This page brings together basic information about the Khmer script and its use for the Cambodian language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Cambodian using Unicode.
The Khmer script ( អក្សរខ្មែរʔaʔsɑː kʰmaːe ) is used for writing the official language of Cambodia, and sometimes for Cambodian minority languages, such as Tampuan, Krung, Cham, Brao and Mnong. It is currently in widespread use, although it is estimated that 35% of the Khmer-speaking population aged 15 and over are illiterate in the script. It is also used to write Pali in the Buddhist liturgy of Cambodia and Thailand.
The script is thought to be descended from the Brahmi Pallava script, and the Khmer literary tradition dates back to the 7th century. The modern Khmer script differs somewhat from precedent forms seen on the inscriptions of the ruins of Angkor. The Thai and Lao scripts are descended from an older form of the Khmer script.
Unicode 17 has 1 dedicated Khmer block, comprising 114 characters, and another block containing 32 lunar date symbols.
Khmer has more vowel sounds than ways to write them. Therefore, a written vowel can have different pronunciations, depending on the class of the base consonant. (There is no tone in Khmer, so classes are specially designed for vowel selection.) Additional factors include whether this is an unstressed vowel, vowel harmony, and whether any of the special diacritics have been used to change the sound. For an in-depth treatment of pronunciation see Huffman in the sources section.
There are 3 pre-base glyphs and 5 circumgraphs, 2 of which can decompose into composite vowel signs. This page lists 15 composite vowel signs (made from 9 vowel signs, and 8 consonants/diacritics), not counting decompositions. Composite vowel signs can involve up to 3 glyphs, but only surround the base consonant(s) on 2 sides
Each onset consonant is associated with a high or low class related to pronunciation (there is no tone). Khmer has more vowel sounds than ways to write them, so the choice of consonant class indicates different sounds for the same written vowel. Other factors may also affect the sound, such as stress, vowel harmony, and diacritics.
17D2 is used to form conjuncts. It is never visible.
Conjunct forms occur as stacked consonants. Word-internal clusters are very common at the beginning of a word, but clusters also occur medially in multisyllable words, and occasionally at the end of a word (though the 2nd consonant at the word end is usually not pronounced).
Syllable codas (typically 8 consonants and characters) are most commonly written using an ordinary consonant without an inherent vowel. Because there are no spaces or other word dividers, it is difficult to detect boundaries algorithmically. Two word-final sounds (m and h) can be produced using combining marks.
Layout Khmer text runs left to right in horizontal lines. Words are not separated by spaces. Spaces are used as phrase separators. There is no case distinction.
Modern Khmer has a number of distinct font styles, including slanted (called អក្សរច្រៀង), which has an upright variant, and round (called អក្សរឈរ). The round style includes more ligated forms. The upright style is used here.
Punctuation is mostly native, but some ASCII punctuation is also used.
Although words are not delimited by spaces, Khmer lines wrap at word boundaries.
Notable features
2 registers for consonants determine the pronunciation of vowel signs
These are sounds for the modern Cambodian language.
Click on the sounds to see where else in the document they are referred to.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Plain vowels
Front
Central
Back
Close
i iː
ɨ ɨː
u uː
Close-mid
e eː
ə əː
o oː
Open-mid
ɛː
ɔː
Open
a aː
ɑ ɑː
Complex vowels
Front
Central
Back
Close
iə
ɨə
uə ŭə
Close-mid
ei ĕə
əɨ
ou ŏə
Open-mid
ɔə
Open
ae aə ao
Consonant sounds
labial
dental
alveolar
retroflex
palatal
velar
glottal
stops
pɓ~b
tɗ~d
c
kɡ
ʔ
aspirated
pʰ
tʰ
cʰ
kʰ
affricates
fricatives
f
sz
h
nasals
m
n
ɲ
ŋ
approximants
ʋ~w
l
j
trills/flaps
r
Labial
Dental
Alveolar
Palatal
Velar
Glottal
Stop
p pʰ ɓ~b
ttʰ ɗ~d
c cʰ
k kʰ
ʔ
Affricate
Fricative
s
h
Nasal
m
n
ɲ
ŋ
Approximant
ʋ~w
l
j
Trill/flap
r
Tone
Khmer is not a tonal language.
Structure
Phonetic syllables
Many native Cambodian words are monosyllabic. `Khmer also has many bisyllabic words, in which the first syllable is typically unstressed, and the vowel is rendered in colloquial speech as a schwa. Some bisyllabic words are compounds, however, and this may not apply.
Syllables start with one or more consonants or an independent vowel, however the latter represent a vowel sound after a glottal stop, so the syllable onset is always C(C)(C)V. The rhyme is composed of a short vowel in stressed syllables that is always followed by a consonant (VC), or a long vowel, that may not be.
Many monosyllabic words begin with consonant clusters, and some monosyllabic words end with clusters, although only one consonant is pronounced in syllable final position.
Word-internally, a syllable with a final consonant followed by another syllable creates a stack of consonants. The top item in the stack is the syllable final consonant, and the initial consonant of the next syllable is rendered in subjoined form.
Polysyllabic words are usually of Sanskrit, Pali or French origin. These words tend to alternate stress across their syllables, but may not.
Orthographic syllables
An orthographic syllable differs from a phonetic syllable in that it always begins with a consonant, or cluster of consonants. Where word-medial stacks occur, the orthographic syllable may begin with the final consonant of the previous phonetic syllable and continue through the onset(s) of the following syllable. Alternatively, an orthographic syllable may be just a final consonant (or consonant cluster) in a phonetic syllable.
The same word, split into phonetic syllables (left) and orthgraphic syllables (right).
An orthographic syllable includes all the combining characters associated with the consonants it contains.
Vowels
ɑ-class
ɔ-class
Standalone
Simple:
ិ,ី, ,ឹ,ឺ, ,ុ,់,ូ
ឥ,ឧ,ឩ
ិ, ,ុ
េ, ,ោ
ឧ
ិ,ឹ
ើ
ឥ
ែ, ,ⓘ
័,ៈ,ា, ,់,ⓘ,៏
Complex:
ៀ, ,ឿ
ា,ៀ,ិះ,េះ, ,ឿ,ៃ,័យ,ៅ,ូវ, ,ួ,់,ោះ,ុះ,ុំ,ំ
េ,ិះ,េះ,ែះ, ,ូ,ុះ,ុំ
ៈ,័,ា◌់,ះ,ាំង, ,័,ា◌់,ាំ
ឩ
ី,ឺ,័,ឹះ,ើះ,ូវ
ិយ
ឥ,ឦ,ឪ
័រ
ោ,ែ,ើ,ៃ,័យ,ៅ,ះ,ោះ,ាំ,ំ,ាំង
ឯ,ឧ,ឱ,ឲ,ឰ,ឳ
Vocalics:
ឫ,ឬ,ឭ,ឮ
ⓘ represents the inherent vowel. Standalone vowels are normally written using a combining vowel sign after អ (not shown here).
Consonant registers
Cambodian inherited a writing system that has more vowel sounds than ways to write them, but has fewer consonant sounds than consonant symbols. Khmer takes advantage of this by dividing the consonant symbols into 2 classes (or registers): an a-class and an ɔ-class. The class of a consonant then determines the vowel sound in a syllable. For example, compare the pronunciations in the table:
ɑ-class consonant
IPA
ɔ-class consonant
IPA
1780
kɑː
1782
kɔː
1780 17B8
kəj
1782 17B8
kiː
1780 17B6
kaː
1782 17B6
kiə
Examples of vowel pronunciation changes, depending on the class of the base consonant.
Other factors may also affect the sound, such as stress, and vowel harmony. Diacritics can also be used to change the class of a consonant, or create sequences that represent a class for which there isn't a single character (see register_change).
