This page brings together basic information about the Arabic script and its use for the Sorani (Central Kurdish) language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Sorani using Unicode.
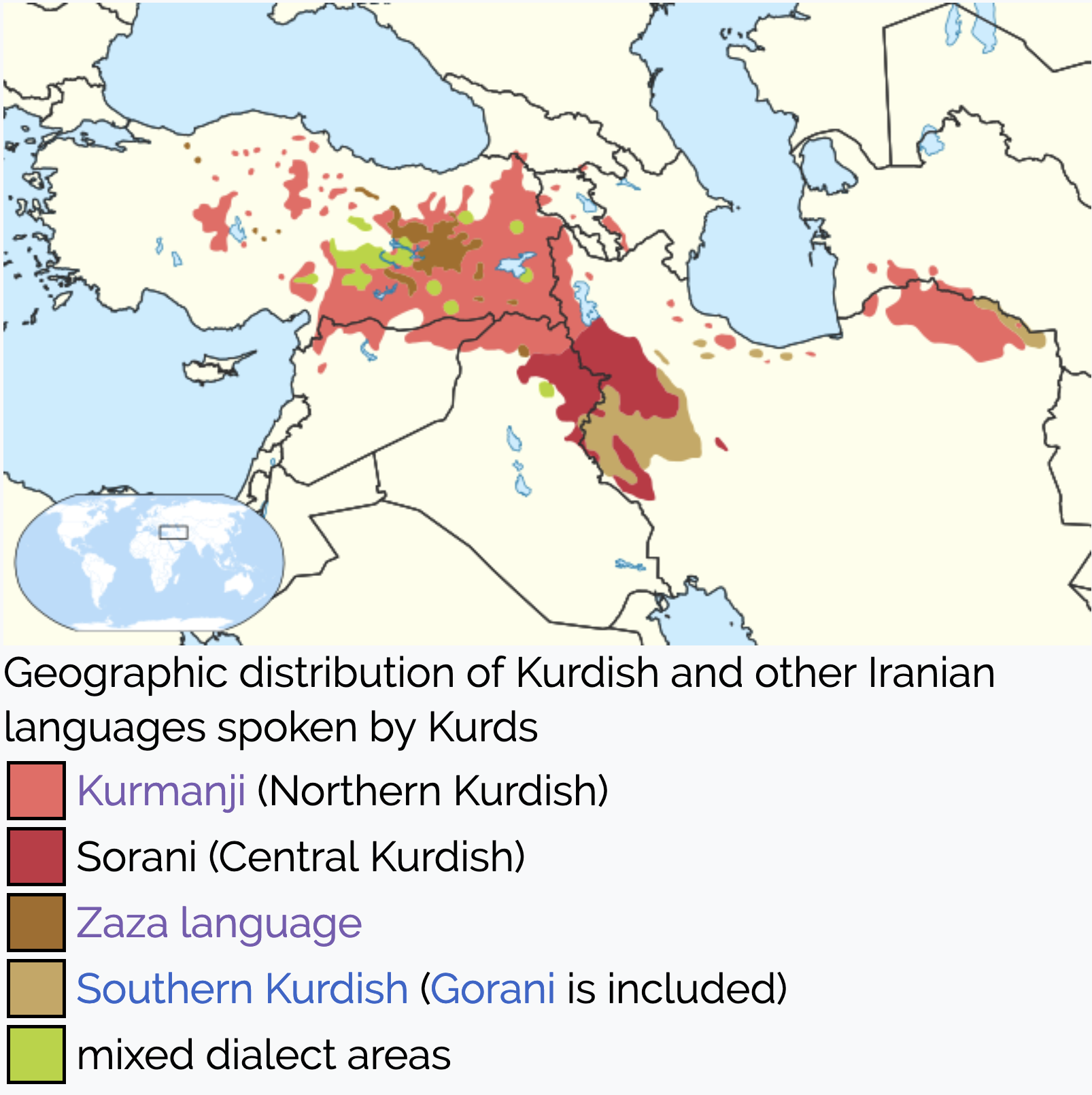
The use of the Sorani (or Central Kurdish) language ( زمانێ سۆرانی ) during the 20th century alternated between periods when it was encouraged and others when it was suppressed. The language currently has a range of uses, principally in Iraq and Iran, that include education, government, and online. According to the Ethonologue the language is used by just over 5 million people, the majority of which are in Iraq.
