Changes in version 7.0.0
This version updates the app per the changes during beta phase of the specification, so that it now reflects the finalised Unicode 7.0.0.
The initial in-app help information displayed for new users was significantly updated, and the help tab now links directly to the help page.
A more significant improvement was the addition of links to character descriptions (on the right) where such details exist. This finally reintegrates the information that was previously pulled in from a database. Links are only provided where additional data actually exists.
Rather than pull the data into the page, the link opens a new window containing the appropriate information. This has advantages for comparing data, but it was also the best solution I could find without using PHP (which is no longer available on the server I use). It also makes it easier to edit the character notes, so the amount of such detail should grow faster. In fact, some additional pages of notes were added along with this upgrade.
A pop-up window containing resource information used to appear when you used the query to show a block. This no longer happens.
Changes in version 7beta
This version adds the 2,834 new characters encoded in the Unicode 7.0.0 beta, including characters for 23 new scripts. It also simplified the user interface, and eliminated most of the bugs introduced in the quick port to JavaScript that was the previous version.
Some features that were available in version 6.1.0a are still not available, but they are minor.
Significant changes to the UI include the removal of the 'popout' box, and the merging of the search input box with that of the other features listed under Find.
In addition, the buttons that used to appear when you select a Unicode block have changed. Now the block name appears near the top right of the page with a  icon. Clicking on the icon takes you to a page listing resources for that block, rather than listing the resources in the lower right part of UniView's interface.
icon. Clicking on the icon takes you to a page listing resources for that block, rather than listing the resources in the lower right part of UniView's interface.
UniView no longer uses a database to display additional notes about characters. Instead, the information is being added to HTML files. When one of these files contains information for a particular block, you'll see a link to it from the detailed information for a particular character. At some future point, I may pull the information for that character into UniView, as before, but for the time being clicking on the Character notes link opens the page in a separate window. Initially such a link is only available for Tibetan, but I will add more from time to time.
Changes in version 6.1.0b
This was an attempt to continue to provide most of the functionality after my site was hacked and the W3C disallowed PHP on the server I use. The main features were converted to work using JavaScript. This version was buggy and incomplete.
The location of UniView was changed from rishida.net/scripts/uniview/ to rishida.net/uniview/.
Changes in version 6.1.0a
This version adds a couple of buttons that appear when you ask UniView to display a block.
Clicking on Show annotated list generates a list of all characters in the block, with annotations.
Clicking on Show script links displays a list of links to key sources of information about the script of the block, links to relevant articles and apps on the rishida.net site, and related fonts and input methods. This provides a very quick way of finding this information. One particularly useful link (to a Scriptsource.org page) allows you to find the proposals for all additions to Unicode related to the relevant script. These proposals are a mine of useful information about the individual characters in a block.
In addition, there were some changes to the user interface, including the following:
The order of information in the lower right panel (detailed character information) was slightly changed, and two alterative representations of the character were added: an HTML escape, and a URI escape.
-
The search box at the top left was constrained to appear closer to the other controls when the window is stretched wide.
Various bugs were also fixed.
Changes in version 6.1.0
The major change in this update is the update of the data to support Unicode version 6.1.0.
Another significant change enables you to display information in a separate window, rather than overwriting the information currently displayed. This can be done by typing/pasting/dragging a set of characters or character code values into the Popout area and selecting the  icon alongside the Characters or Edit buffer input fields (depending on what you put in the popout window).
icon alongside the Characters or Edit buffer input fields (depending on what you put in the popout window).
Two new icons were added to the Edit buffer area:
 Clicking on this will display the characters in the area in the lower right part of the page with all relevant characters converted to uppercase, lowercase and titlecase. Characters that had no case conversion information are also listed.
Clicking on this will display the characters in the area in the lower right part of the page with all relevant characters converted to uppercase, lowercase and titlecase. Characters that had no case conversion information are also listed.
 Clicking on this produces the same kind of output as clicking on the icon just above, but shows the mappings for those characters that have been changed, eg. e→E.
Clicking on this produces the same kind of output as clicking on the icon just above, but shows the mappings for those characters that have been changed, eg. e→E.