These registers are not related to tone, as Khmer is not tonal.
Vowel harmony
In two-syllable words, where the second syllable begins with one of the following sonorant consonants the vowel class of the second syllable is the same as that of the first.
ង,ញ,ណ,ន,ម,យ,ឡ,ល,រ,វ
For example, in the following word the second syllable starts with an ɔ-class consonant but the class of the preceding syllable turns the vowel to an ɑ-class sound. There are, however, exceptions to this rule.
eg.
ប្រយ័ត្ន
Inherent vowels
ក
kɑː
គ
kɔː
Khmer has 2 inherent vowels: ɑː and ɔː. Both are commonly transcribed as a.
The class of the consonant will initially dictate which sound is appropriate, eg. 1780 (an ɑ-class consonant) is pronounced kɑː whereas 1782 (an ɔ-class consonant) is pronounced kɔː, but see also vowel_harmony.
eg.
កមល
ក,ម,ល
ពពក
ព,ព,ក
The invisible characters
឴U+17B4 KHMER VOWEL INHERENT AQ
and
឵U+17B5 KHMER VOWEL INHERENT AA
were originally intended to represent a phonetic difference not expressed by the spelling, so as to assist in phonetic sorting, however, the Unicode Standard considers them insufficient for that purpose and errors in the encoding, and they should not be used.u§677
Since Khmer consonants normally include an inherent vowel, the orthography has ways to indicate a consonant that is not followed by a vowel sound. See novowel.
Post-consonant vowels
Other vowels that follow consonants are written using 21 vowel sign or other combining marks and 2 glide consonant letters. Two additional diacritics are used to change the register of a syllable.
Khmer has more vowel sounds than ways to write them. Therefore, a written vowel can have different pronunciations, depending on the class of the base consonant. (There is no tone in Khmer, so classes are specially designed for vowel selection.) Additional factors include whether this is an unstressed vowel, vowel harmony, and whether any of the special diacritics have been used to change the sound. For an in-depth treatment of pronunciation see Huffman in the sources section.
There are 3 pre-base glyphs and 5 circumgraphs, 2 of which can decompose into multipart vowels. This page lists 15 multipart vowels (made from 9 vowel signs, and 8 consonants/diacritics), not counting decompositions. Multipart vowels can involve up to 3 glyphs, but only surround the base consonant(s) on 2 sides.
In the âksâr mul font style, some vowel signs form ligatures with their base consonants. See vowel_ligatures.
All vowel signs are typed and stored after the base consonant, and the glyph rendering system takes care of the positioning at display time. Conjuncts are treated as indivisible units when it comes to rendering vowel signs, meaning that pre-base vowel signs and left-side glyphs of circumgraphs are rendered before the conjunct as a whole (see prebase).
Ten vowel signs are spacing marks, meaning that they consume horizontal space when added to a base consonant. The reahmuk described below is also a spacing mark.
Simple vowels
The pronunciation of vowel signs depends on whether they follow an ɑ-class consonant or an ɔ-class consonant. In some cases the alternative may be a diphthong, so compare this also with the items in diphthongsV. Additional variations can arise from context or whether a syllable is open or closed. For more detailed information, click on the characters in the panel, or see vowel_mappings.
As an example of how the same vowel sign is pronounced differently after an ɑ-class and an ɔ-class consonant, check out the pronunciations for 17B7 in the following word.
កិរិយា
ក,ិ,រ,ិ,យ,ា
The following panel lists basic monophthongs following ɑ-class consonants.
ិ,ុ,ឹ,័,ៈ,ា,់,៏
The next panel shows vowels following ɔ-class consonants. In several cases the same vowel sign is used, but with a different pronunciation.
ិ,ី,ឹ,ឺ,ុ,់,ូ,េ,ោ,ើ,ែ
17C8 is a 20th century addition to the Khmer repertoire. It is used as a vowel after consonants that are pronounced as stressed syllables at the end of a word, or preceding an internal juncture in compounds.
The following panel lists basic diphthongs following ɑ-class consonants. In some cases the alternative may be a diphthong, so compare this also with the items in plainV.
ៀ,ឿ,េ,ូ,ី,ឺ,័,ូវ,ោ,ែ,ើ,ៃ,័យ,ៅ
The next panel shows vowels following ɔ-class consonants. In several cases the same vowel sign is used, but with a different pronunciation.
ា,ៀ,ឿ,ៃ,័យ,ៅ,ូវ,ួ,់,ៈ,័,ា◌់,័,ា◌់,ិយ,័រ
Khmer diphthongs generally end with -j, -w, or ə, but there are a few others that don't. It is noteworthy, also, that not all diphthongs ending with -j or -w use យ or វ.
179A is usually silent in syllable-final position, but the combination 17D0 179A produces the sound ɔə.
eg.
ជ័រ
Nikahit and reahmuk
ំ,ះ
The descendants of the anusvara and the visarga, 17C6 called និគ្គហិតniʔkəhət, and 17C7, called រះមុខreə̆hmuk, are regarded as vowels in Khmer, even though they represent the sounds -m and -h, respectively.
They not only represent a syllable coda, but their use also has an impact on the vowels in the syllable nucleus. For more information, see coda_marks.
Vowel modifier marks
័,់
17D0 is used in some Pali and Sanskrit loan words (although alternative spellings exist) and indicates that the syllable has a particular vowel (click on the character in the box for more details).
eg.
ស័ក
ល័ខ
17CB is always placed above the final consonant, and basically shortens the preceding vowel, eg. compare
ខាត
ខាត់
Vowel length
Vowel length is distinctive in Khmer. Short and long vowels are written using different vowel characters. For example, compare the long and short i vowel signs in the following word.
ហ្វ៊ីស៊ិក
Standalone vowels
Most of the time, vowels that appear to be standalone are actually pronounced and written after a glottal stop. These use the consonant 17A2 for ɑ-class vowels, or 17A2 17CA for ɔ-class vowels. They are usually followed by a vowel sign, but when used alone they represent the sound of the inherent vowel.
eg.
អូ
អ៊ូ
ចង្អូរ
The combination of 17A2 and a vowel sign can also occur as a subscript below a consonant onset or final consonant.
eg.
ក្អាត់
ចង្អៀត
Independent vowels
Khmer also has independent vowel letters that can be used to represent some of these sounds, but unlike most South Asian scripts, there are fewer independent vowels than vowel sounds, and some do not have direct correspondences with a simple vowel sign. For example, 17AA corresponds phonetically to the multipart vowel 17A2 17BC 179C. (See also vocalics.)
ឥ,ឦ,ឪ,ឧ,ឩ,ឯ,ឰ,ឱ,ឳ,ឲ
Whether a vowel sound is represented using an independent vowel letter or the glottal consonant plus vowel sign varies from word to word. In Cambodian orthography the two are not interchangeable. The independent vowel letters appear in relatively few words, but some of those words are quite common.
eg.
ឪពុក
ឲ្យ
ឮ
Other characters
The Unicode Khmer block contains 3 more independent vowels that are either obsolete or strongly deprecated.
ឨ
The Unicode Standard regards the following 2 characters as errors in the encoding.
ឣ,ឤ
Vowel components
This section describes various vowel components and behaviours associated with this orthography.
Pre-base vowel signs
េ,ែ,ៃ
Three combining marks are displayed to the left of the onset consonant(s).
eg.
គេ
កែ
កៃ
These are combining marks that are always typed and stored after the base consonant(s), ie. the codepoints follow the order in which the items are pronounced. The rendering process places the glyph before the base consonant without changing the code points. The following shows the sequence of code points that make up the first word just above.
