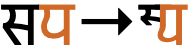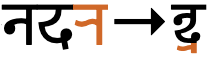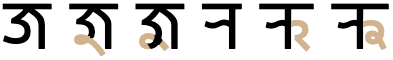This page brings together basic information about the Newa (or Pracalit) script and its use for the Newar language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Newar using Unicode.
Newa (also known as Prachalit or Nepaalalipi) is a Brahmi-derived script used principally to write the Tibeto-Burman language Newar (also known as Nepal Bhasa). The language is spoken by around 800,000 people, predominantly in the Kathmandu valley (the 5th most spoken language in Nepal), plus 14,000 in Sikkim, where it is recognised as a state language. The Newar language is mostly written in Devanagari, but there is a movement to promote more use of the Newa script.
It has also been used to write Sanskrit, Bengali, Maithili, and Hindi.
The script emerged in the 10th century and was actively used until Gorkha rule ended the reign of Newar dynasties in 1769, after which the use began to decline. The use of the Newa script and Newar language was banned by the Rana government in 1905, with harsh treatment of proponents. When Rana rule ended in 1951, the ban was lifted, but the effects are still felt.
A revival initiative gained momentum in the 1980s, and a standard was created by the Nepal Lipi Guthi with the help of leading scholars in 1989
Newa is one of at least 6 scripts used for writing Nepali languages, which include Ranjana, Bhujimol, Kutila, Golmol, and Litumol.
Unicode 17 has 1 dedicated Newa block, comprising 97 characters.
Vowels The inherent vowel is generally pronounced ə, however the inherent vowel after w appears to be ɔ.
Post-consonant vowels are generally written using combining marks (vowel signs). The vowels ɛː and æː in Katmandhu Newar are written using the letter 𑐫𑑂, which always retains its visible virama, even if word-medial.
Newar vowel signs are involved in a number of unusual, context-dependent shaping behaviours, including alternate shapes for vowel signs, integration of vowel signs into the consonant's headstroke, and the formation of circumgraphs for certain consonant-vowel combinations.
A unusual feature of Newa orthography is that vowel signs with a wavy horizontal line replace the flat headstroke of the base consonant. Newa also has consonant-vowel ligatures.
The vowel signs and independent vowels are combined with diacritics to indicate various combinations of vowel length and nasalisation. The i and u sounds have different symbols for short and long values, but 𑑅 is used to indicate length for the other vowels. 𑑃 is used to nasalise a short vowel, and 𑑄 for a long vowel. Note, however, that where a sound has separate symbols for short and long, the latter nasalisation diacritic is used with the symbol for the short vowel.
Consonants Newar has 27 basic consonant letters, which include atomic characters for 6 out of 8 murmured consonants. 12 more consonants are used in other dialects, or other languages (such as Sanskrit).
11442 is used to kill the inherent vowel and to form conjuncts. In conjuncts it is invisible.
Conjunct forms are normally rendered using fused ligatures. Initial RA is rendered as a reph over the top right of the following consonant. Conjuncts are typically vertically or diagonally ligted forms, but they don't exceed the height of a normal character.
Syllable codas are written using an ordinary consonant followed by 11442.
These are sounds for the Kathmandu dialect of the Newar language.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Plain vowels
Diphthongs
All of the vowels and diphthongs can be nasalised (see nasalisation).
o, oː and u can also be pronounced ɔ, ɔː, and ʊ.wl§#Vowels
The sound ɑ, or something close to it, is used in the Dolakhar Newa dialect, used outside Kathmandu.wl§#Vowels
Consonant sounds
labial
alveolar
post-
alveolar
retroflex
palatal
velar
glottal
stops
pb
td
ʈɖ
kɡ
aspirated
pʰbʱ
tʰdʱ
ʈʰɖʱ
kʰɡʱ
affricates
t͡ɕd͡ʑ
aspirated
t͡ɕʰd͡ʑʱ
fricatives
s
h
nasals
m
n
ŋ
aspirated
mʱ
nʱ
approximants
w
l
j
aspirated
wʱ
lʱ
jʱ
trills/flaps
ɾ
ɽ
aspirated
ɾʱ
ɽʱ
The retroflex sounds only occur in the small Dolakha Newar dialect, located to the West of Kathmandhu.wl§#Consonants
Tap consonants ɾ and ɾʱ can occur as word-medial alternates of t, d, dʱ, or (in Dolakha) ɖ.wl§#Consonants
ŋ occurs only in word-final position in the Kathmandu dialect.wl§#Consonants
Tone
Newar is not a tonal language.
