This page brings together basic information about the Garay script and its use for the Wolof language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Wolof using Unicode.
The Garay font used for this page is still an early prototype. It sometimes doesn't place combining marks correctly, eg. above uppercase base characters. When looking at examples allowances need to be made for the fact that this is a very early implementation.
The Wolof language is spoken by around 40% of Senegalese, and others in Mauritania and The Gambia. There are around 5.5 million native speakers in Senegal, and the total number of speakers is a little over 12 million.
The Garay script ( ɡaraj ) was created by Assane Faye in Senegal and published in January 1961. The official script in Senegal for Wolof is Latin, although the Wolofal script (an Arabic-based script written in the ajami style) is also used. The user community for Garay is small, including women’s groups and adult literacy for Mandinka as well as for Wolof. The script has been taught informally for more than fifty years since its invention. Faye has written manuscripts including textbooks, folktales, and maps; there also exists a Quran with interlinear translations into Wolof using the Garay script.e
Faye designed Garay to be easy to learn, familiar to anyone who had learned some of the Arabic script, but gave it a simpler design.e
The Garay script is an alphabet, ie. all vowels are written explicitly, alongside consonants; there is no inherent vowel in a consonant (abugidas), certain vowels are not systematically dropped (abjads), and consonant and vowel are not combined in the same character (syllabaries).
Vowels Vowels are written using 5 code points, including 1 combining mark, to write 9 vowel sounds. The shortfall is made up by combining vowel code points into digraphs. Long vowels are indicated by following the vowel character(s) with 10D4E.
The sign for the vowel ɛ is identical to the sign that indicates prenasalisation, and the combining mark 10D69 is used in both cases. When stops that can be prenasalised are followed by the sound ɛ they use 10D4D for the vowel, rather than the normal combining mark.
The Garay Unicode block also has a combining mark, 10D6D, to indicate nasalisation, however it isn't clear whether this is used.
Standalone vowels at the beginning of a word are written with a preceding, bicameral 'vowel carrier' (10D70), much like the alef in Arabic.
Languages in the Atlantic group of the Niger-Congo family, of which Wolof is one, are unusual for West Africa in that they are not tonal.
Consonants Garay has 19 basic consonant to write 21 basic consonant sounds – the difference is made up by one digraph and one diacritic. All this duplicated in upper- and lowercase. One more digraph and 3 letters with diacritics add 4 extra consonant sounds for use with other languages.
Four additional pre-nasalised stop sounds are indicated using the diacritic 10D69 (which also doubles as a vowel).
Consonant gemination is common and phonetically distinctive, and is written using the dedicated combining mark 10D6A.
Vowel absence The Garay orthography has 10D4F to signal that no vowel appears after a consonant. It is a spacing letter. According to Rovenchak, Faye, and Riley, it is now obsolete. Consonant clusters do not occur in word-initial position, but can occur medially and in final position, where they may be followed by a faint epenthetic schwa. There is no special mechanism for indicating consonant clusters.
NumbersA set of Garay digits is used, as well as a few Garay mathematical symbols.
Layout Garay text runs right to left in horizontal lines. Words are separated by spaces. The orthography is not fully bicameral. Consonant letters, including the word-initial vowel carrier, have uppercase and lowercase forms, but characters used to write vowels do not.
Line-breaking and justification are primarily based on inter-word spaces, but Garay uses a special character as a hyphen when a word is broken by a line break.
The following represents the general repertoire of the Wolof languages and dialects.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Long vowel sounds are distinctive.
Consonant sounds
labial
alveolar
palatal
velar
glottal
stop
pb
td
cɟ
kɡ
ʔ
pre-nasalised
ᵐb
ⁿd
ᶮɟ
ᵑɡ
fricative
f
s
x
nasal
m
n
ɲ
ŋ
approximant
w
l
j
trill/flap
r
Vowel harmony
Vowels in suffixes tend to be altered due to vowel harmony, based on the advanced tongue retraction (ATR) of the word-initial vowel. There are some exceptions.
+ATR vowels are: i u é ó ë.
-ATR vowels are: e o a.
Authors differ in whether they reflect the vowel harmony in writing.
Tone
There is no tone in Wolof.
