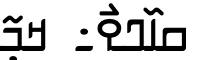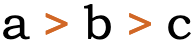This page brings together basic information about the N’Ko script and its use for a koiné register of Manding. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write N’Ko using Unicode.
Given that individual speakers apply their own local pronunciations to the N’Ko written text, the phonological transcriptions here are more like transliterations of the N’Ko, using Latin letters typically employed for the Manding languages.
N’Ko ( ߒߞߏ ) is a script used mainly in Guinea and Côte d'Ivoire (respectively by Maninka and Dyula speakers), and an active user community in Mali (by Bamanan speakers). Publications include a translation of the Quran, a variety of textbooks on subjects such as physics and geography, poetic, and philosophical works, descriptions of traditional medicine, a dictionary, and several local newspapers.
The name is also used for a literary (as opposed to spoken) language written in that script, which is intended as a koiné, blending elements of the principal Manding languages (which are mutually intelligible), but has a very strong Maninka flavour. The term N’Ko means I say in all Manding languages. The koiné language is understandable by all literate Manding speakers and is used in situations where speakers of different Manding languages need a neutral means of communication
The script was devised by Sùlemáana Kántɛ in 1949, as a writing system for the Manding languages of West Africa.
In 1986 l’Association pour l’Impulsion et la Coordination des Recherches sur l’Alphabet N’ko (ICRA-N’KO) was established, and officially approved as an NGO for the promotion of N’Ko five years later.
Unicode 17 has 1 dedicated N’Ko block, comprising 62 characters.
As mentioned above, N’Ko is a literary orthography that is tied to a standard or common Manding dialect which has arisen as a result of the contact, mixing, and often simplification of the various distinct, but mutually intelligible, varieties of Manding. This koiné may be referred to as Kangbe (kãɡ͡be).
“When Mandens from different sub-groups talk to each other, it is common practice for them to switch, consciously or sub-consciously, from one's own dialect to a conventional dialect known as N’Ko or Kangbe (the clear language). This is even true, sometimes, during conversations between the Bamanans of Mali, the Maninka-Moris of Guinea, and the Maninkos of Gambia or Senegal although pronunciations are practically the same. As an example, the word “Name” in Bamanan is “Toko” and in Maninka it is “Toh”. In written communications each will write it as Tô (ߕߐ߮) in N’Ko, and yet read and pronounce it differently.”nfb
Additionally, N’Ko reduces different phones into a single grapheme. For example, when writing Bamanan the following words are all spelled differently in the Latin orthography, reflecting the different pronunciations, but are spelled using the same letter in N’Ko:
Bamanan
N’Ko
jɛ́
ߜߍ߫
gɛ̀lɛn
ߜߍ߬ߟߍ߲߬
woló
ߜߏ߬ߟߏ
The letter ߜ used for 3 words that are spelled differently in Bamanan written in Latin script. (Source, Donaldson, p207)
The N’Ko script is an alphabet, ie. all vowels are written explicitly, alongside consonants; there is no inherent vowel in a consonant (abugidas), certain vowels are not systematically dropped (abjads), and consonant and vowel are not combined in the same character (syllabaries).
N’Ko doesn't have corresponding letters for g, ŋ, and z used in the Latin orthographies of Manding languages. Also, plurals that are written by appending a w to a word in Bamanan are generally written in N’Ko by adding a free-standing particle such as ߟߎ߬lù or ߠߎ߬nù.
An unusual feature is that if two adjacent consonants are followed by the same vowel, the vowel is omitted after the first consonant.
Vowel absence A letter is used to indicate the absence of a vowel, and it is used regularly, since it disambiguates situations where a repeated vowel is omitted.
NumbersN’Ko has it's own set of digits, which are (unusually) written right-to-left.
LayoutN’Ko script is written right-to-left in horizontal lines. Unlike other RTL scripts, such as Arabic and Hebrew, numbers are also written right-to-left. Words are separated by spaces.
The script is normally cursive, but in certain circumstances a non-joining font style may be used.
Punctuation is a mixture of Arabic and native characters.