Vowels
Post-consonant
Standalone
Plain
𑐶,𑐷,𑐶𑑃,𑐶𑑄,,𑐸,𑐹,𑐸𑑃,𑐸𑑄
𑐂,𑐃,𑐂𑑃,𑐃𑑄,𑐄,𑐅,𑐄𑑃,𑐅𑑄
𑐾,𑐾𑑅,𑐾𑑃,𑐾𑑄,,𑑀,𑑀𑑅,𑑀𑑃,𑑀𑑄
𑐊,𑐊𑑅,𑐊𑑃,𑐊𑑄,𑐌,𑐌𑑅,𑐌𑑃,𑐌𑑄𑑅
ⓘ,𑑅,𑑃,𑑄
𑐀,𑐀𑑅,𑐀𑑃,𑐀𑑄
𑐫𑑂,𑑃𑐫𑑂
𑐀𑐫𑑂,𑐫𑑂
𑐵𑐫𑑂,𑐵𑑃𑐫𑑂,,𑐵,𑐵𑑅,𑐵𑑃,𑐵𑑄
𑐁𑐫𑑂, ,𑐁,𑐁𑑅,𑐁𑑃,𑐁𑑄
Diphthongs
𑐿,𑐿𑑄,𑑁,𑑁𑑄
𑐋,𑐍
ⓘ represents the inherent vowel.
Inherent vowel
𑐎
kə
The inherent vowel for Newar is pronounced ə. So kə is written by simply using the consonant letter.
eg.
𑐎𑐮
𑐎,𑐮
Wiktionary transcriptions indicate that the inherent vowel after 𑐰 is pronounced ɔ.
eg.
𑐰𑐔𑐸
𑐧𑑂𑐰𑐴
The inherent vowel can be lengthened and nasalised. This is indicated in the same way as for other vowels, except that there is no vowel sign involved.
eg.
𑐳𑑃𑐎𑑂𑐰𑑅
𑐀𑑄𑐐𑑅
Since Newa consonants normally include an inherent vowel, the orthography has ways to indicate a consonant that is not followed by a vowel sound. See novowel.
Post-consonant vowels
Post-consonant vowel sounds are written using a set of dedicated combining marks, plus the combination 𑐫𑑂, which is used for 2 vowels (ɛː and æː). The latter always retains its visible virama, even if word-medial.
The vowel signs are combined with other diacritics to indicate the various combinations of vowel length and nasalisation. See basicV for a summary.
Newar vowel signs are involved in a number of unusual, context-dependent shaping behaviours, including alternate shapes for vowel signs, integration of vowel signs into the consonant's headstroke, and the formation of circumgraphs for certain consonant-vowel combinations.
All vowel signs are typed and stored after the base consonant, whether or not they precede it when displayed. The glyph rendering system takes care of the positioning at display time. Conjuncts are treated as indivisible units when it comes to rendering vowel signs, meaning that pre-base vowel signs are rendered before the conjunct as a whole (see prebase).
Five vowel signs are spacing marks, meaning that they consume horizontal space when added to a base consonant.
Plain vowels
𑐎𑐷
kiː
Newar uses the following dedicated combining marks for most plain vowels. They may be used on their own, or in combination with other characters (see compositeV).
𑐶,𑐷,𑐸,𑐹,𑐾,𑑀,𑐵
eg.
𑐖𑐸𑐫𑐾
𑐣𑐾𑐰𑐵𑑅
Vowel letters using 𑐫𑑂
Two basic vowel sounds found in Katmandhu are represented using 𑐫𑑂 (usually a consonant letter). Both are long vowels.
ɛː is written 𑐫𑑂.
eg.
𑐦𑐫𑑂
𑐪𑐫𑑂𑐏𑐵
æː is written 𑐵𑐫𑑂.
eg.