Where character information displayed in the lower right panel has a case or decomposition mapping, UniView now displays the characters involved, rather than just giving the hex value(s), eg. Uppercase mapping: 0043 C. You will need a font on your system to see the characters displayed in this way, but whether or not you have a font, this provides a quick and easy way to copy the case-changed character (rather than having to copy the hex value and convert it first).
There is also a new line, slightly further down, when UniView is in graphic mode. This line starts with 'As text:', and shows the character using whatever default font you have on your system. Of course, if you don't have a font that includes that character you won't see it. This has been added to make it easier to copy and paste a character into text.
Fix some small bugs, such as problems with search when U+29DC INCOMPLETE INFINITY is returned.
Changes in version 6.0.0a
The majority of changes in this update relate to the user interface. They include the following:
- Many controls have been grouped under three tabs: Look up, Filter, and Options. Various previously dispersed controls were gathered together under the Filter and Options tabs. Many of the controls have been slightly renamed.
- The Search control has been moved to the top right of the window, where it is always visible.
- The old Text Area is now a Edit buffer control that has a 2-dimensional input box. In browser such as Safari, Chrome and Firefox 4, this box can be stretched by the user to whatever size is preferred.
- The icon that provides a toggle switch between revealing detailed information for a character in a list or table, or copying that character to the Edit buffer box has been redesigned. It stands alone and indicates the location of the current outcome using arrows.
It looks like this:  or this
or this  .
.
- Title text has been provided for all controls, describing briefly what that control does. You can see this information by hovering over the control with the mouse.
Many of these changes were introduced to make it a little easier for newcomers to get to grips with UniView.
There were also some feature changes:
- The 'Codepoints' control was converted to accept text as well as code points and renamed 'Characters'. By default the control expect hex code point values, but this can be switched using the radio buttons. For text, you would usually use the 'Edit buffer' control, but if you want to check out some characters without disturbing the contents of that control, you can now do so by setting the 'Character' radio button on the 'Characters' control.
- The control to look up characters in the Unihan database
 was fixed, but also extended to handle multiple characters at a time, opening a separate window for each character. (UniView warns you if you try to open more than 5 windows.)
was fixed, but also extended to handle multiple characters at a time, opening a separate window for each character. (UniView warns you if you try to open more than 5 windows.)
- The control to send characters to the Unicode Conversion tool
 was fixed and now puts the character content of the field in the green box of the Converter Tool. If you need to convert hex or decimal code point values, do that in the converter.
was fixed and now puts the character content of the field in the green box of the Converter Tool. If you need to convert hex or decimal code point values, do that in the converter.
- The Show Age feature now works with lists, not just tables.
Changes in version 6.0.0
The major change in this update is the update of the data to support Unicode version 6.0.0..
Three new icons were added to the text area:
 Clicking on this will send all characters in the text area box to the String Analyser tool. This tool provides detailed information about all the characters on a single page.
Clicking on this will send all characters in the text area box to the String Analyser tool. This tool provides detailed information about all the characters on a single page.
 When you click on this icon any hyphen separated lists in the text area box are expanded. For example, if you have A-Z in the text box, it will be replaced with ABCDEFGHIJKLMNOPQRSTUVWXYZ. You can expand multiple ranges at the same time. For example, A-Za-z0-9 will expand to include all intervening characters for the three ranges specified.
When you click on this icon any hyphen separated lists in the text area box are expanded. For example, if you have A-Z in the text box, it will be replaced with ABCDEFGHIJKLMNOPQRSTUVWXYZ. You can expand multiple ranges at the same time. For example, A-Za-z0-9 will expand to include all intervening characters for the three ranges specified.
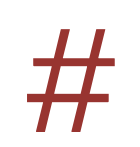 When you click on this icon, it simply reports the number of characters in the text area box.
When you click on this icon, it simply reports the number of characters in the text area box.
There were also some changes to the source code. For example, the location of the graphics was changed.
Changes in version 5.2.0b
The major change in this update is the addition of a new UniView lite interface for the tool that makes it easier to use UniView in restricted screen sizes, such as on mobile devices. The lite interface offers a subset of the functionality provided in the full version, rearranges the user interface and sets up some different defaults (eg. list view is the default, rather than the matrix view). However, the underlying code is the same - only the initial markup and the CSS are different.