Notable features
numbers as well as text are read right to left
vowel length and tone diacritics are merged
when two adjacent consonants are followed by the same vowel the vowel is omitted after the first consonant
tonal apostrophes retain tone information for elided vowels
abstract consonants for allophonic variants n and ɲ
lack of vowels between consonants is represented using a spacing letter
a nasal syllabic letter
Character index
Letters
Show
Consonants
ߔ,ߓ,ߕ,ߘ,ߗ,ߖ,ߞ,ߜ,ߝ,ߛ,ߤ,ߡ,ߣ,ߢ,ߥ,ߙ,ߚ,ߟ,ߦ
Nasal syllabic
ߒ
Vowels
ߊ,ߋ,ߌ,ߍ,ߎ,ߏ,ߐ,ߑ
Other
ߴ,ߵ,ߠ,ߧ,ߺ
Not used for N’Ko
ߨ,ߩ,ߪ
Combining marks
Show
Tones
߫,߬,߭,߮,߯,߰,߱
Other
߲,߳,߽
Numbers
Show߀,߁,߂,߃,߄,߅,߆,߇,߈,߉
Punctuation
Show߸,߹,߷,⸜,⸝,،,؛,؟,﴾,﴿,«,»
ASCII
(,),[,],.,:
Symbols
Show߶,߾,߿
Other
Show,,,,,,,,,,
To be investigated
͏,,٪,,‑,–,—,‘,’,“,”,…,‹,›,
Items to show in lists
Phonology
These are sounds covered by the N’Ko script. Because N’Ko provides a standardised written form, but allows speakers of different dialects to pronounce words differently, the application of these sounds to graphemes is not cut and dry.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones.
Vowel sounds
Consonant sounds
labial
alveolar
post-
alveolar
palatal
velar
glottal
stop
pb
td
k
affricate
t͡ʃd͡ʒ
fricative
f
s
h
nasal
m
n
ɲ
ŋ
approximant
w
l
j
trill/flap
r
Tone
Manding languages have two basic tones, high and low. A low-high combination (rising) may also occur with short and long vowels, and a high-low combination (falling) with long vowels.ws
Structure
tbd
Vowels
ߌ, ,ߎ߳, ,ߎߋ, ,ߏߋ߳ߍ, ,ߐߊ,ߊ߳
Each of the following can carry a tone mark and a nasalisation mark which are not shown here. The choice of tone mark also indicates whether the vowel is long or short. See tones.
Post-consonant vowels
Vowels that follow consonants are written using 7 letters. ߳U+07F3 NKO COMBINING DOUBLE DOT ABOVE is used above N’Ko letters to represent 3 foreign sounds (particularly from French and Arabic). Another diacritic produces nasalisation of the vowel sound.
N’Ko has 7 combining marks that convey vowel length and tone at the same time.
Basic vowels
N’Ko has 7 vowel letters to represent the 7 basic vowel sounds.
ߌ,ߎ,ߋ,ߏ,ߍ,ߐ,ߊ
Extended vowels
07F3 is used above N’Ko letters to represent 3 foreign sounds (particularly from French and Arabic).
The low diacritic 07F2 is applied to a vowel to indicate nasalisation.
eg.
ߟߊߡߌ߲߬
A nasalisation mark attached to a letter that already has a combining character.
Use of a nasalisation mark may cause multiple combining marks to be attached to a single base character. The nasalisation mark should be typed and stored before any tone mark to preserve the canonical order.u
Composite vowel signs
Three vowels are represented by more than one character. These are the combinations of letter plus the diaeresis-like diacritic that is used to extend the repertoire to cover sounds from other languages. See the basicV.
Zero-onset vowels are written using ordinary vowel letters and require no special arrangements.
eg.
ߊߡߌ߯ߣߊ߫
ߍߛߑߞߌߡߏߞߊ
Tones & vowel length
߫,߯,߬,߰,߭,߱,߮
In the N’Ko orthography, each of the above diacritics indicates both vowel length and tone. Manding languages have two basic tones, high and low. A low-high combination may also occur with short and long vowels, and a high-low combination with long vowels.ws
short
long
ˊ
high
07EB
07EF
ˋ
low
07EC
07F0
ˇ
rising
07ED
07F1
ˆ
falling
07EE
Tone diacritics in N’Ko.
eg.
ߖߛߎ߬ߘߐ߬ߗߍ߫
ߢߐ߯ߡߍ
ߞߏ߬ߝߊ߮
Tone marks should be typed and stored after any nasalisation marker.