𑐎𑐥𑐵𑐫𑑂
𑐨𑐵𑐫𑑂𑐮𑐔𑑄
Note that when this vowel occurs word-medially it is necessary to use 200C after the virama, so that it remains visible.
A number of words use this as a standalone vowel, when word-medial or word-final.
eg.
𑐡𑐾𑐫𑑂
𑐎𑑂𑐰𑑃𑐫𑑂
Diphthongs
𑐎𑐿
kəi
Newar also uses dedicated combining marks for diphthongs.
𑐿,𑑁
eg.
𑐩𑐟𑐿𑐎𑑂𑐫
𑐨𑑁
Shaping considerations
𑐎𑐸 𑐐𑐸
ku, gu
The shape of 11438 and (to a lesser extent) 11439 varies according to the consonant used. For example, compare 𑐎𑐸 and 𑐐𑐸. For more, see u_shape.
𑐎 𑐎𑐾
kə, ke
Another noteworthy aspect of shaping is that certain vowel signs replace the headstroke of the consonant they follow. For example, compare 𑐎 and 𑐎𑐾. For more, see headstroke_assimilation.
𑐎𑐾 𑐐𑐾
ke, ɡe
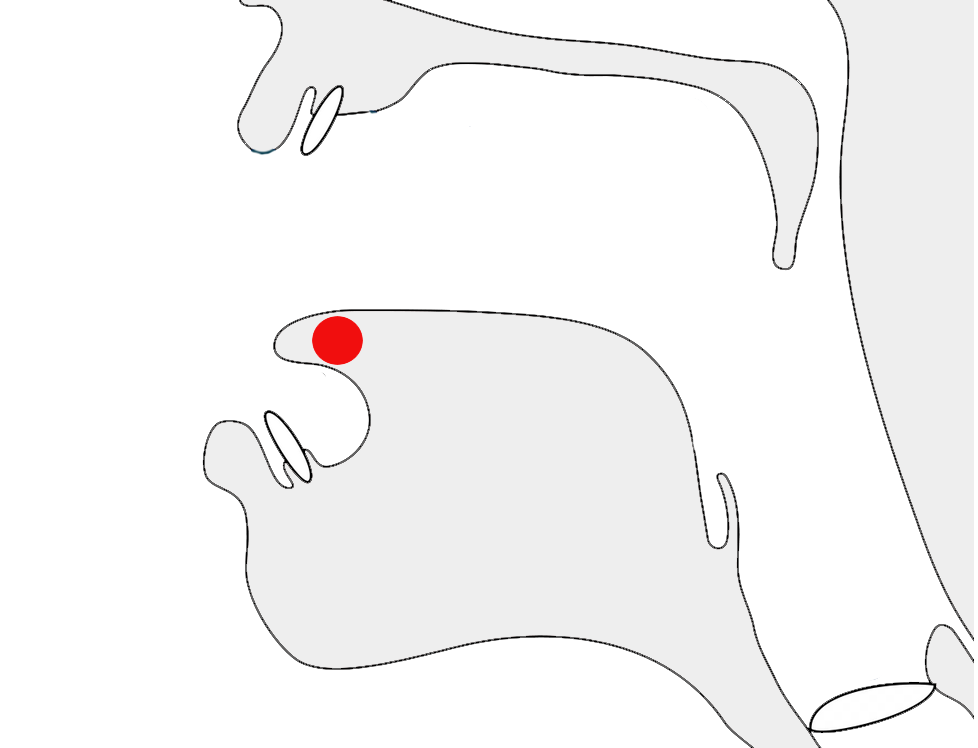
Another idiosyncracy of Newa orthography is that 5 vowel signs change shape when attached to the base consonants that don't have a headstroke. Four of those vowel signs are so-called 'wavy-headed', and when combined with the 7 headless consonants they are rendered as circumgraphs. For example, compare 𑐎𑐾ke and 𑐐𑐾ɡe. For more, see circumgraphs.
Vowel length and nasalisation
𑑅,𑑃,𑑄
It is common to see Newar vowels described in a chart which shows long and nasalised forms, as shown in vowel_table.