គ,េ
Two prebase vowels, each pronounced after a consonant but rendered to its left.show composition
កែងដៃ
These vowel signs do not split a conjunct. This means that a word with a consonant cluster at the start separates the pre-base vowel from the position where it is pronounced by more than one consonant character.
eg.
អង្គ្លេស
អ,ង្,គ្,ល,េ,ស
A prebase vowel, pronounced after a consonant stack, but rendered to the left of the top character in the stack.show composition
អង្គ្លេស
Circumgraphs
ៀ,ឿ,ើ,ោ,ៅ
Five vowel or vocalic sounds are represented by a vowel sign that is a single code point in memory, but when displayed it has visually separate parts that appear on different sides of the preceding consonant or cluster.
eg.
តៀប
ត,ៀ,ប
Like pre-base glyphs, these are combining marks that are always stored after the base consonant or conjunct. The rendering process places the glyphs around the base consonant(s), as needed.
eg.
គ្រឿង
គ្,រ,ឿ,ង
A circumgraph vowel sign surrounding both the k and the r after which it is pronounced.show composition
គ្រឿង
None of these circumgraphs decompose during normalisation. See also encoding.
Composite vowel signs
Vowels represented by combinations of the above characters (not including decomposed versions of the 2 circumgraphs described below):
ាំ,ុំ,ុះ,េះ,ោះ,ា,ាំង,ិះ,ឹះ,ូវ,ើះ,ែះ,័រ,ិយ,័យShow which combinations contain a given character:
ា
ា់,ាំង,ាំ
ិ
ិយ,ិះ
ឹ
ឹះ
ុ
ុះ,ុំ
ូ
ូវ
ើ
ើះ
េ
េះ
ែ
ែះ
ោ
ោះ
ំ
ុំ,ាំង,ាំ
ះ
ោះ,ិះ,េះ,ុះ,ែះ,ឹះ,ើះ
់
ា់
័
័យ,័រ
យ
ិយ,័យ
ង
ាំង
រ
័រ
វ
ូវ
Show details about vowel glyph positioning.
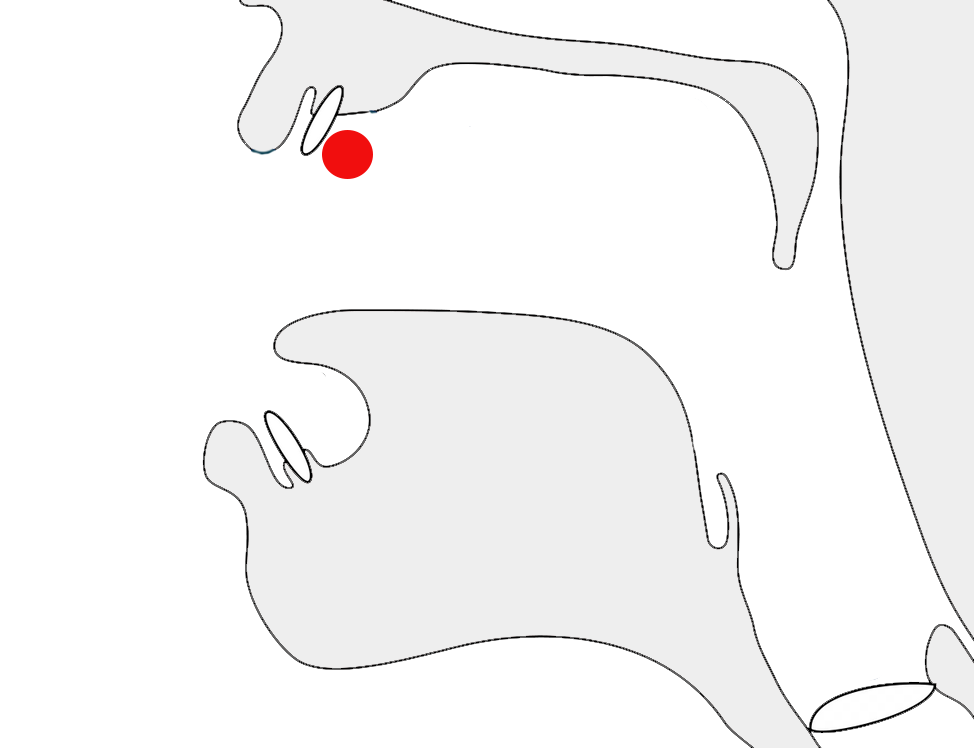
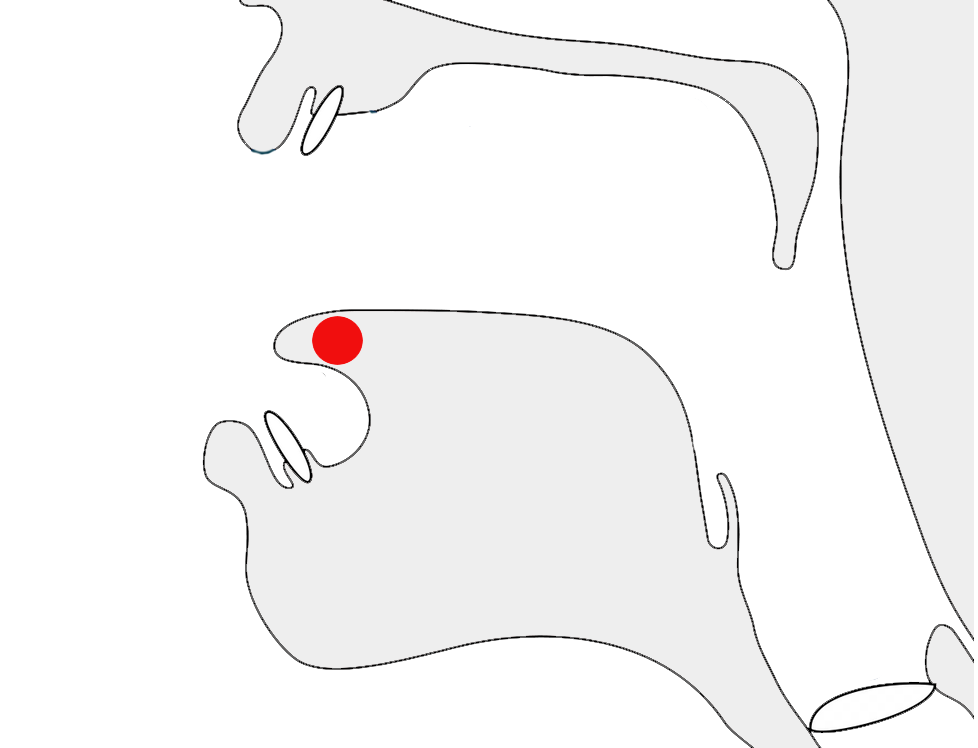
The following list shows where vowel signs are positioned around a base consonant to produce vowels, and how many instances of that pattern there are. The figure after the + sign represents combinations of vowel sign and niʔkəhət/reə̆hmuk,
3 pre-base, eg. កេke
2+1 post-base, eg. កាkā
4+1 superscript, eg. កិki
3 subscript, eg. កុku
4+1 pre+post-base, eg. កោko
1+1 super+post-base, eg. កាំkām̽
0+1 super+subscript, ie. កុំkum̽
0+1 sub+post-base, ie. កុះkuh̽
0+1 pre+post+post-base, ie. កោះkoh̽
At maximum, vowel components can occur concurrently on 2 sides of the base.
Characters that don't appear in the combinations:
ី,ឺ,ួ,ឿ,ៀ,ៃ,ៈ,ៅ
Vowel sounds mapped to characters
This section maps Cambodian vowel sounds to common graphemes in the Khmer orthography.