Several of these diacritics are also used over consonants to extend the repertoire when translitering foreign sounds (see extendedC).
Although some of the N’Ko diacritics look like those in general use with the Latin script, the ones provided in this block are typically drawn higher and bolder, and have a wider range of glyph variation.u
This section maps N’Ko vowel sounds to common graphemes in the N’Ko orthography.
N’Ko is unusual in that it expresses vowel length using the same diacritic as used for tone. See the section lower down for how to produce these combinations.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
Plain vowels
i
vowelߌ
ĩ
vowelߌ߲
y
vowelߎ߳
u
vowelߎ
ũ
vowelߎ߲
e
vowelߋ
ẽ
vowelߋ߲
o
vowelߏ
õ
vowelߏ߲
ǝ
vowelߋ߳
ɛ
vowelߍ
ɛ̃
vowelߍ߲
ɔ
vowelߐ
ɔ̃
vowelߐ߲
a
vowelߊ
ã
vowelߊ߲
ʕa
vowelߊ߳
Tones & vowel length
The key used for these entries is a, but the diacritics are used with other vowels, too.
˦
tone mark߫
tone mark߯
˨
tone mark߬
tone mark߰
˨˦
tone mark߭
tone mark߱
˦˨
no markeg. ߓߊ
tone mark߮
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
An absence of vowels between two consonants can be indicated using ߑu. However, this is not often needed, given that Manding words are normally composed of CV syllables, and is used in words from other languages.
eg.
ߍߛߑߞߌߡߏߞߊ
ߛߑߔߌߣߏߖ߭ߊ߫
However, when writing N’Ko, when two adjacent consonants are followed by the same vowel the vowel is omitted after the first consonantu.
eg.
ߛߓߊ߬
ߛ,ߓ,ߊ߬
ߓߙߋ
ߓ,ߙ,ߋ
This does not happen, however, if the two consonants are the samecd§xvii.
eg.
ߝߊߝߊ
There is no ambiguity here with regards to consonant clusters, since in the case of a cluster ߑ would appear between the two letters. The following example is pronounced with the vowel after the first letter, even though none is present, because of the vowel letter omission rule explained above.
ߓߟߏblobolo
To show that this should be pronounced without the vowel you need the following.u
ߓߑߟߏbˣloblo
Tonal apostrophes
Mande languages commonly elide a word-final vowel that precedes another vowel. The elided vowel is replaced by an apostrophe.
eg.
í bɛ́ à fɔ́ → í bʼà fɔ́
N’Ko has two apostrophes, 07F4 and 07F5, that are used to indicate elision, but which preserve information about the tone of the elided vowel.cd§xvi
eg.
ߌ ߓߴߊ߬ ߝߐ߫
ߌ ߞߵߊ߬ ߝߐ߫
The height relative to the baseline can vary.
Consonants
Basic
Extended
ߔ,ߓ,ߕ,ߘ,ߞ
ߓ߭,ߕ߭,ߙ߳,ߘ߭,ߜ߭,ߞ߫
ߗ,ߖ,ߜ
ߜ߳
ߝ,ߛ,ߤ
ߝ߭,ߛ߳,ߗ߭,ߖ߭,ߛ߫,ߖ߳,ߛ߭,ߗ߭,ߜ߫,ߞ߭,ߤ߭
ߡ,ߣ,ߢ
ߡ߭,ߢ߭
ߥ,ߙ,ߚ,ߟ,ߦ
ߙ߭,ߟ߭,ߦ߭
ߒ
ߠ,ߧ
The second column shows extensions to the repertoire produced by adding diacritics.
Basic consonants
Basic consonant sounds in N’Ko are written using the following letters.
Click on each letter for more details and for examples of usage.
ߔ,ߓ,ߕ,ߘ,ߞ,ߜ,ߗ,ߖ,ߝ,ߛ,ߤ,ߡ,ߣ,ߢ,ߥ,ߙ,ߚ,ߟ,ߦ
These basic letters are extended to cover additional sounds used in loan or foreign words by adding combining marks (see extendedC).
Nasal syllabic
ߒ
07D2 is considered to be neither a consonant nor a vowel. It represents an alveolar or velar syllabic nasal soundu.
eg.