Although the language had been written using Arabic-script letters from some centuries beforehand, the Sorani orthography described here first began to take its current form after reforms introduced by Taufiq Wahby in the 1920s. This occurred while the British were encouraging the use of the language.
The following map of Kurdish dialects was created for Wikipedia. The Wikipedia article on Sorani contains a useful additional details about the use of Sorani since the 1700s.
Map of Kurdish language use.
Unicode 17 has 7 dedicated blocks for the Arabic script, two of which are mostly for compatibility characters, which should not be used for normal Arabic script text. The other 5 blocks comprise 464 characters.
The Sorani Arabic orthography is an alphabet, ie. all vowels are written explicitly, alongside consonants; there is no inherent vowel in a consonant (abugidas), certain vowels are not systematically dropped (abjads), and consonant and vowel are not combined in the same character (syllabaries). It is derived from the Arabic/Persian abjads, where in normal use the script represents only consonant and long vowel sounds. However, the script has been adapted in this orthography to use letters for vowel sounds, making it an alphabet.
VowelsVowels are written using letters; there are no combining marks. However, it is not completely alphabetic because the sound ɪ~ə is unwritten (like medial ə in Armenian). Sorani uses 4 dedicated vowel letters and 2 consonants to write the other 7 vowel sounds (plus some contextual variants of æ). The long vowel uː is represented by a doubled WAW digraph (وو).
ConsonantsStandard Sorani represents consonant sounds using 29 consonant letters. (6 other characters have been noted for dialectal orthographies but are poorly attested.) Unusually, the basic consonant letters distinguish between r and ɾ, and between l and ɫ.
A mandatory ligature is used for combinations of lam + alif.
Vowel absence Since this is an alphabet, vowel absence in consonant clusters or after codas is marked simply by an absence of vowel letters. There is no special shaping or mark to indicate a consonant cluster.
Layout Sorani text runs right-to-left in horizontal lines, but numbers and embedded Latin text are read left-to-right. Words are separated by spaces. Letters have no case distinction.
The writing is cursive (ie. letters are joined), and some basic letter shapes change significantly, depending on what they join to. The baseline is the same as for Latin text.
Punctuation is a mixture of ASCII and Arabic code points.
Notable features
normally, Sorani text has no combining marks; vowels are written using letters
the vowel ə~ɪ is not written, making this not quite a full alphabet
standalone vowels always follow ئ
no sukun-like diacritic is used to indicate consonant clusters
Joining forms
Because the Arabic script is 'cursive' (ie. joined-up) writing, letters tend to have different shapes depending on whether they join with adjacent letters or not (see cursive). In addition, vowels can be represented using different characters, depending on where in a word they appear.
In scripts such as Arabic, several characters have no left-joining form. In what follows we'll use the characters ي and د to illustrate shapes. The former can join on both sides, but the latter can only join on the right.
Left-joining glyphs are commonly called initial; dual-joining are called medial; and right-joining are called final. Glyphs that don't join on either side are called isolated. However, these glyph shapes can be found in various places within a single word.
Word-initial characters usually have initial glyph shapes (eg. 064A ). However, characters that only join to the right will use an isolated glyph shape (eg. 062F ).
Furthermore, words beginning with a vowel are always preceded by a vowel carrier, which is normally ا
(eg. 0627 06CC or 0627 064E ).
Word-medial characters will typically join on both sides
(eg. 064A ) but those that only join to the right will use a final glyph (eg. 062F ).
However, if either of those is preceded by another character that only joins to the right, the glyph shapes rendered will be initial (eg. 064A )
and isolated (eg. 062F ), respectively.
Word-final characters will typically use a final glyph shape (eg. 064A and 062F ).
However, if the previous character joins only to the right, they will use isolated glyph shapes (eg.064A and 062F ).
In all this contextual glyph shaping the basic shapes used for a character can vary significantly in a script like Arabic. This also includes some characters that only have ijam dots in certain contexts.
The following represents the general repertoire of the Sorani language.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones.
Vowel sounds
Plain vowels
Consonant sounds
labial
alveolar
post-
alveolar
palatal
velar
uvular
pharyngeal
glottal
stop
pb
td
kɡ
q
ʔ
affricate
t͡ʃd͡ʒ
fricative
fv
sz
ʃʒ
xɣ
χ
ħʕ
h
nasal
m
n
ŋ
approximant
w
lɫ
j
trill/flap
rɾ
The velar consonants tend to be palatalised before i and e.ua
The sounds ħ and ʕ are the result of Arabic influence on pronunciation, and are most often heard outside of Iran. They are not necessarily used for loan words. The word حەوت is commonly pronounced using ħ.
