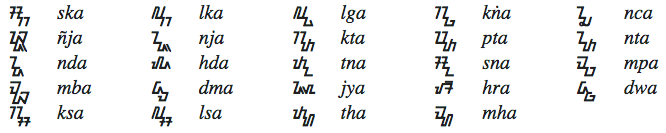
ᮀ
ŋ as a syllable-final sound, eg. ᮙᮀᮌᮥ
`, '\u{1B81}': `ᮁ
r as a syllable-final sound, eg. ᮕᮞᮤᮁ
`, '\u{1B82}': `ᮂ
h as a syllable-final sound, eg. ᮃᮘᮂ-ᮃᮘᮂ
`, '\u{1B83}': `ᮃ
There is no corresponding vowel sign, since this is the inherent vowel.
a independent vowel.
ᮃᮊ᮪ᮞᮛ
ᮘᮤᮃᮀ
`, '\u{1B84}': `ᮄ
i independent vowel.
ᮄᮛᮠ
ᮎᮎᮄ
`, '\u{1B85}': `ᮅ
u independent vowel.
ᮅᮔᮤᮍ
ᮒᮅᮔ᮪
`, '\u{1B86}': `ᮆ
e independent vowel.
ᮆᮜ᮪ᮙᮥ
ᮞᮆ
`, '\u{1B87}': `ᮇ
o independent vowel.
ᮇᮛᮚ᮪
ᮔᮇᮔ᮪
`, '\u{1B88}': `ᮈ
ə independent vowel.
ᮈᮙᮞ᮪
`, '\u{1B89}': `ᮉ
ɤ independent vowel.
ᮈᮙᮞ᮪
ᮞᮩᮉᮁ
`, '\u{1B8A}': `ᮊ
k consonant.
ᮊᮥᮜ᮪ᮊᮞ᮪
ᮃᮏᮊ᮪
`, '\u{1B8B}': `ᮋ
q consonant for writing foreign words.
`, '\u{1B8C}': `ᮌ
ɡ consonant.
ᮌᮥᮌᮥᮊ᮪
ᮃᮓᮨᮌ᮪
`, '\u{1B8D}': `ᮍ
ŋ syllable-initial consonant.
ᮍᮙᮔᮂ
ᮜᮍᮣᮚᮍᮔ᮪
`, '\u{1B8E}': `ᮎ
t͡ʃ consonant.
ᮎᮥᮎᮥᮒ᮪
ᮊᮥᮎᮥᮁ
`, '\u{1B8F}': `ᮏ
d͡ʒ consonant.
ᮏᮏᮔ᮪ᮒᮥᮀ
ᮝᮔᮧᮏ
`, '\u{1B90}': `ᮐ
Used for writing foreign words.
`, '\u{1B91}': `ᮑ
ɲ consonant.
ᮑᮔ
ᮛᮤᮑᮥᮂ
`, '\u{1B92}': `ᮒ
t consonant.
ᮒᮅᮔ᮪
ᮃᮀᮊᮒ᮪
`, '\u{1B93}': `ᮓ
d consonant.
ᮓᮜᮤᮀᮓᮤᮀ
ᮘᮥᮜᮩᮓ᮪
`, '\u{1B94}': `ᮔ
n consonant.
ᮔᮇᮔ᮪
ᮓᮤᮔ᮪ᮒᮨᮔ᮪
`, '\u{1B95}': `ᮕ
p consonant.
ᮕᮔᮧᮔ᮪ᮕᮧᮆ
ᮊᮨᮎᮕ᮪
`, '\u{1B96}': `ᮖ
f consonant for writing foreign words.
ᮍᮖᮥᮀᮞᮤᮊᮩᮔ᮪
`, '\u{1B97}': `ᮗ
v consonant for writing foreign words.
`, '\u{1B98}': `ᮘ
b consonant.
ᮘᮥᮃᮂ
ᮞᮃᮘ᮪
`, '\u{1B99}': `ᮙ
m consonant.