Another significant change is that when you click on a character in a list or matrix that character is either added to the text area or detailed information for that character is displayed, but not now both at the same time. You switch between the two possibilities by clicking on the  icon. When the background is white (default) details are shown for the character. When the background is orange
icon. When the background is white (default) details are shown for the character. When the background is orange  the character will be added to the text area (like a character map or picker).
the character will be added to the text area (like a character map or picker).
Information from my character database is now shown by default when you are shown detailed information for a character. The switch to disable this has been moved to the Options panel.
Text highlighted in red in information from the character database contains examples. In case you don't have a font for viewing such examples, or in case you just want to better understand the component characters, you can now click on these and the component characters will be listed in a new window (using the String Analyser tool).
Access to Settings panel has been moved slightly downwards and renamed Options in the full version.
The default order for items in lists is now <character><codepoint><name>, rather than the previous <codepoint><character><name>. This can still be changed in the Options panel, or by setting query parameters.
I changed the Next and Previous functions in the character detail pane so that it moves one code point at a time through the Unicode encoding space. The controls are now buttons rather than images.
Changes in version 5.2.0a
The major change in this update is the addition of a function, Show age, to show the version of Unicode where a character was added. The same information is also listed in the details given for a character in the lower right panel.
The trigger for context-sensitive help was reduced to the first character of a command name, rather than the whole command name. This improves behaviour for commands under More actions by allowing you to click on the command name rather than just the icon alongside to activate the command.
The highlighting mechanism was changed. Rather than highlight characters using a coloured border (which is typically not very visible), highlighting now works by greying out characters that are not highlighted. This also makes it clearer when nothing is highlighted.
In the recent past, when you converted a matrix to a list in the lower left panel, greyed-out rows would be added for non-characters. These are no longer displayed. Consequently, the command to remove such rows from the list (previously under More actions) has been removed.
A lot of invisible work went into replacing style attributes in the code with class names. This produces better source code, but doesn't affect the user experience.
Some 'quick start' instructions were added to the initial display to orient people new to the tool, and this help text was updated in various areas.
Changes in version 5.2.0
The major change in this update is conformance to the final 5.2.0 version of the Unicode database.
The order of blocks listed in the top left pulldown menu was changed to resemble the order in the Unicode Charts page. Several sub-block selections were also added to the list (as in the Unicode page), and are displayed in italics.
When you display details of a character in the right panel, the heading Script group has now been used to indicate the sub-block-level headings in the block listings of the Unicode Standard. The link to the Show block now follows the heading Show block. These sub-block-level headings are also shown when you display a range as a list (as opposed to a matrix).
When you mouse over characters displayed in a matrix, the code point and name information for that character now appear just above the matrix. This makes it much easier to locate characters you are looking for..
Finally, graphics are now available for all the many Egyptian Hieroglyph characters. This was the last block for which graphics were completely unavailable.
Changes in version 5.2(beta)a
The big change in this update is that UniView starts up in graphics mode by default. This means that pages load more slowly, but (especially with the continuing growth of Unicode) also means that you are more likely to be able to see the characters you are looking for. (If you preferred font glyphs as a default, you just need to change the URI in your bookmarked link slightly, and you can continue to work that way.)
To facilitate this change, I created my own graphics for blocks which are not yet covered by decodeunicode, or which are no longer fully covered by decodeunicode. The blocks for which I provided graphics are Latin Extended-C, Latin Extended-D, Latin Extended Additional, Cyrillic Supplement, Cyrillic Extended-B, Modifier Tone Letters, Tibetan, Malayalam, Saurashtra, Ol Chiki, Myanmar, Kayah Li, Cham, Rejang, Vai, Supplemental Punctuation, and Miscellaneous Symbols and Arrows.
There are still many characters for which there are no graphics (especially the new characters in Unicode 5.2), but coverage is much better than it was. As I find more fonts, I will be able to create graphics for the remaining characters.
I also put a grey box around the characters in tables. This is particularly useful if there are no graphics or font glyphs for a block or range of characters.
I also fixed a problem that was preventing Chrome and Safari and IE from displaying the first two Latin blocks.
Changes in version 5.2(beta)
This update adds the characters and changes proposed for Unicode 5.2.
While the properties for new and modified characters are still in beta they are not officially stable, however the characters should be stable at this point. UniView therefore alerts you if you are looking at a new character. If the Unicode database information has changed for a given character you are also warned, and provided with a link that points to the previous information for that character.