Tone
Sorani is not a tonal language.
Structure
tbd
Vowels
ی,ی,ئی
وو,وو,ئوو
ⓘ
و,و,ئو
ێ,ێ,ئێ
ۆ,ۆ,ئۆ
ە,ە,ئە
ە,ە,ئە
ە,ە,ئە
ا,ا,ئا
ⓘ represents the unwritten vowel. Each table cell shows word-initial, word-medial, and word-final forms from right to left. The glyphs shown are illustrative; alternative shapes may occur (see joining_forms).
Post-consonant vowels
All written Sorani vowels use letters. Those letters do not decompose, so there are no combining marks involved.
Sorani uses 4 dedicated vowel letters and 2 consonants to write the 7 post-consonant vowel sounds (plus some contextual variants of æ). The long vowel uː is represented by a doubled WAW digraph (وو).
Plain vowels
This panel shows the characters used for monophthongs in Sorani. The shape of the letter changes according to position (see basicV above), but the vowel is always written with the same character(s).
ی,وو,و,ێ,ۆ,ە,ا
06D5 is shown here to represent the short æ vowel. In some resources 0647 200C is used, instead. See unresolved_encoding for more information.
06D5 is generally pronounced æ, but before the codas -w and -j it becomes ə. Before a j- onset it becomes ɛ.
ی and و are consonants that are also used to indicate vowels (iː and ʊ, respectively).
Unwritten vowel
The vowel sound ə~ɪ is not written in Sorani text. This is similar to the way Armenian doesn't write the sound ə, and means that Sorani isn't a perfect alphabet.
eg.
سفر
س,ف,ر
مرۆڤ
وشک
بزنمژ
Non-standard letter
The Unicode Standard mentions ۊ as representing the sound yː in a dialectal or other poorly attested alternative form of the Soraní alphabetu§#G43484.
Diphthongs/semi-vowels
The main vowel in a syllable can be followed by -j or -w. These semivowels are written using the consonant letters ی and و, respectively.
eg.
چووی
بنەوشە
As already mentioned, ە, which normally represents the sound æ, is pronounced ə before these glides.
eg.
قەیچی
شەو
These glides can also appear before a main vowel, but for that see onsets.
Vowel length
Vowel length is indicated by the choice of vowel letter.
Standalone vowels
Standalone vowels are preceded by ئ. The following are examples:
ئی,ئێ,ئۆ,ئە,ئا
eg.
ئافرەت
ئەمبار
ئێرانی
بێئێش
Vowel sounds to characters
This section maps Sorani vowel sounds to common graphemes in the Arabic orthography.
The right-hand side shows the various joining forms for each letter.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc.
Plain vowels
iː
06CC06CC06CC06CCی
yː
06CA06CAۊA dialectal or poorly attested alternative form.
ʊ
06480648و
ɪ
Not writtenUnwritten, eg. سفر sɪfɪrzero
uː
06480648وو
eː
06CE06CE06CE06CEێ
oː
06C606C6ۆ
ə
06D506D5ەesp. before a -w or -j coda.
ɛ
06D506D5ەesp. before a j- onset.
æ
06D506D5ە
ɑː
06270627ا
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Sorani doesn't use any special features to deal with consonant clusters, or syllable-final consonants. There are no conjuncts, and 0652 is not used to indicate vowel absence.
eg.
ئاشتی
ئ,ا,ش,ت,ی
زانستگە
ز,ا,ن,س,ت,گ,ە
A little care needs to be exercised, however, when reading, since Sorani has an unwritten vowel ɪ, which may occur, unmarked, between consonants. For example, compare:
eg.
ئەمڕۆ
ئە,م,ڕ,ۆ
مرۆڤ
م,ر,ۆ,ڤ
Consonants
پ,ب,ت,چ,د,ج,ک,گ,ق,ئ
ف,ڤ,س,ز,ش,ژ,خ,غ,ح,ع,ه,ھ
م,ن,ن
و,ر,ڕ,ل,ڵ,ی
Basic consonants
Basic consonant sounds in Sorani are written using single letters, as follows.
Click on each letter for more details and for examples of usage.
The list above includes 2 letters for the sound h because some texts use one, whereas some use the other. For more information, see unresolved_encoding.