ߒߞߏ
This character may carry a tone diacritic, eg. ߒ߬.
Abstract consonants
ߠ,ߧ
The 'abstract' consonants 07E0 and 07E7 are used where allophonic variants of 07DF and 07E6 after a nasal or nasalisation produce the sounds n and ɲ, respectively, either word-internally or across word boundaries.u They are generally transcribed using n and y, respectivelycd§xviii.
eg.
ߘߏ߲߬ߠߌ߲
ߓߏ߲߬ߧߊ
Consonant repertoire extension
Three diacritics, two of them tone markers, are used to represent foreign sounds (particularly Arabic and French) in conjunction with existing N’Ko letters, eg. ߛ߳ represents the θ sound of the Arabic letter ث.u
Observation: The transcription for ߙ߳ as ḍ comes from the Unicode Standard v17, but that isn't a normal IPA representation. More information is needed.
The diacritics used are 07EB, 07ED, or 07F3.
eg.
ߓߐߗ߭ߎߙ. ߓߌߢߍ߲ ߝ߭ߋߣߎ߳.
Archaic consonants
ߨ,ߩ,ߪ
The Unicode Standard lists 3 consonants that are archaic forms of other characters in the N’Ko block. The new shapes were only introduced in the latter writings of the inventor of the script, Solomana Kante. (Their inclusion in the block generated some controversy.yaec)
Archaic form
Modern form
ߨ
ߖ
ߩ
ߗ
ߪ
ߙ
Consonant sounds to characters
This section maps N’Ko consonant sounds to common graphemes in the N’Ko orthography.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
consonantߔ
b
consonantߓ
ɓ
consonantߓ߭
ɡ͡b
consonantߜ
t
consonantߕ
tˤ
consonantߕ߭Represents the Arabic ط.
t͡ʃ
consonantߗ
d
consonantߘ
dʰ
consonantߙ߳
dˤ
consonantߘ߭
d͡ʒ
consonantߖ
k
consonantߞ
k͡p
consonantߜ߳
ɡ
consonantߜ߭
q
consonantߞ߫Represents the Arabic ق.
f
consonantߝ
v
consonantߝ߭
θ
consonantߛ߳Represents the Arabic ث.
ð
consonantߗ߭Represents the Arabic ذ.
s
consonantߛ
sˤ
consonantߛ߫Represents the Arabic ص.
z
consonantߖ߭
zˤ
consonantߖ߳Represents the Arabic ظ.
ʃ
consonantߛ߭Represents the Arabic ش.
ʒ
consonantߗ߭Represents the Arabic ذ.
x
consonantߞ߭
ɣ
consonantߜ߫Represents the Arabic غ.
ħ
consonantߤ߭
ʕa
vowelߊ߳Represents the Arabic عَ.
h
consonantߤ
m
consonantߡ
ɱ
consonantߡ߭
n
consonantߣ
abstract consonantߠAbstract consonant.
n̩
nasal syllableߒNasal syllable.
ŋ
consonantߢ߭
ɲ
consonantߢ
abstract consonantߧAbstract consonant.
w
consonantߥ
r
consonantߙ
rr
consonantߚ
ʀ
consonantߙ߭
l
consonantߟ
lˤ
consonantߟ߭
j
consonantߦ
j̰
consonantߦ߭
Symbols
߶ is added to phrases to indicate remote future placement of the topic under discussion.u
Numbers
Digits
N’Ko uses native digits.
߀,߁,߂,߃,߄,߅,߆,߇,߈,߉
Numbers are typed and stored in with the most significant digit first. However, unlike other right-to-left scripts such as Arabic, Hebrew, Thaana, the numbers are displayed right-to-left.u This means that numbers don't produce bidirectional text in N’Ko.
The highlighted characters represent the date 17 Sept. 2021 in N’Ko. All characters are read right to left, including numbers.
The following shows the ‘logical’ order of characters for the highlighted text just above. It represents the order in which characters are typed and stored, progressing from left to right.
߁,߇,,ߕ,ߎ,ߟ,ߊ,ߝ,ߌ߲,,߂,߀,߂,߁
Ordinal numbers
߭,߲
Ordinal numbers are indicated using diacritics.
The first ordinal is produced using 07EDu.
߁߭first
Others use 07F2.
