
Notes, footnotes, etc
See inlinenotes for purely inline annotations, such as ruby or warichu. This section is about annotation systems that separate the reference marks and the content of the notes.
is used to indicate that a number is a reference to a footnote. The number sits above the symbol, although this is not a combining character. The marker should come before the number in logical order, eg. ؎۵.
(Note that, although it looks very similar, this is not the same character as ؎.)