Non-standard letters
The letters in the list below represent dialectal or other poorly attested alternative forms of the Soraní alphabet extensionsu§#G43484.
نٚ,ڒ,ڔ,ڶ,ڷ,ك
See also encoding for alternative code points used in some texts.
Onsets
Sorani syllables may begin with a consonant followed by a j or w glide. These are written using the ordinary consonants ی and و.
eg.
پیاو
ژوان
It is not common, but some words also start with a consonant cluster. No diacritics or shaping are employed to indicate that this is a consonant cluster.
eg.
سپیدار
ژمارە
However, care needs to be taken when reading Sorani text, since it is not obvious when an onset begins with a consonant cluster vs. a consonant followed by an unwritten vowel. For example, consider the following, which is pronounced kəre̞ːwa, rather than kre̞ːwa.
eg.
کڕێوە
Finals
It is common for Sorani codas to consist of more than one consonant (usually two). Again, no diacritics or shaping are employed to indicate the consonant cluster.
eg.
پڵنگ
پرد
ئاشت
As for onsets, it is generally not possible to tell from the letter sequence whether you are looking at a cluster of consonants or a pair of consonants with an intervening vowel that is not written. For example, compare the following:
cf.
جەژن
بەژن
Consonant length
Sorani appears to have lengthened consonant sounds, which are written by simply doubling the relative consonant letter.
eg.
شەممە
ڕۆژژمێر
ژینناسی
Consonant sounds to characters
This section maps Sorani consonant sounds to common graphemes in the Arabic orthography.
The right-hand side shows the various joining forms for each letter.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc.
p
067E067E067E067Eپ
b
0628062806280628ب
t
062A062A062A062Aت
t͡ʃ
0686068606860686چ
d
062F062Fد
d͡ʒ
062C062C062C062Cج
k
06A906A906A906A9ک
ɡ
06AF06AF06AF06AFگ
q
0642064206420642ق
ʔ
word-initial vowel carrierئ
f
0641064106410641ف
v
06A406A406A406A4ڤ
s
0633063306330633س
z
0632063206320632ز
ʃ
0634063406340634ش
ʒ
06980698ژ
x
062E062E062E062Eخ
ɣ
063A063A063A063Aغ
ħ
062D062D062D062Dح
ʕ
0639063906390639ع
h
Only one of these 2 characters is used for this sound, but there are no clear rules at present as to which, so either can be found in online texts. The KRG expects the second to be used.kk
0647064706470647ه
06BE06BE06BE06BEھ
m
0645064506450645م
n
0646064606460646ن
ŋ
نbefore a velar consonant.
w
06480648و
ɾ
06310631ر
r
06950695ڕ
l
0644064406440644ل
ɫ
06B506B506B506B5ڵ
j
06CC06CC06CC06CCی
Other features
Formatting characters
Arabic script text makes use of a relatively large set of invisible formatting characters, especially in plain text, many of which are used to manage text direction. Descriptions of these characters can be found in the following sections:
The code points in the Unicode blocks Arabic Presentation Forms-A and Arabic Presentation Forms-B provide positional forms of Arabic letters and ligatures. They should not be used for ordinary text. Those code points are provided for compatibility with legacy code pages, and have (compatibility) character decomposition mappings. Normally, Arabic text should be written with code points from the main Arabic block and its extensions; positional forms are dealt with by the font and rendering algorithms.
This section offers advice about characters or character sequences to avoid, and what to use instead. It takes into account the relevance of Unicode Normalisation Form D (NFD) and Unicode Normalisation Form C (NFC)..
Although usage is recommended here, content authors may well be unaware of such recommendations. Therefore, applications should look out for the non-recommended approach and treat it the same as the recommended approach wherever possible.
Canonically equivalent encodings
One letter only can be represented as an atomic character (the norm), or as a sequence of base letter plus combining mark. The parts are separated in Unicode Normalisation Form D (NFD), and recomposed in Unicode Normalisation Form C (NFC), so both approaches should be treated as canonically equivalent.
Atomic (recommended)
Decomposed ( NOT recommended )
ێ
064A 0654
Note that the base character in the decomposed sequence is 064A, and not 06CC, which is used elsewhere for yeh in Kurmanji. 064A is only used for this specific decomposed sequence; it is inappropriate to use it elsewhere in Kurmanji text.
Unresolved encodings
A couple of Sorani letters are encoded in different ways in different texts, and in fact can be mixed within the same text. At the moment there doesn't appear to be a clear ruling on which is expected. This section lists the alternatives.
