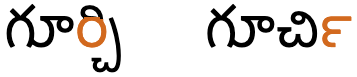This page brings together basic information about the Telugu script and its use for the Telugu language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Telugu using Unicode.
The Telugu script ( తెలుగు లిపిˈtɛ.lʊ.ɡuː li.piTelugu script ) is used for writing the Telugu language, a Dravidian language spoken by almost 70,000,000 people in South India, and the official language of the Indian state of Andhra Pradesh. It is also used for a number of minority languages, and other neighbouring Indian states.
This script and Kannada (which is similar enough for people who can read one to be able to read the other) both developed together from the Brahmi script, but diverged around the 13th century. From then until recently, Telugu was a literary language, reflecting an archaic spoken form, but it was altered to support modern communication in the second half of the 20th century.
Unicode 17 has 1 dedicated Telugu block, comprising 101 characters.
The Telugu script is an abugida, ie. each consonant contains an inherent vowel sound.
The script is visually different from scripts like Devanagari and Bengali due to the rounded bases of the letters, which sit on rather hanging from a baseline. It also differs in the replacement of the flat, joining headstroke with a hook above the top of many characters. The hook is removed to accommodate superscript vowel signs and the virama.
Most vowel signs interact typographically with their base consonant, replacing the check mark above the base. A few also produce slightly different joined shapes.
There are no pre-base glyphs but 1 circumgraph. In principle, Balinese has no composite vowel signs, however the circumgraph can also be decomposed into 2 parts, displayed on either side of the base.
Vowel absenceVowel absence is normally indicated using conjunct forms, or dedicated syllable-final combining marks. Occasionally, a visible virama is used. There are no dedicated medial consonant characters.
0C4D is used to form conjuncts. Usually the virama is invisible, but it is occasionally rendered visibly.
Conjunct forms occur as conjoined pairs with half-forms, stacked consonants, and ligated glyphs. The shape of many subjoined consonant glyphs differs from the normal shape.
Conjuncts are fairly regular and nearly always consist of a full-form initial consonant followed by a subjoined version of the second. The subjoined version loses the hook, and in about 50% of cases is transformed. Many subjoined forms rise above the baseline to the right of the initial consonant, but any vowel signs attached to the cluster appear above or to the right of the initial consonant (which may be between the two consonant glyphs in the latter case). Some conjuncts are formed from conjoined pairs where the second letter is reduced and extends below the baseline. Gemination is quite common.
As part of a cluster, RA is formed in the same way as other conjuct members in the modern orthography, however historically there was a special behaviour.
Syllable codas are commonly written using ordinary letters, but there are also a couple of dedicated combining marks in Telugu (anusvara & visarga). When followed by another consonant, the coda and following onset are usually rendered as a conjunct..
Numbers Telugu has a set of native digits but doesn't often use them in modern texts. Until the adoption of the metric system, Telugu used a complicated system for writing fractions, with dedicated symbols that were combined in various ways.
Layout Telugu text runs left-to-right in horizontal lines. Words are separated by spaces. There is no case distinction.
Punctuation is mostly ASCII, but dandas are used for sentence and verse final punctuation.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Plain vowels.
o cannot appear at the end of a word.wl§#Phonology
æː occurs in loan wordswl§#Phonology, but may also occur before a syllable with the sounds a, o, or u, and in some verbal forms.d§417
Diphthongs
Consonant sounds
labial
alveolar
post-
alveolar
retroflex
palatal
velar
glottal
stops
pb
td
ʈɖ
cɟ
kɡ
ʔ
aspirated
pʰbʰ
tʰdʰ
ʈʰɖʰ
kʰɡʰ
affricates
t͡sd͡z
t͡ʃd͡ʒ
aspirated
t͡ʃʰd͡ʒʰ
fricatives
f
s
ʃ ɕ
ʂ
h
nasals
m
n
ɳ
ɲ
ŋ
approximants
ʋ
l
ɭ
j
trills/flaps
ɾ
Aspirated or breathy consonants were introduced by and are mostly used by loan words, particularly from Sanskrit. The same goes for fricatives other than s.wl§#Phonology
ɲ and ŋ are associated with Sanskrit, and are relatively rare in Telugu.d§416
Tone
Telugu is not a tonal language.
Structure
The typical unit of the orthography is the orthographic syllable, consisting of a consonant and vowel (CV) core and, optionally, one or more preceding consonants. Consonant letters by themselves constitute a CV unit, where the V is an inherent vowel. A dependent vowel sign is used to represent the V in CV units where V is not the inherent vowel.
In some cases, diacritics can be used to represent a syllable-final nasal.