߂߲second
When there are multiple digits in a number, the diacritic appears only under the last in sequenceu, eg.
߁߂߃߲123rd
Currency
߾,߿
Unicode 11 introduced 2 currency symbols to represent the dorome and taman.e4 The symbols precede the numeric amounts.
eg.
߾߅،߿߉߅
Observation: It's not clear who uses these currency denominations.
Text direction
N’Ko text is written horizontally, with successive lines progressing down the page.
Inline text is right-to-left in the main but, as in most right-to-left scripts, embedded text in left-to-right scripts is written left-to-right (producing 'bidirectional' text). However, like Adlam but unlike Arabic, numbers are also written with digits in
right-to-left order.
N’Ko-script words are read right-to-left, starting from the right of this line, but 'Karl Marx' is read left-to-right. The numbers (1818-1881) and the range, on the other hand are written right-to-left.
The Unicode Bidirectional Algorithm automatically takes care of the ordering for all the text in fig_bidi, as long as the 'base direction' is set to RTL. In HTML this can be set using the dir attribute, or in plain text using formatting controls.
If the base direction is not set appropriately, the directional runs will be ordered incorrectly, as shown in fig_bidi_no_base_direction.
Unicode provides a set of 10 formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction for an inline range of characters. RLE/LRE come at the start, and PDF at the end of a range of characters for which the base direction is to be set.
More recently, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2069 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
An example of unjoined text used for the title of a section. The body text is joined.
Texts based on legacy fonts often create the unjoined effect by using an old non-Unicode font where the glyphs make an attempt to show a baseline but don't actually join. This leads to shapes such as those shown in the title of fig_unjoined_old, where letters have short baseline extensions.
An example of unjoined text used for the title of a section taken from an online text that is not Unicode-based. The heading uses glyphs with small baseline extensions, though they don't join.
Cursive text
Although the shapes just mentioned can be found quite commonly (see examples), the World Organisation for the Development of N'Ko prefers that unjoined shapes look the same as the isolated forms of letters without the baseline extensions.GitHub issue #29§https://github.com/w3c/afrlreq/issues/29#issuecomment-1468140413
Expand the control just below to see a figure which compares isolated characters from a cursive font with glyphs from an older font that includes the small horizontal extensions.
Show figure
Joining side:
none
unjoined
07D4
ߔ
07D3
ߓ
07D5
ߕ
07D8
ߘ
07D7
ߗ
07D6
ߖ
07DE
ߞ
07DC
ߜ
07DD
ߝ
07DB
ߛ
07E4
ߤ
07E1
ߡ
07E3
ߣ
07E2
ߢ
07E5
ߥ
07D9
ߙ
07DA
ߚ
07DF
ߟ
07E6
ߦ
07D2
ߒ
07CA
ߊ
07CB
ߋ
07CC
ߌ
07CD
ߍ
07CE
ߎ
07CF
ߏ
07D0
ߐ
Comparison of isolated letters from the Noto font, and letter forms found in the older Bateka font. The latter has glyphs that may be found in non-joined fonts used in headings. Note the small horizontal lines at the bottom of many glyphs.
It is possible to use CSS to make a font show unjoined letters, if the OpenType features are available. Simply add something like this to your style sheet.
When N’Ko is cursive (see writing_styles), letters in a word are joined up. Fonts need to produce the appropriate joining form for a letter, according to its visual context, but the code point remains the same. This results in four different glyphs for most letters (including an isolated glyph).
Cursive connections in a word. The highlights show both medial and final forms of ߐ.
Unlike some other cursive scripts, the cursive treatment doesn't produce significant variations of the essential part of the glyph for a character.
All letters are capable of joining on both sides.
Unlike Arabic or Syriac, joining forms only differ by the addition of a small baseline extension. Also, whereas Arabic and Syriac re-use a number of basic shapes to create additional letters by adding diacritics, in N’Ko each letter shape is different. fig_joining_forms shows the basic shapes in N’Ko and what their joining forms look like.