Alternative 1
Alternative 2
Notes
06BE
0647
Wikipedia and Wiktionary represent the sound h using only HEH DOACHASHMEE, whereas gov.krd uses only ARABIC HEH. Other online resources examined are not completely one or the other. Note that Uighur uses HEH DOACHASHMEE to represent h.
The Kurdish Regional Government pages standardising keyboard layout expect the use of 0647kk.
06D5
0647 200C
The majority usage seems to favour AE, although again some resources mix both to some degree (although they tend to mostly use AE). This makes sense, since the use of HEH plus ZWNJ has the appearance of a hack intended to prevent HEH joining to the left, whereas AE will do this naturally, without any formatting code point. Use of AE also gets around practical difficulties that arise because the ZWNJ character is invisible and is not readily accessible from many keyboards – difficulties that are amplified by the fact that this vowel letter is one of the most commonly used letters in the Sorani alphabet. Note that Uighur also uses AE to represent a vowel, and a different character for the sound h.
The Kurdish Regional Government pages standardising keyboard layout distinguish between bothkk.
Confusables & spelling errors
This table lists characters that are often mistakenly used because they look the same as or similar to the code points used for Kurmanji, or perhaps because the correct character is not available on the user's keyboard.
Incorrect
Correct
Notes
064A
06CC
The Arabic YEH doesn't drop the dots below in isolate and final positions.
0643
06A9
Common fonts tend not to show the difference between these two characters, but the ability to search and compare text is impaired unless the application is aware of and takes counter-measures against this substitution.
False friends
The following atomic characters look as if they could be composed of parts, but in fact there is no equivalence during normalisation, and so the atomic characters only should be used.
Atomic
Sequence ( DO NOT use! )
ڵ
0644 065A
ێ
06CC 065A
ۆ
0648 065A
Codepoint sequences
Combining marks always follow the based character, however for Sorani, which doesn't normally use combining marks, this is only relevant for ێ when it occurs in decomposed text.
Numbers
Digits
Sorani uses the set of native digits from the extended Arabic range, but most modern texts appear to use ASCII digits much of the time.
۱,۲,۳,۴,۵,۶,۷,۸,۹,۰
Text direction
Arabic script text is written horizontally and right-to-left in the main but, as in most right-to-left scripts, numbers and embedded text in other scripts are written left-to-right (producing 'bidirectional' text).
Arabic words are read right-to-left, starting from the right of this line, but numbers and Latin text (highlighted) are read left-to-right.
The Unicode Bidirectional Algorithm automatically takes care of the ordering for all the text in fig_bidi, as long as the 'base direction' is set to RTL. In HTML this can be set using the dir attribute, or in plain text using formatting controls.
If the base direction is not set appropriately, the directional runs will be ordered incorrectly as shown in fig_bidi_no_base_direction, making it very difficult to get the meaning.
The exact same sequence of characters with the base direction set to RTL (top), and with no base direction set on this LTR page (bottom). Certain items are highlighted to help track their position.
For authoring HTML pages, one of the most important things to remember is to use <html dir="rtl" … > at the top of the page. Also, use markup to manage direction, and do not use CSS styling.
Managing text direction
Unicode provides a set of 10 formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction of a range of characters. RLE/LRE comes at the start, and PDF at the end of a range of characters for which the base direction is to be set.
In Unicode 6.1, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2066 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
061C (ALM) is used to produce correct sequencing of numeric data.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
Arabic script is always cursive, ie. letters in a word are joined up. Fonts need to produce the appropriate joining form for a letter, according to its visual context, but the code point used doesn't change. This results in four different shapes for most letters (including an isolated shape). Ligated forms also join with characters alongside them.