Structure
Gemination is common and occurs with all consonants except q, ʔ, f, s, and x.
Gemination and consonant clusters do not occur in word-initial position, but can occur medially and in final position, where they may be followed by a faint epenthetic schwa.
p, d, c, and k only occur formally in word-initial position, unless geminated (which is common), or following a nasal. However, word final b, j, and g are typically devoiced and become allophones of those consonants.
Vowels
Post-consonant
Word-initial
, ,
, ,
◌,,,
, ,
◌,,,
, ,
The initial letter in standalone vowels has a lowercase and an uppercase form (not shown in the table). All other vowel letters are unicameral. 10D7010D50
Vowels are lengthened (not shown here) using a following
Post-consonant vowels
Garay uses 5 vowel characters, one of which is a combining mark, to write 9 vowel sounds. Five of the vowel sounds are written using a combination of characters. None of these characters are bicameral. The vowels ɛ and e can each be written in one of 2 ways, depending on the consonant they follow.
The combinations of characters used can be seen in the section basicV, but they are also listed here for quick reference.
,,,,,,,,,,
The iʰ is a so-called 'strong' articulation of i, which is not reflected in the Latin orthography and is dialectal. In the past it was, incorrectly, romanised as ü.rsr§4
The following list shows the components used to create the basic vowels.
,,,,
The vowels ɛ and e
The vowels ɛ and e can each be written in one of 2 ways, depending on the consonant they follow.
,,,
The vowel ɛ is usually written using the combining mark, 10D69.
eg.
,,
However, the same mark is also used to indicate prenasalisation of 4 consonants.
,,,
eg.
,,
Therefore, to avoid ambiguity, the vowel ɛ is instead written using 10D4D after those consonants (even when not prenasalised!). Prenasalised consonants followed by ɛ are followed by both characters. The following list shows the 4 consonants followed by the sound ɛ, and the corresponding prenasalised consonants followed by the same vowel.
,,,, ,,,,
eg.
,,
The same applies to e, except that the default is 10D69 10D4D, and after those consonants this becomes 10D4D 10D4D. (In other words, it is the same as ɛ except that it adds an extra 'squiggle' in each case.)
,,,, ,,,,
eg.
,,
In addition to consonants that may be prenasalised, this alternative approach also applies to the following other letters which have a diacritic above their standard form.rsr§14
,,, ,,,
Finally, qɛ and qe are written in an idiosyncratic way.rsr§14
,,
In older versions of the script the comma-like glyph appeared over the squiggle, rather than over the consonant.
Vowel length
Long vowel sounds are written by following the vowel character(s) with .
eg.
,,,
Long and short vowel sounds are phonemically distinctive.
Nasalisation
Observation: The Garay block has 10D6D, but it's not clear how this is used. It appears in the second Garay Proposal documentrsr, but there is no information about it other than a code point assignment. It is also not clear why this is named 'consonant' nasalisation, unless it acts perhaps as a final consonant mark.
`,
Standalone vowels
,
For words that begin with a standalone vowel in the Garay orthography the vowel letter needs to be preceded by one of 10D70 or 10D50. This is analogous to the letter alef in Arabic.
eg.
There are 2 special cases. Word-initial ɛ, normally rendered using just a diacritic, is 10D70 10D4D 10D69.
And word-initial e is 10D70 10D4D 10D69 10D4Drsr§5.
Standalone vowels don't really occur in Wolof in word-medial position. Usually an extra consonant is slipped in before the vowel, like the j between the i and the a at the end of the word Australiarsr§7.
eg.
,,,,,
Vowel sounds to characters
This section maps Wolof vowel sounds to common graphemes in the Garay orthography.