Items indicate whether a sound is produced after an a-class or o-class consonant. The dotted circle indicates the location of the consonant relative to the vowel sign; if there are 2 circles, the vowel is used only in closed syllables. Vowels are followed by a glottal stop in stressed syllables, but not in unstressed.
Plain vowels
i
o-classិFollowed by a glottal stop in stressed syllables, but not in unstressed.
standaloneអ៊ិ
iː
o-classី
standaloneអ៊ី
otherិយ
្យ⏴
finalយin some words.
ɨ
o-classឹ
standaloneអ៊ឹ
standaloneឥ
other17B9except before 1799.
other17C1before palatals.
ɨː
o-classឺ
standaloneអ៊ឺ
u
o-classុFollowed by a glottal stop in stressed syllables, but not in unstressed.
standaloneអ៊ុ
standaloneឧ
other17CBafter an inherent, series 2 vowel and before a labial final.
uː
o-classូ
standaloneអ៊ូ
standaloneឩ
e
a-class17B7Followed by a glottal stop in stressed syllables, but not in unstressed.
standaloneអិ
eː
o-class17C1Followed by a glottal stop in stressed syllables, but not in unstressed.
standaloneអេ
standaloneអ៊ែ
o
a-class17BBFollowed by a glottal stop in stressed syllables, but not in unstressed.
standaloneអុ
standaloneឧ
oː
o-class17C4Followed by a glottal stop in stressed syllables, but not in unstressed.
standaloneអូ
standaloneអ៊ោ
ə
a-class17B7
a-class17B9
a-class17C1before palatals.
standaloneអ៊់
standalone17A5
əː
a-class17BE
standaloneអ៊
standaloneអឺ
ɛː
o-class17C2
standaloneអ៊ែ
ɔː
O-class inherent voweleg. គ kɔːmute
standaloneអ៊
a
a-class17D0
a-class17B6 25CC 17CB
standaloneអា់
aː
a-class17B6
standaloneអា
ɑ
a-class17CBafter an inherent, a-series vowel.
standaloneអ់
ɑː
A-class inherent voweleg. ក kɑːneck
standaloneអ
vowel sign៏Used over two consonants to indicate that they represent two specific words.
Diphthongs and rhymes
iə
o-class17B6
a/o-class17C0
ih
o-class17B7 17C7
o-class17C1 17C7
ɨə
a/o-class17BF
ɨj
o-class17D0 1799
o-class17C3
ɨw
o-class17BC 179C
o-class17C5
uə
a/o-class17BD
uə̆
o-class17CBafter an inherent, series 2 vowel and before a non-labial final.
Coda diacritics. Some Khmer codas can be written using combining marks.
Silencer marks. These can cancel sounds of vowels and consonants.
Conjunct stacks
In Khmer, word-internal clusters are very common at the beginning of a word, but clusters also occur medially in multisyllable words, and occasionally at the end of a word.
The absence of a vowel sound between two or more consonants is visually indicated by stacked consonants (only), where the non-initial consonant appears below the initial, typically with a different shape from normal.
Word boundaries. Clusters do not span word boundaries. Consonant clusters formed by the end of one word and the beginning of the next do not lead to stacking in Khmer.
Conjunct formation
In Unicode, the stacking behaviour is achieved by adding 17D2 between the consonants. This character has no visual representation in normal Khmer text, however most fonts render it as a small cross when used alone or without a following consonant. It is never visible when used in consonant clusters.
Subscript consonant forms are called ជើងអក្សរ (or 'coeng', pronounced cəːŋ).
Cambodians see these subscripts as distinct letter forms, but, unlike Tibetan, they are produced in Unicode by inserting 17D2 before the consonant that will become a subscript. This character, which has no visual form in Cambodian, is called the coeng in Unicode, although it should rightly be called the coeng generator.
All the shapes are simplified and reduced in size compared to the non-subscript form. Many have significantly different shapes.
Examples:
ម,្,ផ,ម្ផ
ស,្,ន,ស្ន
ឌ,្,ឍ,ឌ្ឍ
ត,្,រ,ត្រ
Examples of stacked conjuncts.
As can be seen in fig_stacked, 179A produces a subjoined form that wraps to the left and under the preceding consonant. Several others wrap below and to the right of the consonant. 17A1 doesn't normally appear in subscript form.
Show consonants in their normal and subjoined forms
Shows the same consonant before and after a coeng.
Some subscripts change the sound of the preceding consonant.
Stacks commonly occur in multisyllabic words. A medial cluster will typically contain a final consonant for the first syllable and the initial consonant of the next syllable. Vowel signs never split conjuncts, but instead treat them as a single unit.
eg.
ចង្កើះ
ច,ង,្,ក,ើ,ះ
Some clusters involve two subscripts. These are, with 3 exceptions, composed of a final nasal, followed by a stop and r.
eg.
កន្ត្រៃ
ក,ន,្,ត,្,រ,ៃ
កញ្ជ្រេង
ក,ញ,្,ជ,្,រ,េ,ង
The 3 exceptions are loan words.
អង្គ្លេស
សងស្ក្រិត
សាស្ត្រាចារ្យ
Subscript consonants that appear at the end of a word, are silent.
eg.
ពេទ្យ
ព,េ,ទ,្,យ
រដ្ឋ
រ,ដ,្,ឋ
Stacks and registers
Where the two consonants involved in the cluster are in different classes or registers, the pronunciation of any following vowel is normally determined by the register of the subscript consonant. For the following exceptions, however, the vowel pronunciation is determined by the register of the first consonant (all ɔ-class):
ង,ញ,ន,ម,យ,រ,ល,វ
Combining characters & stacks
Most vowels that are pronounced after a consonant stack are displayed as if they were attached to the consonant at the top of the stack (including pre-base vowel signs and circumgraphs).
Click on the examples to see the underlying sequence more clearly.
eg.
ក្លិន
ឆ្វេង
ភ្លៀង
This can also lead to ligation between the top consonant in the stack and a vowel sign, unless the subjoined consonant is right-spacing.
eg.
ក្ដារ
ក្រាក់
ក្បាល
The exceptions are the vowel signs that appear below the consonant; these appear below the last subjoined form, unless the subjoined form is left-spacing.
eg.
ខ្ពុរ
ត្រុំ
Other diacritics are treated in a similar fashion. This can lead to ambiguity if a diacritic could modify either consonant in a stack.
Subscript consonants after vowels
It is rare but possible to find subscripts used after independent vowels. One common word spelled this way is ឲ្យ
It is also possible to find subscript forms of independent vowels. Four of these are named sequences in Unicode.
Unmarked vowel absence
While many consonant clusters are represented by conjunct stacks, it is not difficult to find words where the vowel absence is not marked, particularly after syllable codas.
eg.
កកកុញ
ក,ក,កុ,ញ
Note the ambiguity in the spelling. There is nothing to indicate that the first two characters in the word above are pronounced kaːʔ, rather than ka.kaː, as in
កករ
Inherent vowels are not usually pronounced after syllable final consonants at the end of a word.
eg.
កាល
កំពុក
However, there are exceptions, such as
កលហ
Silencers
Khmer has diacritics that silence vowels or parts of the text.
៍,៌,៑,៝
The following two diacritics are used to silence written characters.
17CD is used over a consonant, particularly in loan words, to silence it and any attached vowels or subscripts.
eg.
សប្ដាហ៍
រេហ៍ពល
កេរ្តិ៍
17CC is not very common and word-medially may produce rə before the consonant it sits on. When it appears word-finally, it may silence the final consonant (and may also affect vowel sounds).
eg.
បរិបូណ៌
17D1, the sanskrit virama, is sometimes used in Sanskrit words to indicate that a final consonant has no vowel sound.
eg.
អាត្មន៑
17DD, on the other hand, is a rarely used sign that indicates that a final consonant retains its inherent vowel sound.