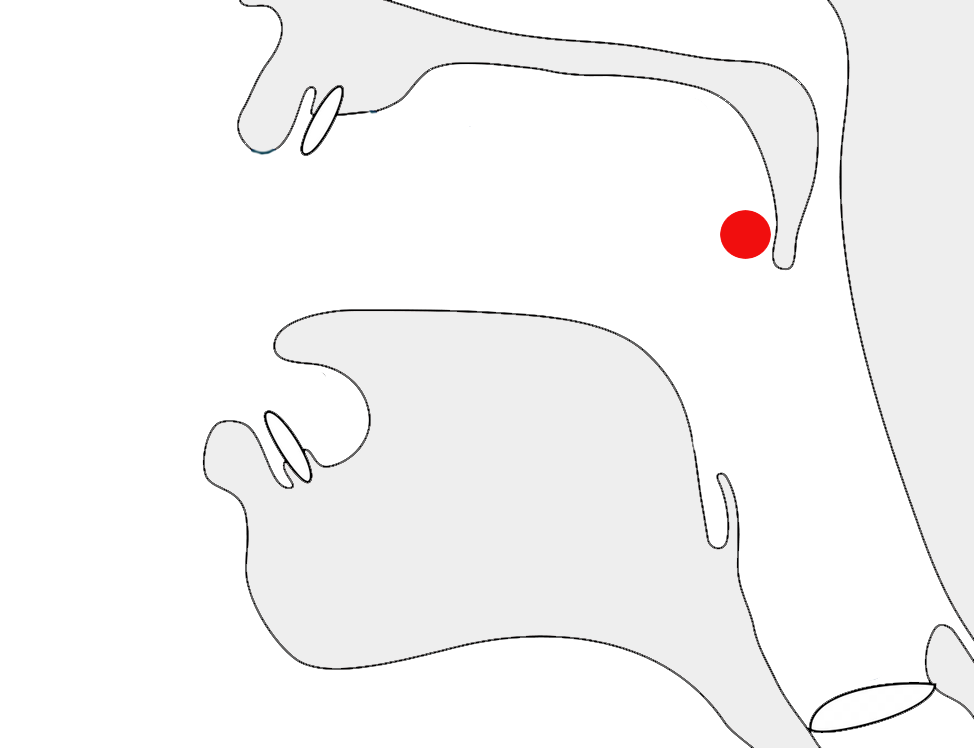
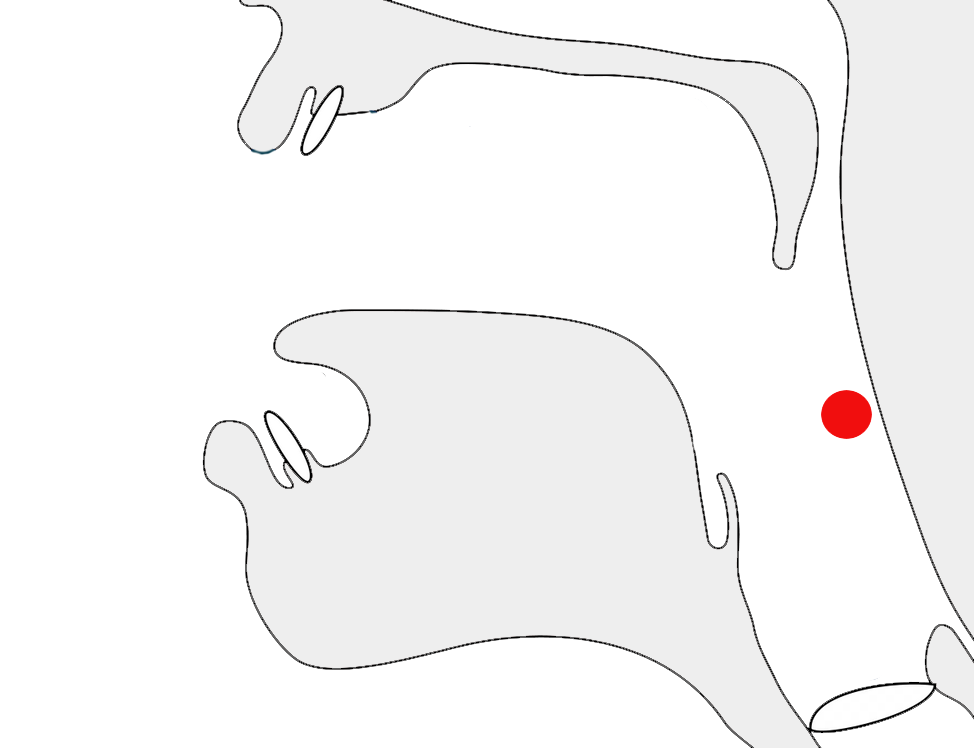
The highlights in the example below show the same letter, ع, with three different joining forms.
The letter ع (ain) in 3 different joining contexts.
Most Arabic script letters join on both sides. A few only join on the right-hand side: this involves 5 underlying shapes for the Sorani orthography.