Vowel length is indicated by using a dedicated character in the case of 11437 and 11439, but otherwise by adding 11445.
Nasalisation is indicated using 11443 for a short vowel, and 11444 for a long vowel.
Long, nasalised ĩː and ũː vowels use the short form of the vowel sign (ie. there is no need for 𑑅).m§5-6
From left to right, short, long, nasalised, and long nasalised forms of kæ, respectively.
The following matrix shows these various forms for the vowel signs. The same rules apply to the standalone vowel letters.
Short
Long
Short nasal
Long nasal
i
𑐶
𑐷
𑐶𑑃
𑐶𑑄
u
𑐸
𑐹
𑐸𑑃
𑐸𑑄
e
𑐾
𑐾𑑅
𑐾𑑃
𑐾𑑄
o
𑑀
𑑀𑑅
𑑀𑑃
𑑀𑑄
æ
𑐵
𑐵𑑅
𑐵𑑃
𑐵𑑄
a
inherent
𑑅
𑑃
𑑄
əi
-
𑐿
-
𑐿𑑄
əu
-
𑑁
-
𑑁𑑄
The short, long, and nasalised versions of vowels.
Standalone vowels
Newa represents standalone vowels using a set of independent vowel letters. The set includes a character to represent initial ə, the inherent vowel sound. There are separate letters for short and long versions of i and u, but diacritics are used to lengthen the remaining letters (see nasalisation).
𑐂,𑐃,𑐄,𑐅,𑐊,𑐌,𑐀,𑐀𑐫𑑂,𑐫𑑂,𑐁𑐫𑑂,𑐁, ,𑐋,𑐍
eg.
𑐀𑐥𑐵
𑐃𑐮𑐔𑑄
𑐳𑐮𑐵𑐂
As mentioned earlier, a number of words also use 𑐫𑑂 as a standalone vowel, when word-medial or word-final.
eg.
𑐩𑐾𑐫𑑂
𑐥𑐸𑐮𑐶𑐎𑑂𑐰𑑃𑐫𑑂
In Sanskrit texts, elision of an initial a due to sandhi is indicated using 11447.
Vowel components
This section describes various vowel components and behaviours associated with this orthography.
Pre-base vowel sign
𑐎𑐶
ki
The vowel sign 𑐶 appears to the left of the base consonant letter or cluster.
eg.
𑐎𑐶𑐳𑐶
This is a combining mark that is always typed and stored after the base consonant(s), ie. the codepoints follow the order in which the items are pronounced. The rendering process places the glyph before the base consonant without changing the code points. The following shows the sequence of code points that make up the word just above.
𑐎,𑐶,𑐳,𑐶
The vowel sign is actually placed before the start of a conjunct. In the illustration just below, the sequence of glyphs for the orthographic syllable is rendered VCC, whereas the pronunciation is CCV. In conjuncts with 3 consonants, it will still be rendered before all the consonants.
eg.
𑐀𑐩𑑂𑐥𑐶
𑐩𑑂𑐥𑐶,𑐩,𑑂,𑐥,𑐶
The combination 𑐎𑐶 produces a pre-base positioned glyph.
However, note that if the cluster is split by a visible virama, this creates two orthographic syllables and the pre-base vowel sign appears after the consonant with the virama.
Circumgraphs
𑐐𑑀
ɡo
Five vowel signs change shape when attached to the base consonants that don't have a headstroke. Four of those vowel signs are so-called 'wavy-headed', and when combined with the 7 headless consonants they are rendered as circumgraphs, eg. compare:p§6
𑐎𑐾𑐧
𑐐𑐾𑑃𑐳𑐸
The following table shows the various forms, combined with both 𑐎 (has headstroke) and 𑐐 (headless). The last 4 vowel signs combined with the headless GA produce the circumgraphs.
With headstroke
Without headstroke
11435
𑐎𑐵
𑐐𑐵
1143E
𑐎𑐾
𑐐𑐾
11440
𑐎𑑀
𑐐𑑀
1143F
𑐎𑐿
𑐐𑐿
11441
𑐎𑑁
𑐐𑑁
Vowels that become circumgraphs with headless consonants.