Joining side:
none
right
both
left
07D4
ߔ
ߺߔ
ߺߔߺ
ߔߺ
07D3
ߓ
ߺߓ
ߺߓߺ
ߓߺ
07D5
ߕ
ߺߕ
ߺߕߺ
ߕߺ
07D8
ߘ
ߺߘ
ߺߘߺ
ߘߺ
07D7
ߗ
ߺߗ
ߺߗߺ
ߗߺ
07D6
ߖ
ߺߖ
ߺߖߺ
ߖߺ
07DE
ߞ
ߺߞ
ߺߞߺ
ߞߺ
07DC
ߜ
ߺߜ
ߺߜߺ
ߜߺ
07DD
ߝ
ߺߝ
ߺߝߺ
ߝߺ
07DB
ߛ
ߺߛ
ߺߛߺ
ߛߺ
07E4
ߤ
ߺߤ
ߺߤߺ
ߤߺ
07E1
ߡ
ߺߡ
ߺߡߺ
ߡߺ
07E3
ߣ
ߺߣ
ߺߣߺ
ߣߺ
07E2
ߢ
ߺߢ
ߺߢߺ
ߢߺ
07E5
ߥ
ߺߥ
ߺߥߺ
ߥߺ
07D9
ߙ
ߺߙ
ߺߙߺ
ߙߺ
07DA
ߚ
ߺߚ
ߺߚߺ
ߚߺ
07DF
ߟ
ߺߟ
ߺߟߺ
ߟߺ
07E6
ߦ
ߺߦ
ߺߦߺ
ߦߺ
07D2
ߒ
ߺߒ
ߺߒߺ
ߒߺ
07CA
ߊ
ߺߊ
ߺߊߺ
ߊߺ
07CB
ߋ
ߺߋ
ߺߋߺ
ߋߺ
07CC
ߌ
ߺߌ
ߺߌߺ
ߌߺ
07CD
ߍ
ߺߍ
ߺߍߺ
ߍߺ
07CE
ߎ
ߺߎ
ߺߎߺ
ߎߺ
07CF
ߏ
ߺߏ
ߺߏߺ
ߏߺ
07D0
ߐ
ߺߐ
ߺߐߺ
ߐߺ
Joining forms for shapes that join on both sides.
Managing glyph shaping
200D (ZWJ) and 200C (ZWNJ) are used to control the visual joining behaviour of cursive glyphs. They are particularly useful in educational contexts.
ZWJ permits a letter to form a cursive connection without a visible neighbour.
ZWNJ prevents two adjacent letters forming a cursive connection with each other when rendered.
Observation: The ZWJ only works on the left side of glyphs in fig_joining_forms if the table cell's base direction is set to RTL.
Context-based shaping & positioning
The Noto Sans NKo font changes the height of diacritics according to the height of the base character, but the preferred approach is to maintain the diacritics at the same height all along a line.GitHub§https://github.com/w3c/afrlreq/issues/30
The height of diacritics depends on the base consonant.
The only time a base character carries multiple combining characters is when one is a tone mark and the other is 07F2. These diacritics occur on opposite sides of the base letter, so this avoids the difficulties associated with correctly placing marks in the same location. (A letter that carries 07F3 will not usually carry a tone mark as well.GitHub§https://github.com/w3c/afrlreq/issues/30)
Multiple diacritics attached to the same base consonant.show composition
ߓߊ߲߬
Apart from that, no shaping is needed other than that described for cursive connections.
Letterform slopes, weights, & italics
N’Ko uses italicisation and bolding.
An example of bolded inline text.
Italics may need to lean to the left, rather than to the right. Neil Patel writes:
Formalized typographic practices for both Adlam and N’Ko are still being developed. When [JamraPatel] reached out to both communities to see if an Italic typeface would be beneficial, both communities expressed a desire to have one. Over the past few years, as the ability to use both of these scripts more readily in computing has increased, the need to be able to set more complex copy has increased as well. Both communities see the benefit of having italic typefaces to add some semantic value to their copy. On-line N’Ko has historically used synthetic obliques for things like by-lines on articles. ...
Since neither script had any precedent for a drawn italic typeface, we asked each community on how they would like to see it drawn. This is how N’Ko ended up with the leftward lean and Adlam with a rightward lean in our typeface. ... To my knowledge our typeface has the first drawn italicized N’Ko and Adlam, so this is all still a bit new.g3§#issuecomment-512911833
The te-kerende is a common way of linking together a sequence of sounds that mean 'each and every ...'. It is possible to create new combinations, and the general pattern is to repeat the vowel of the first word, then repeat the first word, and put the te-kerende in between each item.GitHub: Issue #28§https://github.com/w3c/afrlreq/issues/28
eg.