(Checks are needed for the detailed information for each of the above marks, since this section only looks at the use for silencing sounds.)
Consonants
ɑ-class register
ɔ-class register
Onsets
ប៉,ត,ច,ក,ហ្គ,អ
ព,ទ,ជ,គ,ហ្គ៊
ប,ដ
ឌ
ផ,ថ,ឋ,ឆ,ខ
ភ,ធ,ឍ,ឈ,ឃ
ហ្វ,ស,ហ្ស,ហ
ហ្វ៊,វ,ហ្ស៊
ហ្ម,ណ,ហ្ន
ម,ន,ញ,ង
ហ្ល
រ,ឡ,ល,យ
Cluster initial
ប,ផ,ត,ដ,ថ,ឋ,ក,ដ,ខ
ព,ភ,ទ,ឌ,ធ,ឍ,គ,ឃ
Codas
ព,ប,ផ,ភ,ទ,ដ,ឌ,ថ,ឋ,ធ,ឍ,ក,គ,ខ,ឃ
ច,ជ
ម,ណ,ន,ញ,ង
វ,រ,ល,យ
Basic consonants
This shows consonants in use in modern Khmer, although some are not widely used.
Khmer is not tonal, but each consonant character belongs to one of two classes (see consonant_registers). The class of a consonant determines the vowel sound in a syllable, however this can also be changed (see register_change).
Some letters have different sounds when they appear in the syllable onset and the syllable coda. Some also have different pronunciations when they appear at the beginning of a consonant cluster in the onset (see onsets).
Click on each letter for more details and for examples of usage.
Where pronunciation differs, forms such as p- indicate the sound at the start of a consonant cluster, and -p at the end of a syllable.
ɑ-class
ព,ភ,ទ,ឌ,ធ,ឍ,គ,ឃ,ជ,ឈ,ម,ន,ញ,ង,វ,រ,ឡ,ល,យ
ɔ-class
ប,ផ,ត,ដ,ថ,ឋ,ក,ខ,អ,ច,ឆ,ស,ហ,ណ
The following 3 consonants are obsolete, and used only for Pali/Sanskrit transliteration.
ឝ,ឞ,ៜ
Additional consonants
Special combinations are used to represent non-native sounds in loan words, especially from French and Thai. These include the following, most of which involve a stack beginning with ហ.
ប៉,ហ្គ,ហ្គ៊,ហ្វ,ហ្វ៊,ហ្ស,ហ្ស៊
Changing consonant registers
There are not enough individual Khmer consonant letters to be able to assign a unique character for each ɑ-class and ɔ-class register. Khmer extends the number of letters as follows to close this gap.
៉,៊
Two diacritics, 17C9 and 17CA, are used to change the class of a consonant. These are particularly useful when a given sound has only one character associated with it, such as the letters ម, យ and ស etc.
17C9 changes the register of a consonant from ɔː to ɑː, affecting the inherent vowel and any other vowel following the consonant.
eg.
មក
ម៉ប
17CA changes the register of a consonant from ɑː to ɔː, affecting the inherent vowel and any other vowel following the consonant.
eg.
បែង
ប៊ែន
These diacritics appear above the base consonant or stack by default, but if another combining mark (such as a vowel sign) appears above the base (for certain consonants) the register shifter may move below the base and looks identical to 17BB (see consonant_shift_posn).
Regardless of displayed position, each of these diacritics should be typed and stored immediately after the base character, unless a ZWNJ intervenes.u§647
A small number of ɔ-class consonants are transformed into ɑ-class consonants by preceding them with 17A0, rather than using the above diacritics. They include the following.
ហ្ម,ហ្ន,ហ្ល
Onsets
Word-initial consonant clusters are relatively common in Khmer. These include sounds commonly referred to as medials, such as -r and -l, but also a wider assortment of consonant clusters.
eg.
ក្ដារ
ឆ្កែ
ធ្មេញ
ផ្សែង
The consonant clusters are written as stacks, using the coeng. See clusters.
In addition, Khmer creates syllable-initial stacks using 17A0 followed by another consonant to create sounds from other languages, or to change the register for the subjoined consonant. These combinations produce a single consonant sound, unlike the former examples, but they are handled using the normal stacking mechanism. See extendedC.
Codas
Not all Khmer consonants can appear in syllable-final position. The most common syllable codas include the following:
ប,ត,ក,ម,ន,ញ,ង,ល
The pronunciation of the consonant in final position may differ from it's normal pronunciation, but it is not followed by a vowel sound.
Because ordinary letters are used in word-final position, and there are no indicators for syllable or word boundaries, it is difficult to parse Khmer or automatically generate pronunciation. For example, the following sequence could equally represent two syllables kɑːkɑː with inherent vowels, or one syllable with a final -k, pronounced kɑːʔ.
កក
Two final consonant sounds -m and -h can also be produced using combining characters. See nikahit_reahmuk for details.
Coda diacritics
ំ,ះ
In principle, the descendants of the anusvara and the visarga, 17C6 called និគ្គហិតniʔkəhət, and 17C7, called រះមុខreə̆hmuk produce a rhyme with the coda sounds -m and -h, respectively. But they also have an impact on the vowel in the syllable, and are regarded as vowels in Cambodia.
Used on their own, they can change the inherent vowel, affecting both the pronunciation and the meaning, eg. compare
ដមដំ
Nikahit can also follow vowel signs that would normally produce aː, and u/uː, and change their sound value. The following example shows its effect on the vowel sign 17B6u§643:
ពាមពាំ
The following panel lists rhymes following ɑ-class consonants.
ិះ,េះ,ែះ,ុះ,ុំ,ឹះ,ើះ,ះ,ោះ,ាំ,ំ,ាំង
The next panel shows rhymes following ɔ-class consonants. In several cases the same vowel sign is used, but with a different pronunciation.
ិះ,េះ,ោះ,ុះ,ុំ,ំ,ះ,ាំង,ាំ
The 2 following sequences are regarded as letters in the Khmer alphabet. They are not encoded separately in Unicode (but they are named sequences).
ាំ,ុំ
Consonant sounds to characters
This section maps Cambodian consonant sounds to common graphemes in the Khmer orthography. Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc.
The far right of a line shows the subjoined shape for a letter. Light coloured letters or subjoined forms indicate that this is used infrequently.
p
a-seriesព៉
a-seriesប៉for loan words
a-seriesបIn some words, by convention.
្ព⏴
o-seriesព+ cluster initial + coda
cluster initialប្
cluster initialភ្
cluster initialផ្
coda
—ប
coda
—ភ
coda
—ផNot common.
pʰ
្ផ⏴
a-seriesផ
្ភ⏴
o-seriesភ
ɓ
្ប⏴
a-seriesប
o-seriesប៊
t
្ត⏴
a-seriesត+ cluster initial + coda
្ទ⏴
o-seriesទ+ cluster initial + coda
cluster initialថ្
cluster initialឋ្
cluster initialធ្
coda
—ថ
coda
—ឋ
coda
—ដ
coda
—ដ្ឋ
coda
—ឌ
coda
—ថ
coda
—ធ
coda
—ឍ
tʰ
្ថ⏴
a-seriesថ+ cluster initial
្ឋ⏴
a-seriesឋ Only used in a few words of Pali or Sanskrit origin.
្ធ⏴
o-seriesធ
្ឍ⏴
o-seriesឍOnly used in a few words of Pali or Sanskrit origin.