No special encoding is needed to create these circumgraph forms. The shape change should be effected automatically by the font. Also, and usefully, unlike some other Indic scripts, it is not possible to incorrectly compose these circumgraph forms by combining other Newa characters, since the shapes don't exist in the character set.
Composite vowel signs
The composite vowels in Newa are described in nasalisation.
Vowel sounds to characters
This section maps Newar vowel sounds to common graphemes in the Newa orthography.
Vowels are labelled as either dependent or standalone.
Plain vowels
i
dependent𑐶
standalone𑐂
ĩ
dependent𑐶𑑃
standalone𑐂𑑃
iː
dependent𑐷
standalone𑐃
ĩː
dependent𑐶𑑄
standalone𑐂𑑄
u
dependent𑐸
standalone𑐄
ũ
dependent𑐸𑑃
standalone𑐄𑑃
uː
dependent𑐹
standalone𑐅
ũː
dependent𑐸𑑄
standalone𑐄𑑄
e
dependent𑐾
standalone𑐊
eː
dependent𑐾𑑅
standalone𑐊𑑅
ẽ
dependent𑐾𑑃
standalone𑐊𑑃
ẽː
dependent𑐾𑑄
standalone𑐊𑑄
o
dependent𑑀
standalone𑐌
oː
dependent𑑀𑑅
standalone𑐌𑑅
õ
dependent𑑀𑑃
standalone𑐌𑑃
õː
dependent𑑀𑑄
standalone𑐌𑑄
ə
inherent voweleg. 𑐎𑐮
standalone𑐀
əː
dependent𑑅Voiceless breath.
standalone𑐀𑑅
ə̃
dependent𑑃
standalone𑐀𑑃
ə̃ː
dependent𑑄
standalone𑐀𑑄
ɛː
dependent𑐫𑑂
standalone𑐀𑐫𑑂
standalone𑐫𑑂when used in word-medial or word-final position.
ɛ̃ː
dependent𑑃𑐫𑑂
æː
dependent𑐵𑐫𑑂
standalone𑐁𑐫𑑂
æ̃ː
dependent𑐵𑑃𑐫𑑂
a~æ
dependent𑐵
a
standalone𑐁
aː
dependent𑐵𑑅
standalone𑐁𑑅
ã
dependent𑐵𑑃
standalone𑐁𑑃
ãː
dependent𑐵𑑄
standalone𑐁𑑄
Diphthongs and other combinations
əi
dependent𑐿
standalone𑐋
əĩ
dependent𑐿𑑄
əu
dependent𑑁
standalone𑐍
əũ
dependent𑑁𑑄
Vocalics
𑐆,𑐺,𑐈,𑐼,𑐇,𑐻,𑐉,𑐽
Newa has a set of vocalic letters and vowel signs, but they are used for other languages, such as Sanskrit, and not for Newar.
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Given that consonants normally include an inherent vowel, the orthography needs a way to indicate when a consonant is not followed by a vowel.
Follow these links for more information.
Create a conjunct. There are a couple of possibilities here:
Ligation: Create a fusion of the letter shapes, where it is usually possible to spot the original components, but sometimes not.
The letter ra has its own idiosyncratic way of combining with other consonants, whether it precedes or follows them.
Show a visible virama below the non-final consonants in the cluster.
Conjuncts
In Unicode, conjunct formation is achieved by adding 11442 between the consonants. The font hides the virama glyph automatically when a conjunct is formed.
Conjuncts are normally formed by fusing glyphs for the component characters, so that they fit within the normal character height. One or both of the original letters may be unrecognisable, but generally the parts, though simplified, are recognisable.
It is most common for glyphs to merge vertically, although there are also many that merge diagonally. A few merge horizontally. See a list of combinations.
pla
pkʰa
spa
kpa
Various different ways of merging consonant shapes to form conjuncts.
For a detailed analysis of conjunct composition see Pandey, pages 7–10.
RA in clusters
A trailing RA has a fairly regular appearance as a subjoined glyph below the preceding consonant, though on the left side.
kra
A trailing RA in a cluster is rendered as a subjoined glyph.