ߡߐ߰ ߺ ߐ ߺ ߡߐ߰
ߛߎ ߺ ߎ ߺ ߛߎ
ߛߌ ߺ ߌ ߺ ߛߌ
The te-kerende sits on the baseline, and breaks cursive joining. There is a small space on either side.
Line-breaks only occur after te-kerende, and not before.e4
A dedicated te-kerende code point was proposed for inclusion into Unicode, but not adopted. It is difficult to find a clear rationale for the lack of adoption other than brief references to the possibility of using a regular hyphen, which would be dropped to the baseline by fonts. In N'Ko documents, however, it appears that the de facto standard is to use ߺ surrounded by small spaces to represent this punctuation, and other places where in Latin text a hyphen might appear. On the other hand, there may be some locations in the document where a regular hyphen is more appropriate, such as for counter style separators.
Graphemes
Grapheme clusters
No issues are evident with regard to grapheme selection when using Unicode grapheme clusters.
N’Ko uses punctuation marks from the ASCII, N’Ko, and and Arabic Unicode blocks.u
phrase
،
߸
؛
:
sentence
.
؟
߹
section
߷
߸ and ، are sometimes used distinctively within the same textu (see fig_contrasting_commas) .
An example of contrastive use of commas.
߸ is normally separated from the previous word by a space, but in some texts is not, If no space is used, the baseline line below the dot doesn't join with the preceding letter.
An example of a comma immediately following a word, where the comma's baseline doesn't create a join.
߷ is used to end major sections of the text, and represents the three stones that hold a cooking pot over the fireu.
N'Ko commonly uses ASCII parentheses and brackets to insert parenthetical information into text.
start
end
standard
(
)
other
[
]
⸜
⸝
The low paraphrase brackets may be used for quoting text as well as for editorial insertions that weren’t part of the original author’s textColeman Donaldson: personal correspondence 13Mar2023§https://.#bracketing. Note that all these characters have mirrored glyphs (see below).
Mirrored characters
The words 'left' and 'right' in Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use >U+003E GREATER-THAN SIGN, but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some of the more common ones.
N'Ko texts may use guillemets or native marks around quotations.
start
end
standard
«
»
other
⸜
⸝
other
﴿
﴾
The quotation marks in the first two rows above are also mirrored as the directionality changes (see mirrored_characters). Those in the bottom row are not mirrored during display, which means that for them LEFT means use on the left, and RIGHT means use on the right.
⸜ and ⸝ are used as a pair to indicate indirect quotationsep, eg.
⸜ߒߞߏ⸝
Observation:﴾ and ﴿ derive from Arabic, and appear to be used for quotations in Islamic texts. The appearance of these brackets can vary from the shapes used in Arabicu§774. Note also that they are encoded among presentation forms, but it is normal to use these particular code points as if they were normal characters. See examples here.
Example of ornate parentheses used for Quranic quotations.
Emphasis
N'Ko authors commonly apply bolding and sometimes italics to emphasise text (see fontstyle).
07FD is used to abbreviate units of measure.e4 The table shows some examples from a long list by Eversone4:
Full word
Abbreviation
ߞߎߘߍ
ߞ߽
ߛߌߘߐ
ߛ߽
ߕߏ߲ߜߊ
ߕ߽
ߜߟߊ߬ߥߊ߰ߘߋ߲
ߡߥ߽
ߜߟߊ߬ߗߡߍ߬ߝߘߎ߬ߓߍ߲
ߡߗ߽߂
Other inline features
Other punctuation
ߺ is typically used, with a space on either side, to represent te-kerende or other hyphen-related punctuation. (For more information, see tekerende.)
Line & paragraph layout
Line breaking & hyphenation
Lines are mostly broken at inter-word spaces. As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line.
Breaking between Latin words.
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines from bottom to top.
latin-line-breaks shows how two Latin words are apparently reordered in the flow of text to accommodate this rule. Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
The lower of these two images shows the result of decreasing the line width, so that text wraps between a sequence of Latin words.