ᮙᮛᮩᮙᮔ᮪
ᮄᮊᮣᮤᮙ᮪
`, '\u{1B9A}': `ᮚ
j consonant.
ᮙᮛᮩᮙᮔ᮪
ᮜᮍᮣᮚᮍᮔ᮪
For medial -j- use ᮡ [U+1BA1 SUNDANESE CONSONANT SIGN PAMINGKAL].
`, '\u{1B9B}': `ᮛ
r syllable-initial consonant.
ᮛᮔ᮪ᮏᮀ
ᮞᮛᮨᮀ
For syllable-final -r use ᮁ [U+1B81 SUNDANESE SIGN PANGLAYAR]. And for medial -r- use ᮢ [U+1BA2 SUNDANESE CONSONANT SIGN PANYAKRA].
`, '\u{1B9C}': `ᮜ
l syllable-initial consonant.
ᮜᮍᮤᮒ᮪
ᮎᮨᮕᮤᮜ᮪
For medial -l- use ᮣ [U+1BA3 SUNDANESE CONSONANT SIGN PANYIKU].
`, '\u{1B9D}': `ᮝ
w syllable-initial consonant.
ᮝᮠᮍᮔ᮪
ᮓᮝᮥᮂ ᮊᮤᮝᮛᮤ
`, '\u{1B9E}': `ᮞ
s consonant.
ᮞᮔᮦᮞ᮪
ᮕᮥᮞ᮪ᮕ
`, '\u{1B9F}': `ᮟ
ks consonant for writing foreign words.
`, '\u{1BA0}': `ᮠ
h syllable-initial consonant.
ᮠᮜᮩᮀᮠᮩᮙ᮪
ᮊᮥᮙᮠ
`, '\u{1BA1}': `ᮡ
-j- medial consonant.
`, '\u{1BA2}': `ᮢ
-r- medial consonant.
ᮃᮌᮢᮤᮊᮥᮜ᮪ᮒᮥᮁ
`, '\u{1BA3}': `ᮣ
-l- medial consonant.
ᮄᮊᮣᮤᮙ᮪
`, '\u{1BA4}': `ᮤ
i vowel sign.
ᮊᮤᮝᮛᮤ
ᮠᮤᮏᮤ
`, '\u{1BA5}': `ᮥ
u vowel sign.
ᮊᮒᮥᮠᮥ
ᮘᮥᮘᮥ
`, '\u{1BA6}': `ᮦ
ɛ~e vowel sign, displayed to the left of the base character.
ᮊᮦᮜᮦᮊ᮪
ᮘᮦᮛᮦ
ᮘᮔ᮪ᮓᮦᮛ
ᮙᮥᮒᮦ
`, '\u{1BA7}': `ᮧ
ɔ~o vowel sign.
ᮠᮧᮚᮧᮀ
ᮊᮧᮘᮧᮀ
ᮊᮧᮊᮧᮛᮧ
ᮕᮧᮆ
`, '\u{1BA8}': `ᮨ
ə vowel sign.
ᮕᮨᮜᮨᮀᮊᮥᮀ
ᮃᮍᮨᮔ᮪
`, '\u{1BA9}': `ᮩ
ɤ~ɨ vowel sign.
ᮊᮩᮠᮩᮜ᮪
ᮓᮩᮄ
ᮘᮩᮍᮩᮒ᮪
ᮃᮛᮩᮚ᮪
`, '\u{1BAA}': `᮪
Visible indicator of a killed vowel, eg. ᮃᮊ᮪ᮞᮛ
`, '\u{1BAB}': `᮫
Not used in modern Sundanese.
When reproducing the older orthography this can be used to create conjuncts like any other virama. The following shows known conjuncts.
ᮬ
Not used in modern Sundanese.
When reproducing the old orthography this can be used to represent a medial m (like ၟ [U+105F MYANMAR CONSONANT SIGN MON MEDIAL MA]). It contrasts with a subjoined m produced with the virama.
`, '\u{1BAD}': `ᮭ
Not used in modern Sundanese.
When reproducing the old orthography this can be used to represent a medial w that contrasts with a subjoined w produced with the virama.