ɗ
្ឌ⏴
o-seriesឌRare and only used in a few words of Pali or Sanskrit origin.
a-seriesដ+ cluster initial
a-seriesតat the beginning of two syllable words where the first syllable ends with final nasal.
c
្ច⏴
a-seriesច+ cluster initial + coda
្ជ⏴
o-seriesជ+ cluster initial + coda
cluster initialឈ្
cluster initialឆ្
cʰ
្ឆ⏴
a-seriesឆ+ cluster initial
្ឈ⏴
o-seriesឈ+ cluster initial
k
្ក⏴
a-seriesក+ cluster initial + coda
្គ⏴
o-seriesគ+ cluster initial + coda
cluster initialខ្
cluster initialឃ្
coda
—ខ
coda
—ឃ
kʰ
្ខ⏴
a-seriesខ
្ឃ⏴
o-seriesឃ
cluster initialក្when followed by a subscript 1798, 1793, or 179B.
cluster initialគ្when followed by a subscript 1798, or 1793.
ɡ
a-seriesហ្គfor loan words
o-seriesហ្គ៊for loan words
ʔ
្អ⏴
a-seriesអ+ cluster initial or ∅
o-seriesអ៊
coda
—កafter one of these vowels a, aː, ɑ, ɑː, eə̆, uə̆, iə, ɨə, uə
coda
—គafter one of these vowels a, aː, ɑ, ɑː, eə̆, uə̆, iə, ɨə, uə
coda
—ខafter one of these vowels a, aː, ɑ, ɑː, eə̆, uə̆, iə, ɨə, uə
coda
—ឃafter one of these vowels a, aː, ɑ, ɑː, eə̆, uə̆, iə, ɨə, uə
f
a-seriesហ្វfor loan words
o-seriesហ្វ៊for loan words
s
្ស⏴
a-seriesស+ cluster initial + code only in very formal reading style
o-seriesស៊
ʒ z
a-seriesហ្ស
o-seriesហ្ស៊
h
្ហ⏴
a-seriesហ
o-seriesហ៊
coda
—ស
coda
—ះThis represents -ah after a 1st class consonant, and -eə̆h after a 2nd class consonant.
m
a-seriesម៉
a-seriesហ្ម
្ម⏴
o-seriesម+ cluster initial + coda
coda
—ុំ
coda
—ំ
coda
—ាំ
n
្ណ⏴
a-seriesណ+ cluster initial + coda
a-seriesហ្នin some words.
្ន⏴
o-seriesន+ coda
ɲ
a-seriesញ៉
្ញ⏴
o-seriesញ+ coda
ŋ
a-seriesង៉
្ង⏴
o-seriesង+ coda
coda
—ញafter iː.
w
codaវwhen it appears in the syllable coda as a final glide.
codaៅ
ʋ
a-seriesវ៉
្វ⏴
o-seriesវ
r
a-seriesរ៉
្រ⏴
o-seriesរ
rɨ
vocalicឫ
rɨː
vocalicឬ
l
្ឡ⏴
a-seriesឡ
a-seriesហ្ល
្ល⏴
o-seriesល+ cluster initial + coda
lɨ
vocalicឭ
lɨː
vocalicឮ
j
a-seriesយ៉
្យ⏴
o-seriesយ+ coda, though in syllable-final position it may be pronounced iː, too.
coda
—ៃ
Encoding choices
This section compares code point usage and considers the relevance of Unicode Normalisation Form D (NFD) and Unicode Normalisation Form C (NFC) to give guidance on which approach is best.
Vowel signs
In some fonts, two circumgraphs look the same whether they are written as a single character, or as two.
Recommended
Not recommended
17BE
17C1 17B8
17C4
17C1 17B6
For Khmer, single and multiple code point realisations do not normalise to be the same in NFC or NFD, so you are creating different content by using one approach or the other. This may affect various operations on the text, and it is therefore better to stick with one representation. The Unicode Standard surprisingly makes no comment on this, although it does for other scripts, where it encourages use of the precomposed, single code point.
Also, some fonts may not display the decomposed sequences correctly.
Deprecated code points
The following code points are deprecated by the Unicode Consortium and considered errors in the encoding. Use those in the recommended column, instead.
Use
Do not use
17A2
17A3
17A2 17B6
17A4
Discouraged code points
The use of the following code points is discouraged by the Unicode Consortium. Use the code points in the recommended column, instead.
Use
Do not use
17D4 179B 17D4
17D8
᧠U+19E0 KHMER SYMBOL PATHAMASAT
17E8 17D3
Inherent vowel letters
Do not use
17B4
17B5
The invisible characters 17B4 and 17B5 were originally intended to represent a phonetic difference not expressed by the spelling, so as to assist in phonetic sorting, however, the Unicode Standard considers them insufficient for that purpose and errors in the encoding, and they should not be used.u§677
Codepoint sequences
Components of an orthographic syllable should be composed in the following order:
base consonant or independent vowel
rɔɓaːt
museʔkətoə̯n or trəisaɓ (register shifters)
subscript (consonant or independent vowel)
vowel sign
zero-width joiner or non-joiner
any other mark
This fixed ordering makes it easier to search for and collate text. For more details, see this SIL document.sil
Numbers, dates, currency, etc.
Khmer has its own set of decimal digits, although western digits are also used sometimes.
០,១,២,៣,៤,៥,៦,៧,៨,៩
The thousands separator is ., and decimal separator is ,.
Ranges and dates use the ASCII hyphen.ws§#Spacing_and_punctuation
Currency
៛
The symbol 17DB (សញ្ញារៀលsɲ͓ɲāṟiᵊḻsaɲ ɲaː riəl) is placed after the amount, eg. ៣.០០០ ៛ɓej poan riəl3,000 riel. Sometimes 179A is used instead.
Other
The Unicode Khmer block contains a set of numeric symbols for divination lore.
៰,៱,៲,៳,៴,៵,៶,៷,៸,៹
Use of 17D3 is discouraged in favor of the complete set of lunar date symbols.
The Khmer Symbols block is entirely composed of Lunar date symbols.
Modern Khmer has several distinct styles of font, each of which is used for different purposes.
Most modern typefaces are set in an upright style (called អក្សរឈរʔk͓sṟc̱ʰṟʔɑːksɑː cʰɔː or អក្សរត្រង់ʔk͓sṟt͓ṟŋ˘ʔɑːksɑː trɑŋ).ws§#Styles This is the style used for this page.
Text in an âksâr chôr font style.
A slanted style (អក្សរជ្រៀងʔk͓sṟc̱͓ṟiᵊŋʔɑːksɑː criəŋ) is sometimes used for whole documents or novels. The oblique styling has no affect on the semantics of the text.ws§#Styles
The same text in an âksâr chriĕng font style.
The round style (អក្សរមូលʔk͓sṟm̱ūḻʔɑːksɑː muːl) has heavier, more rounded letter shapes, and includes more ligated forms. It is commonly used for titles and headings in Cambodian documents, books, or currency, as well as on shop signs or banners. It may also be used to emphasise important names or nouns.ws§#Styles The regular font weight looks like bolded text in comparison to the upright font style.
The same text in an âksâr mul font style.
Another style (អក្សរខមʔk͓sṟkʰm̱ʔɑːksɑː kʰɑːm), characterized by sharper serifs and angles and retention of some antique characteristics, is used for yantra text in Cambodia as well as in Thailand.ws§#Styles
An example of a page that mixes upright (regular and bold) with mul font styles. (Click on the image to see bigger.)
Context-based shaping & positioning
This section mentions a handful of exceptions to the general rule that there is very little in the way of interaction between characters other than where the subscript shapes are used after the coeng generator.
Subjoined consonants can be quite different shapes from those of the corresponding base consonant, and those shapes can be seen in clusters. However, some additional reshaping of glyphs is needed to cope with stacking of characters. Compare for example the length of the final element fig_long_subjoined_yo.
The subjoined form of 1799 is lengthened when it is the second subjoined consonant.