However, like many other Indian scripts, 𑐬 at the beginning of a cluster is represented idiosyncratically, and appears as a small, superscript glyph over the top right of the following syllable.
rka
An initial RA in a cluster is rendered as a superscript over the following consonant.
Triple-consonant clusters
Newa has a few clusters involving 3 consonants. fig_conjunct_ndr gives an example.
ndra
A conjunct composed of 3 consonants.
The following is a list of the more common triple conjuncts, according to a Noto Fonts issue on GitHub.g1203
Observation: The list just above raises 2 questions: (a) why sequences such as nh don't use the precomposed code point, (b) which of these are used for Newar, as opposed to Sanskrit or another language?
Visible virama
Newa uses 11442 (the Newa equivalent of the Sanskrit virama) to indicate that there is no inherent vowel after a consonant. For example, compare the following.
𑐫𑐾𑐟𑑂
𑐨𑐵𑐬𑐟
All syllable codas are written with a following virama, although it is invisible if they are part of a conjunct (see clusters).
If a font doesn't have the appropriate glyphs to create a conjunct, the virama is displayed below the initial consonant. fig_conjunct_virama shows an example spotted in a newspaper.
A consonant cluster displayed with a visible virama.
If the font automatically substitutes a conjunct, but you don't want it to you can use 200C immediately after the virama to prevent the fusion of the characters. (If there is no consonant following, as in the case at the end of the line, this formatting character isn't needed.)
The virama is also frequently found as part of the vowel 𑐫𑑂, where it has a different function (see vletter ).
eg.
𑐟𑑃𑐫𑑂
Consonants
𑐥,𑐦,𑐧,𑐨,𑐟,𑐠,𑐡,𑐢,𑐚,𑐛,𑐜,𑐝,𑐎,𑐏,𑐐,𑐑
𑐔,𑐕,𑐖,𑐗
𑐳,𑐱,𑐲,𑐴
𑐩,𑐪,𑐣,𑐤,𑐞,𑐘,𑐙,𑐒,𑐓
𑐰,𑐴𑑂𑐰,𑐬,𑐭,𑐮,𑐯,𑐫,𑐴𑑂𑐫
Basic consonants
This section lists letters representing sounds of the Kathmandu dialect of the Newar language (shown in the table just above). See the next section for letters used in other dialects, or other languages (such as Sanskrit).
Basic consonant sounds in Newar are written using the following letters.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
The following letters are used in other dialects, or other languages (such as Sanskrit).
𑐚,𑐜,𑐛,𑐝,𑐱,𑐲,𑐞,𑐘,𑐙,𑐓,𑐬,𑐭
'Breathy' consonants
A feature of Newar is the number of consonants, besides the plosives, that are pronounced with accompanying breathiness. The following list shows these sounds and the way they are written.
𑐪,𑐤,𑐙,𑐓,𑐴𑑂𑐰,𑐭,𑐯,𑐴𑑂𑐫
Unicode provides single characters for most, but not all, of these.
Observation: Sources indicate that wʰ and jʰ are also part of the Newar phonetic repertoire, and are represented by these conjunct forms, but Unicode doesn't provide precomposed characters for them. They therefore have to be composed as consonant clusters.
Observation: One source stated that when these sounds are used for transcriptions of Sanskrit, they should all be written as consonant clusters, rather than using the precomposed characters.
Newa has 11446 that can be used to represent foreign sounds, but it doesn't appear to be used for Newar currently.
Onsets
Clusters of consonant letters at the beginning of an orthographic syllable occur in Newa, and they are handled as described in the section clusters.
Special behaviours include handling of RA at the beginning of an orthographic syllable (see preceding_ra).
Codas
Word-final consonant sounds with no following consonant are represented by ordinary consonant characters, followed by a visible 11442 character.
eg.
𑐫𑐾𑐟𑑂
Syllable-final consonants that are not word-final normally form conjuncts. See clusters.
(The commonly found combination 𑐫𑑂 represents a vowel sound when it occurs at the end of a syllable, rather than a coda. See vletter.)
Observation: Pandey says that 11445 can represent syllable-final aspiration, but it's not clear whether that occurs in Newar as well as in Sanskrit.
Consonant length
Gemination and consonant lengthening are handled using the normal approach to consonant clusters (see clusters).