Cursive joining forms
Most dual-joining characters add or become a swash when they don't join to the left. A number of characters, however, undergo additional shape changes across the joining forms. fig_joining_forms and fig_right_joining_forms show the basic shapes in the Sorani orthography and what their joining forms look like. Significant variations are highlighted.
isolated
right-joined
dual-join
left-joined
Sorani letters
ب
ـب
ـبـ
بـ
ب,ت,پ
ن
ـن
ـنـ
نـ
ن
ق
ـق
ـقـ
قـ
ق
ف
ـف
ـفـ
فـ
ف,ڤ
س
ـس
ـسـ
سـ
س,ش
ک
ـک
ـکـ
کـ
ک,گ
ل
ـل
ـلـ
لـ
ل,ڵ,ڶ,ڷ
ه
ـه
ـهـ
هـ
ه,ھ
م
ـم
ـمـ
مـ
م
ع
ـع
ـعـ
عـ
ع,غ
ح
ـح
ـحـ
حـ
ج,ح,خ,چ
ي
ـي
ـيـ
يـ
ی,ێ,ئ
Joining forms for shapes that join on both sides..
isolated
right-joined
Sorani letters
ا
ـا
ا
ر
ـر
ڒ,ڔ,ڕ,ژ,ر,ز
د
ـد
د
و
ـو
و,ۆ,ۊ
ە
ـە
ە
Joining forms for shapes that join on the right only.
Managing glyph shaping
200D (ZWJ) and 200C (ZWNJ) are used to control the joining behaviour of cursive glyphs. They are particularly useful in educational contexts, but also have real world applications.
ZWJ permits a letter to form a cursive connection without a visible neighbour. For example, the marker for hijri dates is an initial form of heh, even though it doesn't join to the left, ie. ه. For this, use ZWJ immediately after the heh, eg. الاثنين 10 رجب 1415 ه..
ZWNJ prevents two adjacent letters forming a cursive connection with each other when rendered. For example, it is used in Persian for plural suffixes, some proper names, and Ottoman Turkish vowels. Ignoring or removing the ZWNJ will result in text with a different meaning or meaningless text, eg, تنها is the plural of body, whereas تنها is the adjective alone.2 The only difference is the presence or absence of ZWNJ after noon.
People who don't use 06D5 to represent the sound æ, but use 0647 instead, need to follow the latter with a ZWNJ character to prevent it joining with any following letter. For more information see unresolved_encoding.
Context-based shaping & positioning
See just above for shaping related to cursive joining.
See also the section on glyph shaping in the Arabic orthography notes.
Ligatures
The combination لا is always written as a ligature. The underlying code points are, however, preserved. The shape varies slightly, depending on whether the ligature joins to the right or not. Compare:
cf.
لادێ
سڵاو
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
Since there are no combining marks or decompositions in normal Kurmanji text, grapheme clusters correspond to individual characters. Where combining marks appear in decomposed text, the combination of base and combining mark still fits within the definition of a grapheme cluster.
Punctuation & inline features
Phrase & section boundaries
tbd
Sorani uses a mixture of ASCII and Arabic punctuation.
phrase
،
؛
:
sentence
.
؟
!
Bracketed text
Sorani commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Mirrored characters
The words 'left' and 'right' in the Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use >U+003E GREATER-THAN SIGN, but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some of the more common ones.
The following type of quotation mark can be found in Sorani texts. When quoted text appears within quoted text different characters are used, though usually of the same type. (Of course, depending on ease of input, quotations may also be surrounded by ASCII double and single quote marks.)
start
end
primary
”
“
nested
’
‘
Unlike brackets, these quote marks are notmirrored during display. As a result, LEFT means use on the left, and RIGHT means use on the right.
Line & paragraph layout
Line breaking & hyphenation
tbd
The primary line break opportunity is the space between words.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for characters affected by these rules. Context may affect the behaviour of some of these and other characters.
« “ ‘ ( should not be the last character on a line
» ” ’ ) . ، ؛ ؟ ! should not begin a new line
Breaking between Latin words
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines upwards.
latin-line-breaks shows how two Latin words are apparently reordered in the flow of text to accommodate this rule. Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
In this Arabic language text, the lower of these two images shows the result of decreasing the line width, so that text wraps between a sequence of Latin words.









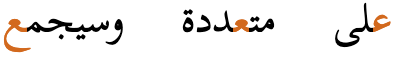
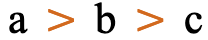



{kind=link}