These warnings will be removed from UniView when Unicode 5.2 is released.
This release also fixes a few small bugs in the HTML and JavaScript code.
Changes in version 5.1.0f
This is a very small update.
Moved the  icon (to select all text in the text area) near to the beginning of the row, since this is a frequently used icon.
icon (to select all text in the text area) near to the beginning of the row, since this is a frequently used icon.
Caused the icons to link to the latest version of the converter tool, and work properly.
Text area now has the focus when you open UniView.
Changes in version 5.1.0e
Custom ranges are no longer enlarged to fill full columns in the matrix. Full columns are still shown, but characters not in the range specified are greyed out. When displaying the range as a list, only the characters in the specified range appear.
Context-sensitive help was added. The labels for controls link to a new section in this document where the controls are explained one by one. To get the help, click on the label.
Some changes were made to help those who want to copy and paste lists of characters to other documents. There are new settings that make it possible to automatically prefix hex code point numbers in lists with U+, if you prefer, and tailor what appears in the list, and where the character is shown. (You can also set U+ to appear by default by including u=yes in the URI you use to call UniView.) These controls are accessed by clicking on Settings (used to be called Options).
A control was added to remove unassigned characters from a list. This can be useful, for example, if you want a list of all characters in a block.
Another control was added that removes the highlighted characters from a list. This and the previous control were moved into a popup that opens as you mouse over the text More actions.
The default font was set to nothing, and the Font control was moved from the settings popup to the main control area. To reset the default font, simply delete the last font name in the font control and hit return.
If an unassigned character is displayed in the right panel, it is now possible to display the group it belongs to on the left. Hex code point numbers for unassigned characters in lists are now a minimum of 4 characters long. Unassigned characters now have a grey background in all lists. DB notes are no longer reported for unassigned characters (bugfix).
A couple more minor user interface changes.
Changes in version 5.1.0d
A major feature change is the addition of buttons to the Text area to allow conversion of the text to NFC or NFD normalization forms. (You may not notice the change until you list the characters.)
The control panel was also substantially rearranged again to hopefully make it easier for newcomers to see what they can do.
The Code point conversion feature was upgraded to handle decimal code point values.
A single character in the code points area or text area is now listed in the lower left panel when you click on , rather than in the right-hand properties panel. This is to improve consistency and avoid surprises.
Added a link to the CLDR property demo from the right panel to give access to additional properties.
Improved the parsing of code points when surrounded by text in the Code point input field, so that it now works with &#x...; and \u... and \U... escapes.
Jettisoned some unneeded code to reduce download by around 40-50K bytes. Implemented the NFC/NFD feature using AJAX, to avoid putting the download size back up.
When you delete the contents of the text area or the code point area, the associated input field is given focus, so you are ready for input.
A couple more minor bug fixes.
Changes in version 5.1.0c
Removed the two Highlight selection boxes. These used to highlight characters in the lower left panel with a specific property value. The Show selection box on the left (used to be Show list) now does that job if you set the Local check box alongside it. (Local is the default for this feature.)
As part of that move, the former SiR (search in range) check box that used to be alongside Show range has been moved below the Find input field, and renamed to Local. If Local is checked, searching can now be done on any content in the lower left panel, and the results are shown as highlighting, rather than a new list.
To complement these new highlighting capabilities, a new feature was added. If you click on the icon next to Make list from highlights the content of the lower left panel will be replaced by a list of just those items that are currently highlighted - whether the highlighting results from a search or a property listing. Note that this can also be useful to refine searches: perform an initial search, convert the result to a list, then perform another search on that list, and so on.
Finally got around to putting icons after the pull-down lists. This means that if you want to reapply, say, a block selection after doing something else, only one click is needed (rather than having to choose another option, then choose the original option). The effect of this on the ease of use of UniView is much greater than I expected.
Added an icon  to the text area. If you click on this, all the characters in the lower left panel are copied into the text area. This is very useful for capturing the result of a search, or even a whole block. Note that if a list in the lower left panel contains unassigned code points, these are not copied to the text area.
to the text area. If you click on this, all the characters in the lower left panel are copied into the text area. This is very useful for capturing the result of a search, or even a whole block. Note that if a list in the lower left panel contains unassigned code points, these are not copied to the text area.