Glyph order
Although all combining characters follow the base in memory, the visual order of syllable components may not follow a linear progression from left to right. In the following example the order in which the glyphs are pronounced is far left, far right, down, left, left: កន្ត្រៃ In the word ច្រៀង the spoken order of the separate visible parts, numbered left to right, is 3,2, 1+4, 5, Some vowel signs span two or three sides of the base consonant or cluster.
Joining forms for AA
Some small joining features occur in relation to 17B6 and similarly shaped vowels. Unicode provides the following list of common forms:
ក + ា = កា
ប + ា = បា (avoids confusion with ហ )
ប + ៅ = បៅ
្ស + ា = ្សា
Register-shifter position
The function of the register-shifter marks is described in register_change.
When 17C9museʔkətoə̯n or 17CAtrəisaɓ appears with a vowel sign above the consonant, the
ក្បៀសក្រោមkɓiəhkraom
form may be used. This looks exactly like 17BB.
See fig_posn_muse.
Alternative positions and shapes of MUUSIKATOAN.show composition
Alternative positions and shapes of TRIISAP.show composition
អ៊ូ
show composition
អ៊ី
The Unicode Standardu§647 gives the impression that both of these diacritics are moved below the consonant any time a vowel appears over that consonant. However, in reality only certain consonants cause this behaviour. The behaviour varies a little by font, but in general the MUUSIKATOAN diacritic is lowered for the following letters:
If needed, this behaviour can be modified using 200C, if the font recognises it, to prevent the low form appearing. The ZWNJ must be typed and stored between the base consonant and the register-shifter. See fig_zwnj_triisap for an example using ប្រតឺងអ៊ឹះ.
TRIISAP rendered above the consonant by using ZWNJ immediately before it (left), when it would otherwise be moved below the consonant (right).show composition
ប្រតឺងអ៊ឹះ
Observation: Textarea entry fields on the Mac don't seem to recognise the ZWNJ character (mentioned below) and incorrectly display the combining characters that follow it. The text looks ok if the browser displays the sequence as part of the HTML.
NYO with subscripts
Another common feature is that ញ drops the swash below the baseline when followed by a subscript consonant.
The normal, full shape of NYO (left), and the reduced shape when a subjoined consonant follows (right).show composition
ឃើញ
show composition
បញ្ជី
Also, when it appears as a subscript under itself it uses a special full form subscript (see fig_nyo_subj).
The normal subjoined shape of NYO (left), and the special shape when gemination causes it to be subjoined below itself (right).show composition
ប្រាជ្ញា
show composition
កញ្ញា
Vowel ligatures
In the âksâr mul style, some vowel signs ligate with the consonant characters to which they are applied. See the word វិទូ in fig_vowel_ligatures.
The sound vi written as a ligature (left) and with no ligature (right) in the âksâr mul style.show composition
វិទូ
Observation: This behaviour is font dependent. For example, the Khmer Mool font (used for the figure), and Khmer OS Muol produce the ligation, but the Khmer Ratanakiri font does not.
To prevent a ligature forming, use 200C (ZWNJ) between the consonant and the vowel. To cause a ligature to form when there isn't one, if the font has the appropriate rules, use 200D (ZWJ) instead.u§647
Managing glyph shaping
Content authors can use 200C and 200D to change the position of register shifters (see consonant_shift_posn), and to manage ligatures in mul fonts (see vowel_ligatures).
Typographic units
Word boundaries
Khmer words are not separated by spaces, nevertheless Khmer should be wrapped at word boundaries.
Sometimes 200B may be used to indicate appropriate break-points.
Some other languages that use the Khmer script, such as Krung and Tampuan, do separate words with narrow spaces such as 2006,
and separate phrases with a wider space such as 2003.sil§5
Names
- (called សហសញ្ញាsɑːhɑː sɑːɲɲiə) is used between the parts of a person's name. Typically the family name (written first) and following names, but often all names for Chinese Cambodians.
eg.
ញ៉ុក-ថែមɲok tʰaem
លី-ធាម-តេងliː tʰiəm teiŋ
Graphemes
This section is still undergoing research and development.
Grapheme clusters alone are not sufficient to represent typographic units in Khmer. Conjunct stacks are common and must not be split apart by edit operations that visually change the text (such as letter-spacing, first-letter highlighting, and in-word line breaking). For those operations one needs to segment the text using orthographic syllables, which string grapheme clusters together with an invisible stack generator. This character is never visible, so Khmer doesn't have the problems of ambiguity that affect various other Brahmi-derived scripts.
The Khmer stack former (coeng) is 17D2, which has an Indic Syllabic Category of Invisible_Stacker.
Grapheme clusters
Base ZW(N)J? Combining_mark*
This fixed ordering makes it easier to search for and collate text. For more details, see this SIL document.sil
Combining marks may include zero or more of the following types of character.
Final consonant marks [2] (see nikahit_reahmuk) One of 2 possible combining marks, at the end of a grapheme cluster sequence. (Cambodians consider these to be vowels.)
Coeng generator [1] (see subscript_consonants) Normally occurs immediately after a consonant at the beginning of a cluster. It sometimes also appears after an independent vowel.
In some cases, a ZWNJ is inserted between a consonant and a consonant shifter in order to specify special shaping rules for the shifter (see consonant_shift_posn).
To prevent or encourage the formation of ligatures (especially for mul fonts) a ZWNJ or ZWJ can be inserted between a consonant and following dependent vowel (see vowel_ligatures).
The following examples show a variety of grapheme clusters:
Click on the text version of these words to see more detail about the composition.
បរិបូណ៌
ប៉ាន
នុ៎ះន៎
ចង្អូរ
កញ្ជ្រេង
ប្រតឺងអ៊ឹះ
The last syllable of the last item in the list contains a ZWNJ (to keep the register shifter above the base).
Note how grapheme clusters segment the parts of a conjunct after the virama. This is not always desirable (see orthographicS just below).
Larger typographic units
(Consonant Coeng)* Grapheme_cluster
Khmer commonly stacks glyphs, to form conjuncts (see clusters). These conjuncts represent consonant clusters or gemination. The stacking does not occur across word boundaries; only within words.
Grapheme clusters terminate after a sequence of marks that includes a coeng indicator code point, but editorial operations that change the visual appearance of the text, such as letter-spacing, first-letter highlighting, line-breaking, and justification, should never split stacked forms apart. For this reason, an alternative way of segmenting graphemes is needed. This may not apply, however, for some other operations such as cursor movement or backwards delete.
Where stacks appear, a typographic unit contains multiple grapheme clusters. The non-final grapheme clusters all end with 17D2, which is never visible, and the final grapheme cluster begins with a consonant.
The following are examples. Some of these examples were shown in the previous section: here the stack is treated as a single typographic unit.
Click on the text version of these words to see more detail about the composition.
ចង្អូរ
កញ្ជ្រេង
អភិវឌ្ឍ
ភ្លៀង
Browser behaviour
Test in your browser.The words test units that equate to grapheme clusters only, and others that include conjuncts. First, the text is displayed in a contenteditable paragraph, then in a textarea. Results are reported for Gecko (Firefox), Blink (Chrome), and WebKit (Safari) on a Mac.
បរិបូណ៌ប៉ានចង្អូរកញ្ជ្រេងឲ្យប្រតឺងអ៊ឹះ
Cursor movement.Move the cursor through the text.
Gecko and Blink step through the text using grapheme clusters. It takes 2 or more steps (depending on the number of GCs) to get through the stacks, one grapheme cluster at a time. In some cases the cursor may look as if it is not moving. WebKit steps through all words using the orthographic syllables as described here (ie. they step over a stack and all associated combining characters in one jump), except that WebKit treats the ZWNJ as the start of a new grapheme cluster, requiring an extra jump to get past it.