Consonant sounds to characters
This section maps Newar consonant sounds to common graphemes in the Newa orthography.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
consonant𑐥
pʰ
consonant𑐦
b
consonant𑐧
bʱ
consonant𑐨
t
consonant𑐟
tʰ
consonant𑐠
t͡ɕ
consonant𑐔
t͡ɕʰ
consonant𑐕
consonant𑐎𑑂𑐲
d
consonant𑐡
dʱ
consonant𑐢
d͡ʑ
consonant𑐖
d͡ʑʱ
consonant𑐗
ʈ
consonant𑐚Generally used for loan words.
ʈʰ
consonant𑐛Generally used for loan words.
ɖ
consonant𑐜Generally used for loan words.
ɖʱ
consonant𑐝Generally used for loan words.
k
consonant𑐎
kʰ
consonant𑐏
ɡ
consonant𑐐
ɡʱ
consonant𑐑
ɡj
consonant𑐖𑑂𑐘
s
consonant𑐳
consonant𑐱Infrequent. Generally used for loan words.
ʂ
consonant𑐲Infrequent. Generally used for loan words.
h
consonant𑐴
m
consonant𑐩
mʰ
consonant𑐪
n
consonant𑐣
nʰ
consonant𑐤
ɳ
consonant𑐞Generally used for loan words.
ɲ
consonant𑐘Generally used for loan words.
ɲʰ
consonant𑐙Generally used for loan words.
ŋ
consonant𑐒
ŋʰ
consonant𑐓Generally used for loan words.
w
consonant𑐰
wʰ
consonant𑐴𑑂𑐰
r
consonant𑐬
rʰ
consonant𑐭
ru
dependent𑐺Used for non-native sounds in loan words.
standalone𑐆Generally used for loan words.
ruː
dependent𑐻
standalone𑐇
l
consonant𑐮
lʰ
consonant𑐯
lu
dependent𑐼
standalone𑐈
luː
dependent𑐽
standalone𑐉
j
consonant𑐫
jʰ
consonant𑐴𑑂𑐫
Symbols
Om.The symbol for the word Om is produced using 𑑉.
Encoding choices
Visually, several of the standalone vowels and some vowel signs look as it they could be composed of smaller parts. This section gives guidance on which approach is best.
Newa is relatively resistant to incorrect coding techniques, but it is possible that someone may occasionally try to use 2 characters rather than the single character which is canonical. Doing so produces text that will not match correctly encoded text for search, spell-checking, and so on, and so should be avoided. The list below shows some examples.
Use
Do not use
𑐁
11400 11435
𑐌
11404 11440
11440
1143E 11435
Unclear usage
The following code points in the Unicode block need further investigation. Their usage and/or their relevance to writing modern Newar is not clear from the research done so far.
11446 Combined with a letter to represent sounds not native to the script, such as in loan words.
𑑇 Used to elide an initial A in Sanskrit as a result of sandhi.p§11
𑑈 Represents nasalisation in some manuscripts. In other sources, a form of punctuation.p§11
𑑌 Indicates end of a text block larger than a sentence.p§11
𑑎 Used for marking breaks and filling gaps in a line at a margin.p§11
𑑏 Marks abbreviations. p§11
𑑊 Represents the Sanskrit invocation सिद्धिरस्तुsiddhirastumay there be success. It is written at the beginning of a text, often in the combination 𑑊𑑉. It corresponds to the sign ঀ [U+0980 BENGALI ANJI] in related scripts such as Bengali.p§11
𑑛 Used for filling gaps in a line and as a mark for end of text.p§11
𑑟
𑑝
11460
11461
1145E
For other glyphs found in Newa manuscripts, see Pandey.p§11
Numbers
Digits
Newa has a set of native digits.
