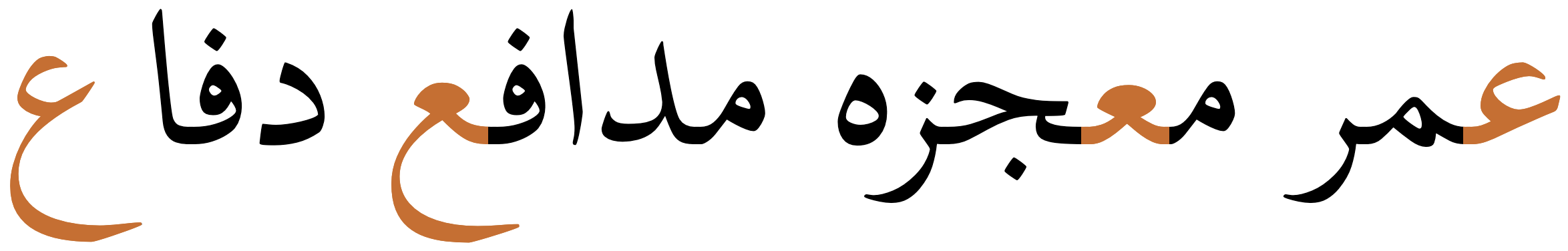Basic features
The Arabic script is an abjad, ie. short vowels are not normally written. This approach is helped in Arabic by the strong emphasis on consonant patterns in Semitic languages, but the Pashto language doesn't have those patterns.
The Pashto orthography is standardised slightly differently by Afghan and Peshawar authorities, with some differences in code point use.
❯ basicV
VowelsThe Pashto Arabic orthography is derived from the Arabic/Persian abjads, where in normal use the script represents long vowel sounds using matres lectionis. However, the script has been adapted in this orthography in order to cope with the many more vowels sounds in Pashto; there are many unique letters, and the use of letters for vowels is a distinguisher of vowel quality, rather than length.
Post-consonant vowels are typically not written. However, Pashto has two ways of disambiguating words. In ‘plene’ spellingd§751 the location of 7 plain vowel sounds can be indicated using 6 letters, however 2 of those only occur in word-final position, and the remainder also function as consonants, so there is still a good deal of ambiguity when reading unvowelled text. Alternatively, vowels can be represented using 5 combining marks. This includes a dedicated diacritic to represent ə, 0659, which is unusual, although it is rarely used.
Unlike Arabic orthographies such as Arabic, Persian, and Urdu, post-consonant vowel sounds are written using the same code points, regardless of the position within a word.
Additional, special letters are used for word-final diphthongs, which usually have grammatical functions as well as representing sounds.
Nasalisation can be indicated using ں, but that is limited to a particular dialect.
Standalone vowel sounds in word-initial position are all preceded by or attached to ا.
Consonants This page lists 32 basic consonant letters for Pashto. An additional 8 consonants are used for loan words whose spelling hasn't been assimilated into the basic Pashto letters; they introduce no new consonant sounds..
A mandatory ligature has to be used for combinations of lam + alif.
Vowel absence Vowel absence is not normally marked in any way, although the diacritic 0652 is sometimes used in vowelled text.
Numbers Pashto uses native digits.
Layout Pashto text runs right to left in horizontal lines, but numbers and embedded Latin text are read left-to-right. Words are separated by spaces, but in Pakistan component words in compounds may be joined without a space but keep word-final letter shapes intact. There is no case distinction.
The script is cursive, and some basic letter shapes change radically, depending on what they join to. It is also very common for adjacent characters to ligate and to stretch to fill available space.
Punctuation uses a mixture of ASCII and Arabic code points.
Notable features
- a number of Pashto-only characters, including ځ څ ډ ړ ږ ښ ڼ ۍ ټ
- can be spelled in ‘plene’ or short form
- different dialects use a few different characters
- a number of word-final only vowels are written, some depending on grammar
Joining forms
Because the Arabic script is 'cursive' (ie. joined-up) writing, letters tend to have different shapes depending on whether they join with adjacent letters or not (see cursive). In addition, vowels can be represented using different characters, depending on where in a word they appear.
In scripts such as Arabic, several characters have no left-joining form. In what follows we'll use the characters ي and د to illustrate shapes. The former can join on both sides, but the latter can only join on the right.
Left-joining glyphs are commonly called initial; dual-joining are called medial; and right-joining are called final. Glyphs that don't join on either side are called isolated. However, these glyph shapes can be found in various places within a single word.
Word-initial characters usually have initial glyph shapes (eg. 064A ). However, characters that only join to the right will use an isolated glyph shape (eg. 062F ). Furthermore, words beginning with a vowel are always preceded by a vowel carrier, which is normally ا (eg. 0627 06CC or 0627 064E ).
Word-medial characters will typically join on both sides (eg. 064A ) but those that only join to the right will use a final glyph (eg. 062F ). However, if either of those is preceded by another character that only joins to the right, the glyph shapes rendered will be initial (eg. 064A ) and isolated (eg. 062F ), respectively.
Word-final characters will typically use a final glyph shape (eg. 064A and 062F ). However, if the previous character joins only to the right, they will use isolated glyph shapes (eg.064A and 062F ).
In all this contextual glyph shaping the basic shapes used for a character can vary significantly in a script like Arabic. This also includes some characters that only have ijam dots in certain contexts.
Ijam & tashkil
Many Arabic characters share a common base form, and are distinguished by the number and location of dots or other small diacritics, called i'jam.

An ijam is a diacritic in the Arabic script that is considered to be an integral part of a basic letter form. Unicode encodes letter+ijam combinations as atomic characters, which are never given equivalent decompositions in the standard.
Other diacritics in the Arabic script mark indicate vocalization of text or other types of phonetic guide that indicate pronunciation. These are referred to as tashkil, and a basic Arabic letter plus any of these types of marks is never encoded as an atomic, precomposed character, but must always be represented as a sequence of letter plus a separate combining mark.
For more information, see Arabic script homographs.