As a result of the above changes, the way Show as graphics and Show range as list work internally was essential rewritten, but users shouldn't see the difference.
Changed the label Character area to Text area.
Changes in version 5.1.0b
Moved the cut&paste field downwards, made it larger, and changed the label to character area. This should make it easier to deal with text copy/cut & paste, and more obvious that that is possible with UniView. It is much clearer now that UniView provides character map/picker functionality, and not just character lookup.
Whereas previously you had to double-click to put a character in the lower left pane into the Cut&paste field, UniView now echoes characters to the Character area every time you (single) click on a character in the lower left hand pane. This can be turned off. Double-clicking will still add the code point of a character in the lower left panel to the Code points field.
The Character area has its own set of icons, some of which are new: ie. you can select the text, add a space, and change the font of the text in the area (as well as turn the echo on and off). I also spruced up the icons on the UI in general.
Note that on most browsers you can insert characters at the point in the Character area where you set the cursor, or you can overwrite a highlight range of characters, whereas (because of the nonstandard way it handles selections and ranges) Internet Explorer will always add characters to the end of the line.
The Code points field has also been enlarged, and I moved the Show list pull-down to the left and Show as graphics and Show page as list to the right. This puts all the main commands for creating lists together on the left.
When you mouse over character in the lower left pane you now see both hex and decimal code point information. (Previously you just saw an unlabelled decimal number.) You will also find decimal code point values for characters displayed in the lower right panel.
Fixed a bug in the Code points input feature so that trailing spaces no longer produce errors, but also went much further than that. You can now add random text containing code points or most types of hex-based escaped characters to the input field, and UniView will seek them out to create the list. For example, if you paste the following into the Code points field:
the decomposition mapping is <U+CE20, U+11B8>, and not <U+110E, U+1173, U+11B8>.
the result will be:
CE20: 츠 [Hangul Syllables]
11B8: ᆸ HANGUL JONGSEONG PIEUP
110E: ᄎ HANGUL CHOSEONG CHIEUCH
1173: ᅳ HANGUL JUNGSEONG EU
11B8: ᆸ HANGUL JONGSEONG PIEUP
Of course, UniView is not able to tell that an ordinary word like 'Abba' is not a hex code point, so you obviously need to watch out for that and a few other situations, but much of the time this should make it much easier to extract code point information.
I still haven't found a way to fix the display bug in Safari and Google Chrome that causes initial content in the lower left pane to be only partially displayed.
Changes in version 5.1.0a
A large amount of code was rewritten to enable data to be downloaded from the server via AJAX at the point of need. This eliminates the long wait when you start to use UniView without the database information in your cache. This means that there is a slightly longer delay when you view a new block, but the code is designed so that if you have already downloaded data, you don't have to retrieve it again from the server.
The search mechanism was also rewritten. The regular expressions used must now be supported in both JavaScript and PHP (PHP is used if not searching within the current range). When 'other' is ticked, the search will look in the alternative name fields, but not in other property settings (so you can no longer use something like ;AL; to search for characters with a particular property. (Use 'Show list' instead.)
Removed several zero-width space characters from the code, which means that UniView now works with Google Chrome, except for some annoying display bugs that I'm not sure how to fix - for example, the first time you try to display any block you only seem to get the top line (although, if you click or drag the mouse, the block is actually there). This seems to be WebKit related, since it happens in Safari, too.
Changes in version 5.1.0
Updated to cover Unicode Version 5.1.0.
Added <option value="(;R;)|(;AL;)">Right-to-left (R or AL)</option> to property lister.
Bugfix: fixed ranges supplied via URI query (used to still split).
Changes in version 5.0.0c
Changed the custom range input to a single field that will accept various range formats.
Added the ability to select whether Search looks at any combination of character names only, other parts of a record in the Unicode database, or the other character description information, and added a message to say how many characters were matched.
Added the ability to search within the range specified in the field entitled Range.
Added the ability to list characters with a given General or Bidirectional property (within a specified range or not).
Added an AJAX link to my database of information about Unicode characters. If enabled, using the DB check box, this automatically retrieves any available data for a character when information about that character is displayed in the lower right panel. You can also specify that UniView should open with that set as the default using database=on in the URI used to call UniView.
Because of the previous improvement, I removed the ability to link in a file of information about characters. (The information in the files was a copy of the information in the database.)