In-word line-breaking
Lines can be broken inside a word, in which case -U+002D HYPHEN-MINUS is added to the end of the line.e4
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear in these positions.
The following list gives examples of typical behaviours for some of the characters used in modern N'Ko script. Context may affect the behaviour of some of these and other characters.
Click/tap on the characters to show what they are.
“ ‘ ( ⸜ « should not be the last character on a line.
” ’ ) ⸝ » ߹ ؛ ؟ ߸ ، . :% should not begin a new line.
߾ ߿ should be kept with any number, even if separated by a space or parenthesis.
Line breaking should not move a danda or double danda to the beginning of a new line even if they are preceded by a space character.
The most common approach to justification relies on adjustment of spaces.u
Sometimes, however, ߺ is used like arabic tatweel to stretch the intra-word baseline.u
Observation: The N’Ko comma is separated from the preceding word by a space, which appears to stretch during justification in various samples. It's not clear whether that is expected, or simply because an ordinary space was used, rather than, say, a NNBSP.
Text may be stretched, like in Arabic, using ߺ to fit a given space or make a heading stand out, eg. fig_letter_spacing shows a streched version of the title, ߞߏ߲.
A title that is stretched using baseline extension characters.
N'Ko uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
N'Ko places diacritics above and below the base characters, but they don't stack. Diacritics can, however, appear above and below the same base. The letters themselves are relatively uniform in height, and have no descenders. There is no upper- vs. lowercase distinction.
To give an approximate idea, fig_baselines compares Latin and N'Ko glyphs from the Noto Sans font. The basic height of N'Ko letters is typically around the Latin cap-height, however combining marks and the dorome sign reach beyond the Latin ascenders, creating a need for larger line spacing. (Note that the preference of users is for the tone marks to all appear at the higher position shown here, but this version of the Noto font drops them when the base is less tall.)
Font metrics for Latin text compared with N'Ko glyphs in the Noto Sans Nko font.
fig_baselines_other shows similar comparisons for the Ebrima and Conakry fonts.
Latin font metrics compared with N'Ko glyphs in the Ebrima and Conakry fonts.
The N'Ko orthography uses 2 numeric styles with native digits. The first uses cardinal numbers, the second ordinal.
Cardinal numeric style
The cardinal numeric style is decimal-based and uses these digits.
߁,߂,߃,߄,߅,߆,߇,߈,߉,߀
eg.
߁,߂,߃,߄,߁߁,߂߂,߃߃,߄߄,߁߁߁,߂߂߂,߃߃߃,߄߄߄
Ordinal numeric style
The ordinal numeric style uses the same digits, but places a dot alongside. The dot goes over the digit ߁ (1), but goes below other digits, and it only appears alongside the leftmost digit. (Bear in mind that N'Ko digits run from right to left.)
߁߭,߂߲,߃߲,߄߲,߅߲,߆߲,߇߲,߈߲,߉߲,߀߲
eg.
߁߭,߂߲,߃߲,߄߲,߁߁߭,߂߂߲,߃߃߲,߄߄߲,߁߁߁߭,߂߂߂߲,߃߃߃߲,߄߄߄߲
Prefixes and suffixes
An N'Ko list counter for cardinal number styles typically uses a hyphen + space as a suffix.
߁- ߂- ߃- ߄- ߅-
Separator for N'Ko list counters.
Page & book layout
General page layout & progression
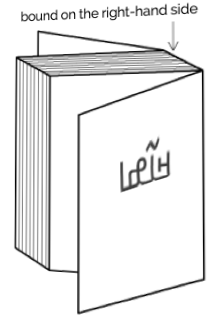
N’Ko books, magazines, etc. are bound on the right-hand side, and pages progress from right to left.
Binding configuration for N’Ko books, magazines, etc.
Columns are vertical but run right-to-left across the page.
Layout direction
The right-to-left orientation of the script affects the direction of page layout, and of the layout of items within the page.
An N’Ko web page should be the mirror-image of pages in, say, French. This includes the various navigation items on the page, and the placement of other panels on the page.
The following show a meter control, a progress control, and an input slider as they would appear in an N'Ko web page. The quantity represented increases from right to left.
A selection of right to left controls.
On the other hand, the video controls assume a LTR direction. This is mostly constrained by technology at the moment, and whether or not this is acceptable is still being debated.