`, '\u{1BAE}': `ᮮ
Used for writing Arabic خ.
ᮮᮥᮯᮥ
Not widely used.
`, '\u{1BAF}': `ᮯ
s for writing Arabic ش.
ᮮᮥᮯᮥ
Not widely used.
`, '\u{1BB0}': `᮰
`, '\u{1BB1}': `᮱
`, '\u{1BB2}': `᮲
`, '\u{1BB3}': `᮳
`, '\u{1BB4}': `᮴
`, '\u{1BB5}': `᮵
`, '\u{1BB6}': `᮶
`, '\u{1BB7}': `᮷
`, '\u{1BB8}': `᮸
`, '\u{1BB9}': `᮹
`, '\u{1BBA}': `ᮺ
Not used in modern Sundanese.
In older Sundanese orthography it kills the vowel of a preceding consonant but introduces a hiatus before an initial a-, eg. ᮃᮜᮥᮔᮺᮌᮥᮀ
This could also be written as two words, ie. ᮃᮜᮥᮔ᮪ ᮃᮌᮥᮀ ạlunˣ ạguŋ̽
`, '\u{1BBB}': `ᮻ
rɤ vocalic. Not used with modern Sundanese, where this syllable is written ᮛᮩ rɤ
In reproductions of the old orthography this can be used for rɤ
`, '\u{1BBC}': `ᮼ
lɤ vocalic. Not used with modern Sundanese, where this syllable is written ᮜᮩ lɤ
In reproductions of the old orthography this can be used for lɤ
`, '\u{1BBD}': `ᮽ
A symbol found on the Prasasta Kawali (the oldest inscribed stone containing Sundanese text).
`, '\u{1BBE}': `ᮾ
Final -k. Not used with modern Sundanese, where this is written ᮊ᮪ k
Can be used for reproductions of the old orthography as it was written on palm leaf manuscripts.
`, '\u{1BBF}': `Final -m. Not used with modern Sundanese, where this is written ᮙ᮪ m
Can be used for reproductions of the old orthography as it was written on palm leaf manuscripts.
`, '\u{1CC0}': `᳀
᳁
Used in Old Sundanese. Can represent a full stop.
Also used as part of ᳆᳀᳆ to denote a religious text.
It represents the sun.
`, '\u{1CC1}': `Used in Old Sundanese. As part of the sequence ᳆᳁, this helps indicate that the source is a religious text.
It represents a half moon.
`, '\u{1CC2}': `᳂
Used in Old Sundanese. Used to represent a comma when ᳀ [U+1CC0 SUNDANESE PUNCTUATION BINDU SURYA] is used as a full stop.
As part of the sequence ᳅᳂᳅ this indicates that the source is a historical text.
It represents a full moon.
`, '\u{1CC3}': `᳃
Otherwise ᳃ [U+1CC3 SUNDANESE PUNCTUATION BINDU CAKRA] may be used as a comma in older texts.
`, '\u{1CC4}': `᳄
The meaning of this sign is not clear. It appears in Old Sundanese manuscripts.
`, '\u{1CC5}': `᳅
As part of the sequence ᳅᳂᳅ this indicates that the source is a historical text.
`, '\u{1CC6}': `᳆
When used as part of ᳆᳀᳆ in religious texts.
`, '\u{1CC7}': `᳇
When used as part of ᳇᳇ in religious texts.
`, '\u{0021}': `!
Exclamation mark.
`, '\u{0028}': `(
Parenthesis.
`, '\u{0029}': `)
Parenthesis.
`, '\u{002C}': `,
Comma.
`, '\u{002E}': `.
Full stop.
`, '\u{003A}': `:
Colon.
`, '\u{003B}': `;
Semicolon.
`, '\u{003F}': `?
Question mark.
`, '\u{007C}': `|
Number delimiter.
`, '\u{2018}': `‘
Quotation mark.
`, '\u{2019}': `’
Quotation mark.
`, '\u{201C}': `“
Quotation mark.
`, '\u{201D}': `”
Quotation mark.
`, }