Moved the Code point(s) and Cut & paste fields lower, to make them easier to use.
Fixed a bug that was preventing the Search function finding characters in the Basic Latin block.
Bugfix: a range like 0036:0067 will always show full rows now; a range with start higher than end will show alert.
Added reference to decodeunicode when graphics are displayed in left column
Bugfix: search parameter won't break when graphics etc toggled
You can now specify windowHeight parameter at startup in the URI's query string.
Changes in version 5.0.0b
Extended the ability to open UniView with data displayed from a URI. In addition to specifying a block and a character, you can now
specify a range, a list of codepoints, a list of characters, or a search string. This is useful for pointing people to results using URIs in links or
email.
Switching between graphics or fonts for display of characters now refreshes the right panel also.
Clicking on the information about the script group of a character displayed in the right panel will cause that block to be displayed in
the left panel. This is particularly useful when you find a single character and want to know what's around it.
Replaced the use of hyphens to specify block names in URI queries with underscores or %20. This may break some existing URIs, but fixes a
bug that meant that block names that actually contain hyphens were not displaying.
Added an option to the right hand panel to display the current character in the Unicode Conversion tool.
Fixed some other bugs related to specifying Basic Latin block in a URI.
Reinstated CJK Unified Ideographics and Hangul Syllables in the block selection pull-down, but added a warning and opt out if the block
you are about to display contains more than 2000 characters. Also added warning and opt out if you try to specify a range of over 2000
characters.
Changes in version 5.0.0a
Substantially revised the code so that UniView now handles ideographic and hangul characters and other characters not in the Unidata
database. For example, ideographs now display in the left panel for a specified range and property values are available in the right panel.
Added regular expression support to the search input field.
Changes to the user interface: moved highlighting controls to the initial screens and move others, such as the chart numbering toggle, to
the submenu under "Options"; provided wider input fields for codepoint and cut&paste input; replaced the graphics and list toggle icons with
check boxes; provided an icon to quickly clear the contents of the code point and cut&paste input fields. A link to the UniHan database was added
alongside the Cut & paste input field: when clicked, this icon looks up the first character in either field. A link
to the UniHan database was also added to the right panel when a Unified CJK character is displayed there.
The Codepoint input field now accepts more than one codepoint (separated by spaces).
When you double-click on a character in the left panel the code point is appended to the Codepoint input
field as well as adding the character to the Cut & paste field.
When you click in the check box Show as graphics the change is immediately applied to whatever is in the
left panel. It no longer redisplays the range if you are looking at, say, a list of characters generated by the Codepoint input, but redisplays the same list.
Set the default font to "Arial Unicode MS, sans-serif".
Added a message for those who do not have JavaScript turned on, and messages to please wait while data is being downloaded on initial
startup.
Fixed the icons linking to the converter tool, so that the contents of the adjacent field are passed to the converter and converted
automatically.
Added links in the right panel to FileFormat pages (in addition to decodeUnicode). The FileFormat pages provide useful information for
Java and .Net users about a given character.
Removed the option to specify your own character notes (I'm not aware that anyone ever did, since it hasn't worked for a while now and
no-one has complained). This is because AJAX technology will not allow an XML file to be included from another domain. When that is fixed I will
reinstate it.
Fixed a number of other bugs, particularly related to supplementary character support and highlighting.
Changes in version 5.0.0
Updated to support Unicode 5.0.0.
Restyled the menu panels, moving some less used functions to pop up windows to save on horizontal space.
Implemented an AJAX approach for incorporating notes files. This means that the page no longer has to be reloaded to add notes. It is now
also possible to add more than one set of notes at a time. Note that these changes requires a small change to the markup of notes files - the div
containing the notes for display has to have a class name 'notes' as well as the id for the character.
I added some bundled notes files - most notably Myanmar. Note that these are subject to change on an ongoing basis.
Most of the properties display in the character-detail panel on the right are taken from the unicodedata file at the moment. I plan to
incorporate additional property information over the coming months, but wanted to release this now so that you can get information about Unicode 5
characters sooner rather than later.
Changes in version 4.1.0b
Added a link to the decodeUnicode wiki for each character that is displayed in the right-hand panel.