Long vowel forms are shown to the right of a lowercase entry. Uppercase only affects the vowel-carrier for word-initial standalone positions; that form is not shown in the table, but it is .
i
post-consonant
word-initial
iʰ
post-consonant
word-initial
u
post-consonant
word-initial
e
post-consonant◌◌after most consonants.
post-consonantafter b, d, ɟ, and ɡ, whether or not they are pre-nasalised. Also after sˤ and z.
post-consonantafter q.
word-initial
o
post-consonant
word-initial
ə
post-consonant
word-initial
ɛ
post-consonant◌after most consonants.
post-consonantafter b, d, ɟ, and ɡ, whether or not they are pre-nasalised. Also after sˤ and z.
post-consonantafter q.
word-initial
ɔ
post-consonant
word-initial
a
post-consonant
word-initial
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
The Garay orthography has to signal that no vowel appears after a consonant. It is a spacing letter. According to Rovenchak, Faye, and Riley, it is now obsolete.rsr§10
Consonant clusters do not occur in word-initial position, but can occur medially and in final position, where they may be followed by a faint epenthetic schwa. There is no special mechanism for indicating consonant clusters.
Consonants
,,,,,,,
,,,,,,,
,
,
,,,
,,,
,,,,,,,,,
,,,,,,,,
,,,
,,,
,,,
,,,
Basic consonants
The following lists show the basic consonant letters for Garay, lowercase to the left and uppercase to the right.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
Combinations of characters have to be used to represent 2 other simple sounds:
,,
Pre-nasalised stops
,,,,,,
Pre-nasalised sounds are marked using the diacritic 10D69, and frequently occur word-initially as well as within a word.
Lowercase (left) and uppercase (right) forms of the prenasalised stop ᵐb.
Non-native sounds
To represent non-native sounds Garay adds one of the following to regular consonant letters.
,,
Examples of non-native sounds.
,,,,,,
Lowercase (left) and uppercase (right) forms of the consonant z, which uses diacritics attached to the letter for s.
Onsets
No special mechanisms are used for syllable-initial consonants, other than for prenasalised consonants (see prenasalisation).
Codas
No special mechanisms are used for syllable-final consonants.
Gemination
Consonant gemination is common and is phonemically distinctive in Wolof. Gemination is written by adding 10D6A over the geminated consonant.
eg.
When a gemination mark is used over the same letter as 10D69, the gemination mark should be typed and stored last, whether the other diacritic represents prenasalisation or a vowelrsr§4. See fig_gemination.
An example of gemination, where the consonant carries both a vowel and gemination diacritic.show composition
Observation: This makes sense in the case of prenasalisation, since the initial combining mark is closely associated with the basic quality of the consonant letter, but it appears slightly unusual when it actually represents a following vowel. Presumably, the order was dictated by the fact that the same combining mark is used for both roles, and a single ordering is preferred.
Historical letter forms
,,,
The letters in the list above are now obsoleted, but separate code points are available in Unicode for digitisation of legacy text.
Consonant sounds to characters
This section maps Wolof consonant sounds to common graphemes in the Garay orthography.
Uppercase letters are shown on the right.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
lc
b
lc
ᵐb
lc
t
lc
d
lc
ⁿd
lc
c
lc
ɟ
lc
ᶮɟ
lc
k
lc
ɡ
lc
ᵑɡ
lc
q
lc
ʔ
lcbefore word-initial vowels
f
uc
v
lc
s
lc
sˤ
lc
z
lc
ʃ
lc
ʒ
lc
x~χ
lc
h
lc
m
lc
n
lc
ɲ
lc
ŋ
lc
w
lc
r
lc
l
lc
j
lc
Numbers, dates, currency, etc
Digits
,,,,,,,,,
Garay has its own set of digits. A number with multiple digits is read left-to-right within the right-to-left flow of the text.
In expressions and ranges the items flow from right to left.
Letters with numeric values
Numeric values are assigned to various Garay letters as shown below.rsr§3
,,,,,,,,,,,,,,,,,,
Observation: Need more information about how and when these are used.
Text direction
Garay text is written horizontally and right-to-left in the main but, as in most right-to-left scripts, numbers and embedded text in other scripts are written left-to-right (producing 'bidirectional' text).
Garay behaves like the following Arabic text, where words are read right-to-left, starting from the right of this line, but numbers and Latin text (highlighted) are read left-to-right.
The Unicode Bidirectional Algorithm automatically takes care of the ordering for all the text in fig_bidi, as long as the 'base direction' is set to RTL. In HTML this can be set using the dir attribute, or in plain text using formatting controls.