Selection.Place the cursor next to a character and hold down shift while pressing an arrow key.
The behaviour is the same as for cursor movement.
Deletion. Forward deletion works in the same way as cursor movement. The backspace key deletes code point by code point, for all browsers.
Line-break.See this test. The CSS sets the value of the line-break property to anywhere. Change the size of the box to slowly move the line break point.
Gecko and Blink set break opportunities based on orthographic syllables. WebKit wraps on grapheme cluster boundaries, but gets rather confused by the stacks, typically wrapping half the stack plus one adjoining (non stack) character together.
Punctuation & inline features
Phrase & section boundaries
Khmer uses mostly native punctuation marks, but also a couple of ASCII punctuation.
Space. Although Khmer words are not separated by spaces, the space (ឃ្លាkliə) is used, and is regarded as punctuation, similar to the comma. Huffman lists the following uses:
between clauses within a sentence
between sentences in a cohesive group of sentences
after preposed adverbial phrases, such as 'usually', 'today', 'in that town', etc.
before and after proper names
before and after numbers
before and after the symbols ។ and ៗ and the terms ។ល។ and ។ប។
between coordinate words in lists
Huffman gives the following example to show the use of the space:
ថ្ងៃនេះ ខ្ញុំទៅផ្សារ ទិញក្រច អង្ករ ហើយនឹងអីវ៉ាន់ផ្សេង ៗ tŋajnih kɲomtɨwpsaː tiɲkrouc ʔɑŋkɑː haəjnɨŋʔəjʋanpseiŋ pseiŋ Today ( ) I'm going to the market ( ) to buy oranges ( ) rice ( ) and various things.
As mentioned in word, some other languages use narrow spaces to separate words, and wide spaces, such as the EM SPACE, to separate phrases
Phrasal punctuation marks. Khmer also uses ។ to mark the end of sentences, although a series of sentences on a related topic tend to be separated by space instead.
៖ is used in much the same way as a western colon.
Question & exclamation marks. Khmer uses Western punctuation marks, eg. ហេត៊អ្វី?haetʰ aʋəi, and កុំ!kom.
Very rarely, the combining character 17CE can be used over the final consonant of a word like an exclamation mark, to convey excited emphasis.
eg.
ណែ៎nɛːHey!
នុ៎ះន៎nuhnɔːOver there!
Section boundaries.៕ can be used to close a chapter, or an entire text.
Text start and end. Poetic and religious texts typically start with ៙ and end with ៚.
Bracketed text
Khmer commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Quotations & citations
Khmer texts typically use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
“
”
nested
‘
’
According to CLDR, the default quote marks for Khmer should be, reading right to left, “...”. When an additional quote is embedded within the first, the quote marks should be ‘...’.
Emphasis
17CE is very rare, but is used over the final consonant of a word like an exclamation mark, to convey excited emphasis.
eg.
ណែ៎នុ៎ះន៎
Emphasis may also be conveyed by repeating words (see repetition).
Abbreviation, ellipsis & repetition
Ellipsis
The following word (pronounced laʔ) is used as the equivalent of 'etc.'
។ល។
A character exists that represents that sequence, ៘, but the Unicode Standard deprecates it, and recommends the use of the three separate characters instead.u
៘
Other spellings for et cetera also exist. These include:
។បេ។
–បេ–
–ល–
Repetition
It is common to repeat words or sometimes phrases in Khmer, particularly to provide emphasis. ៗ (called លេខទោleːktoː) can be used for this.
eg.
ខ្លាំង ៗklaŋklaŋvery strong
គាត់មានផ្ទះថ្មី ៗkaːtʰ miən pʰteə̯h tʰməitʰməihe has a brand new house
Sometimes this sign repeats a phrase rather than a word.
eg.
បន្តិចម្ដង ៗɓɑntecmɗɑːŋ ɓɑntecmɗɑːŋlittle by little
It is also occasionally used to repeat the word at the end of a sentence for the beginning of a new sentenceh.
The sign is usually separated from the text by a space.
Line & paragraph layout
Line breaking & hyphenation
Although Khmer doesn't use spaces or dividers between words, the expectation is that line-breaks occur at word boundaries.
There are three basic types of Khmer word, shown in the figures that follow. The first two types cannot be broken, but the third type can be broken where indicated by the vertical lines.Hong (Github)§https://github.com/w3c/sealreq/issues/4#issuecomment-384981313
Single, indivisible words.
show composition
កម្ម
ជាតិ
វិទ្យាល័យ
Words with prefixes and suffixes.
show composition
កម្មករ
អន្តរជាតិ
មហវិទ្យាល័យ
Compound words (combining 2, 3, or more single words).
show composition
កម្មផល
សកលវិទ្យាល័យ
ជាតិសាសន៍
Text is not broken at sub-word syllable boundaries. In fact, this is particularly difficult to do algorithmically in Khmer, because syllable-final consonants are indistinguishable from consonants with an inherent vowel that constitute a new syllable. Some kind of morphological analysis is needed.
Zero-width space & word-joiner
Because Khmer doesn't separate words, applications typically look up word boundaries in a dictionary, however, such lookup doesn't always produce the needed result, especially when dealing with compound words and proper names. To counteract these deficiencies, authors may use one of the following invisible characters.
In order to manually fine-tune word-boundary detection, the invisible character 200B (ZWSP) can be used to create breaks.u§625
To prevent a break between syllables, 2060 (WJ) can be used.
It is also important to bear in mind that Khmer may be used to write various languages, in particular minority languages for which different dictionaries are needed. Since such dictionaries may not available in a given browser or other application, there is a tendency to use ZWSP in order to compensate.
Large-scale manual entry of ZWSP and WJ has potential downsides because the user cannot see them; this leads to problems with ZWSP being inserted in the wrong position, or multiple times. However, these don't set a state, so it doesn't create major issues. It would be useful, however, if an editor showed the location of these characters.
Care should also be taken when trying to match text, eg. for searching in a page. WJ should be ignored. ZWSP may or may not be ignored, depending on whether word boundaries are significant for the search.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for characters used in modern Cambodian. Context may affect the behaviour of some of these and other characters.
Click on the Khmer characters to show what they are.
“ ‘ ( should not be the last character on a line
” ’ ) ? ! ។ ៕ ៚ % should not begin a new line
៛ should be kept with any number, even if separated by a space or parenthesis.
The following character should not produce a line-break when they appear inside or alongside a word: ៙.
Baselines, line height, etc.
Khmer uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
To give an approximate idea, fig_baselines compares Latin and Khmer glyphs from Noto fonts. The basic height of Khmer letters is typically around the Latin ascender height in one, and around the x-height in the other, however extenders and combining marks, extend well beyond the Latin ascenders and descenders, creating a need for larger line spacing.
Font metrics for Latin text compared with Khmer glyphs in the Noto Serif Khmer (top) and Noto Sans Khmer (bottom) fonts.
fig_baselines_other shows similar comparisons for the Khmer MN and Mondulkiri fonts.
Latin font metrics compared with Khmer glyphs in the Khmer MN (top) and Mondulkiri (bottom) fonts.
Counters, lists, etc.
You can experiment with counter styles using the Counter styles converter. Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
The modern Khmer orthography uses numeric and alphabetic styles.
Numeric
The khmer numeric style is decimal-based and uses these digits.rmcs
០,១,២,៣,៤,៥,៦,៧,៨,៩
eg.
១,២,៣,៤,១១,២២,៣៣,៤៤,១១១,២២២,៣៣៣,៤៤៤
Alphabetic
The cambodian-consonant alphabetic style for the Khmer language uses these letters.