Provided a way to start up UniView with a particular block and/or character displayed as a table in the lower
panels. This should be particularly useful for pointing a person to a particular Show block or character in a URI.
Fixed a couple of minor bugs in the CSS.
Changes in version 4.1.0a
Rearranged the top of the page to allow UniView to be used in narrower windows.
Added support for Unicode version 4.1.0.
Retrieves graphics from decodeunicode.org rather than the slow-loading and sparse graphics that were available from the Unicode site.
Also added my own graphics where decodeunicode has gaps.
Moved the files to PHP. This enables a different approach to the inclusion of user-defined notes that now works on IE and Opera, too.
Another benefit of using PHP is that you can now prep the conversion page with data in the 'Code point' or 'Cut & paste' fields. By
clicking on the appropriate icon, the conversion page will now open with the conversions already done for the relevant field.
Yet another benefit of PHP is that, if you really want to, you can now set various preferences related to the initial look and feel by
specifying them as query parameters when you call UniView.
NOTE: If you want to be able to download UniView to your hard drive and you don't have a server and PHP, let me know.
If enough people ask for it, I will create a downloadable zipped package again that will work without PHP (and without the additional notes feature).
I will also post notes on how to customise various aspects of the setup.
Note also that I have disabled links to the French version until and new French translation has been prepared. I will probably not do
language based content-negotiation.
Changes in version 4.1
Surrogate support added.
You can now double-click on any line in a list on the left, and the character will appear in the Cut&Paste field above.
Han and Hangul character glyphs are now displayed in the right panel after entering a code point in the Code Point field. There may not be
much information available, but at least you can see the character if you have a font that supports it.
Changes in version 4.0.1
Minor improvements to user interface, including provision of tooltips for all feature selectors.
Disabled (attempts to) display user-defined notes for IE and Opera. I still haven't found how to make it work yet, even using proprietary
coding, but at least the attempt won't crash the browser now.
Provided a facility to allow visible area in left panel to be increased.
Changes in version 4.0
Name changed to UniView.
Support for Unicode 4.0.0.
No frames. Cross-browser support.
You can specify your preferred default font for display of Unicode characters in prefs.js. If an alternative font is applied using the
control on the page, it remains in force for any view until the user sets it back to the default.
Highlighting of General or Bidi properties remains in force until you disabled it, and applies to any matrix or list in the left panel
(ie. including search results and cut & paste results).
Script blocks are now grouped with visible labels in the main range-selection pulldown.
Mousing over a character in matrix or list view produces a tool tip containing the decimal code value for the character. In the previous
version this was the Hex value, and was limited to the matrix view.
There are no facilities to display information in a pop-up window instead of in the main window. If you want to temporarily display
information separately, open a new window.
You used to be able to double-click on a list or on the character descriptions to make the highlighted text appear in various fields.
This has not been implemented, but you can still highlight and drag, or copy and paste the text.
Because character sizes are specified in pixels for cross-browser consistency, you must use IE's accessibility options to increase
character size in IE over and above what is available from the font size setting provided on the page.
Options for displaying in page descriptions of script blocks have been disabled. Open the files in a separate tab or window as a
standalone file.
 and
and  . A double-click will still copy the character to the text area.
. A double-click will still copy the character to the text area. does the opposite, and opens the Converter app in a new window and shows escapes for the characters in the text area.)
does the opposite, and opens the Converter app in a new window and shows escapes for the characters in the text area.) enables you to convert a row of characters into a column. First add spaces where you want the line-breaks to appear (for which you may be able to use
enables you to convert a row of characters into a column. First add spaces where you want the line-breaks to appear (for which you may be able to use  ), then click on this icon.
), then click on this icon.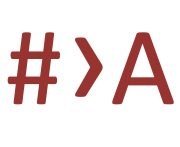 (just below the text area) converts all the characters in the text area to space-separated hexadecimal values.
(just below the text area) converts all the characters in the text area to space-separated hexadecimal values. 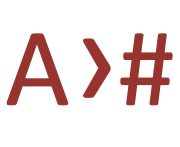 Does the inverse: it converts a set of space-separated hex codes to characters. In fact, it can also accept a range of escapes as input, and they don't need to be space-separated.
Does the inverse: it converts a set of space-separated hex codes to characters. In fact, it can also accept a range of escapes as input, and they don't need to be space-separated.