𑑐,𑑑,𑑒,𑑓,𑑔,𑑕,𑑖,𑑗,𑑘,𑑙
Pandey describes variant shapes for 3, 4, and 5, which are to be managed by font.p§10
Headstrokes & headlines. Pandey writes: The headstrokes of Newar letters do not connect to preceding or following letters. Connection of headstrokes of characters that form a syllable may occur, such as in the combination of a consonant letter and a dependent vowel sign. The majority of Newar manuscripts attest this behavior. However, there is no particular rule that describes the joining properties of headstrokes. Variations in the writing of headstrokes are to be attributed to scribal preferences. In modern digitized typefaces the headstrokes of glyphs connect, but this feature may be an influence of modern Devanagari typography.p§13
Headstrokes & headless consonants
The following 7 consonant letters have no headstroke. This leads to some special shaping for 5 vowel signs, including 4 that are changed into circumgraphs. See circumgraphs for details.
𑐐,𑐠,𑐢𑐛,𑐱,𑐞,𑐘
Another idiosyncrasy of Newa is that consonant letters with headstrokes have that headstroke replaced by a wavy line by 4 of the same vowel signs. See headstroke_assimilation.
Headstroke assimilation
A rather unusual feature of Newa orthography is that vowel signs with a wavy horizontal line replace the flat headstroke of the base consonant.
This includes vowels written with the following vowel signs: 1143E, 11440, 1143F, and 11441.p§6
The character 𑐎 with each of the wavy line vowel signs applied.
Alternative shapes for u
The sound u is produced by the letter 11438, but that letter can have a different shape when attached to different consonant letters. The vowel sign used to represent the long uː sound also has contextual variations, though not as many as the short vowel. All of these orthographic variants are produced automatically by the font; there is no need to use different characters.
The short sound is rendered as a curved shape with the following 4 consonant letters:p§7
The normal shape for 11438 (left), and the alternate shape used with the consonants shown.
Both short and long sounds are also written as ligatures with the consonant letters 𑐖 and 𑐬, as shown in fig_u_ligatures.
11438 and 11439 producing ligatures with 11416 (left) and 1142C (right).
The consonants 𑐨 and 𑐴 also take on special shapes when followed by a u-vowel (see bha_ha).
Special shapes for BHA & HA
𑐨 and 𑐴 have special shapes when combined with the 11438 or 11439, or any of the vocalic vowel signs.p§7
The normal shape (left) for BHA (top) and HA (bottom), and the alternate shape used with the U and UU vowels, or any of the vocalic vowel signs.
Additional contextual shaping for consonants carrying a u-related vowel sign can be seen in u_shape.
Explicit shaping controls
200C (ZWNJ) can be used to force the production of a visible virama, rather than a conjunct form.
Typographic units
Word boundaries
Word units are separated by spaces.
Graphemes
Grapheme clusters
Usually a typographic character unit correlates with the Unicode concept of grapheme clusters, but not in the case of conjuncts (in common with several other Indic scripts).
Conjuncts
Conjuncts and any dependent combining characters should never be split.
This creates a problem when dealing with Unicode grapheme clusters, because they stop after reaching a virama. So conjuncts usually contain multiple grapheme clusters. This produces incorrect segmentation as seen on the right in fig_grapheme_conjunct. Applications need to tailor the grapheme cluster rules to avoid splitting conjuncts.
Segmentation of the word 𑐢𑐵𑐬𑑂𑐩𑐶𑐎 as it should be (left), and how it would be if grapheme clusters are used as the maximal unit (right).
Unfortunately, this is harder than it seems, because whether a conjunct is formed or not usually depends on the capabilities of the font – it cannot be determined solely by looking at the code points in memory. If a font doesn't contain the glyphs to create a conjunct it will render the consonant cluster with a visible virama. In that case, the grapheme cluster approach is appropriate.
Punctuation & inline features
Phrase & section boundaries
Newa uses a mixture of ASCII and native punctuation marks.
phrase
,
𑑍
;
:
sentence
𑑋
?
!
𑑚
section
𑑌
Observation: The Lipi Pau newspaper in 2009 used spaces before and after the newa danda.
Danda and double-danda in use.
Bracketed text
Newar commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Quotations & citations
Newar texts use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
“
”
nested
‘
’
Single quotation marks are used for quotations within quotations.
Line & paragraph layout
Line breaking & hyphenation
Lines are mostly broken at inter-word spaces.
Like most writing systems, certain characters are expected not to start or end a line. For example, periods and commas shouldn't start a line, and opening parentheses shouldn't end a line.