If the base direction is not set appropriately, the directional runs will be ordered incorrectly , making it very difficult to get the meaning.
The exact same sequence of characters (in Arabic) with the base direction set to RTL (top), and with no base direction set on this LTR page (bottom). Certain items are highlighted to help track their position.
For authoring HTML pages, one of the most important things to remember is to use <html dir="rtl" … > at the top of the page. Also, use markup to manage direction, and do not use CSS styling.
Managing text direction
Unicode provides a set of formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction of a range of characters. RLE/LRE comes at the start, and PDF at the end of a range of characters for which the base direction is to be set.
In Unicode 6.1, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2069 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
This section brings together information about the following topics:
font/writing styles;
cursive text;
context-based shaping;
context-based positioning;
letterform slopes, weights, & italics;
case & other character transforms.
Handwritten Garay typically features a swash at the end of a word which bends below the last letter and may extend the whole length of that word. It is purely ornamental and has no semantic significance.
An example of a handwritten page that shows the word-final swash running below the whole length of the word.Assane Faye primer§https://catalogingafricana.files.wordpress.com/2016/03/fayems1.pdf
Diacritic placement tends to vary, based on the shape of the base consonant to which it is attached. See fig_gpos for some examples.
Examples of varying heights of Garay diacritics.
Transforming characters
The consonant letters used for Garay are bicameral, and applications may need to provide transforms to allow the user to switch between cases. Capital letters are used at the beginning of sentences or titles, and for proper nouns.
However, with the exception of the vowel carrier, 10D50 and 10D70, characters used to write vowel sounds are not cased.
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
In normal Wolof text, grapheme clusters correspond to individual characters. Where combining marks appear, the combination of base and combining mark still fits within the definition of a grapheme cluster.
Grapheme clusters
Base (Mark?)
Each letter is a grapheme cluster, as is each combination of a base letter with combining marks.
Click on the text version of this word to see more detail about the composition.
Punctuation & inline features
Phrase & section boundaries
Basic phrase and section boundaries in Wolof use a mixture of ASCII and Arabic punctuation.
phrase
،
؛
:
sentence
.
؟
?
!
Apparently, both question marks are used.rsr§7
Bracketed text
Wolof commonly uses ASCII parentheses to insert parenthetical information into text, but the glyph shape automatically changes to match the context (see mirrored_characters).
start
end
standard
(
)
Mirrored characters
The words 'left' and 'right' in the Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use >U+003E GREATER-THAN SIGN, but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some of the more common ones.
(,),<,>,[,],{,},«,»,‹,›
Quotations & citations
Wolof texts may use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
”
“
nested
’
‘
Unlike the bracketing quotation marks, these characters are not mirrored during display. This means that LEFT means use on the left, and RIGHT means use on the right.
Abbreviation, ellipsis & repetition
tbd
Ellipsis
Garay uses … to indicate ellipsis.
Repetition
Garay uses 10D6F to double the word it follows.
eg.
Line & paragraph layout
Line breaking & hyphenation
Lines are generally broken between words.e§5
In-word line-breaks
Garay uses 10D6E at the end of a line to indicate that a word was split across two lines.rsr§7
Breaking between Latin words
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines from top to bottom.
latin-line-breaks shows how two Latin words are apparently reordered in the flow of text to accommodate this rule. This is an Arabic text, but the same principles apply for Garay. Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
The lower of these two images shows the result of decreasing the line width, so that text wraps between a sequence of Latin words.
Text alignment & justification
The principal opportunities for text justification occur at inter-word spaces, but it is not clear whether justification is common for Garay text.
Baselines, line height, etc.
tbd
Garay text uses the 'alphabetic' baseline.
Counters, lists, etc.
Garay text uses ASCII digits as counters.
Page & book layout
General page layout & progression
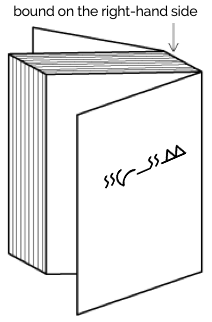
Garay books, magazines, etc., are bound on the right-hand side, and pages progress from right to left.
Binding configuration for Garay books, magazines, etc.
Columns are vertical but run right-to-left across the page.