Telugu words almost always end in short vowels, although modern Telugu allows m, n, y, and w to end a word, and loan words sometimes end with long vowels.wl§#Phonology
Geminate consonants are also a common feature of Telugu, mostly in word-medial positions, and are distinctive,wl§#Phonology eg. compare గదిగద్ది
Unlike some other Dravidian languages, voiced sounds were always part of the Telugu language.wl§#Phonology
Retroflex consonants appear initially (apart from ɳ and ɭ), and medially, where they may be part of a retroflex cluster.wl§#Phonology
j occurs in word-initial position only in borrowed words, such as jɐnɡuyoung.wl§#Phonology
Vowels
Post-consonant
Standalone
Plain
ి,ీ,ు,ూ
ఇ,ఈ,ఉ,ఊ
ె,ే,ొ,ో
ఎ,ఏ,ఒ,ఓ
ా,ⓘ,ా
అ,ఆ
Dipthongs
ై,ౌ
ఐ,ఔ
Vocalics
ృ
ఋ
ⓘ represents the inherent vowel.
Inherent vowel
క
ka
The inherent vowel for Telugu is pronounced a, so ka is written by simply using the consonant letter.
eg.
కడలి
క,డ,ల,ి
Since Telugu consonants normally include an inherent vowel, the orthography has ways to indicate a consonant that is not followed by a vowel sound. See novowel.
Post-consonant vowels
కి
ki
Post-consonant vowels are written using 11 vowel signs, all combining marks, and only one per base.
Two vowel signs are spacing marks, meaning that they consume horizontal space when added to a base consonant.
Unusually for Brahmi-derived scripts, when a vowel is pronounced after a conjunct, the vowel sign is attached to the first consonant in a cluster, even where the vowel sign pushes the two consonant glyphs apart (see fig_vowel_position).
In the sequence స్పిs͓pi the i (coloured) appears above the s, and in స్పూs͓pū the u (coloured) appears to the right of the s (not the p!).
The text is still entered following the spoken order: it is incorrect to type the vowel sign after the first consonant.
eg.
కన్ను
క,న,్,న,ు
There are no pre-base glyphs but there is 1 circumgraph. In principle, there are no multipart vowels, however the circumgraph can be decomposed into 2 parts, displayed on different sides of the base.
Simple vowels
Telugu uses the following dedicated combining marks for plain vowel sounds. They may be used on their own, or in combination with others (see circumgraphs).
ి,ీ,ు,ూ,ె,ే,ొ,ో,ా
Diphthongs
Telugu has 2 vowel signs that represent diphthongs.
ై,ౌ
Vowel length
Differences in vowel length are indicated by the choice of vowel sign.
Standalone vowels
Telugu represents standalone vowels using a set of independent vowel letters. The set includes a character to represent the inherent vowel sound.
ఇ,ఈ,ఉ,ఊ,ఎ,ఏ,ఒ,ఓ,అ,ఆ, ,ఐ,ఔ
eg.
ఒకటి
ఐదు
ఇరవై
Vowel composition
This section describes various vowel components and behaviours associated with this orthography.
Circumgraph
ై
One vowel is produced by a single combining character with visually separate parts, that appears on opposite sides of the consonant onset (above and below, in this case).
eg.
పైడి
ఇరవై
These do not split a non-spacing conjunct, but instead they treat the conjunct as a single unit and place glyphs above and below it. However, as described earlier, when the conjunct is spacing, the parts of the circumgraph are placed around the first consonant in the cluster. In either case, however, the circumgraph is typed and stored after the cluster as a whole.
eg.
రద్దైన
ర,ద,్,ద,ై,న
చెన్నై
చ,ె,న,్,న,ై
Encoding. The circumgraph can be written as a single character, or as two.
0C48
0C46 0C56
The single code point per vowel sign is the form preferred by the Unicode Standard and the form in common use for Telugu. The parts are separated, however, in Unicode when normalised using Normalisation Form D (NFD).
Whichever approach is used, the vowel signs must be typed and stored after the consonant characters they surround. In the case of decomposed vowel signs, the order is also important and must be as shown above.
Composite vowel signs
Composites occur in decomposed text, where the glyphs in Telugu's circumgraph are split into separate code points. This is the only place where 0C56 occurs.
ై
Another code point representing a partial glyph is 0C55. This does not normally occur in Telugu text (see encoding).
Vowel sign placement
The following list shows where vowel signs are positioned around a base consonant to produce vowels for precomposed text, and how many instances of that pattern there are. The figure after the + sign represents combinations of Unicode characters,
2 post-base, eg. కుku
8 superscript, eg. కిki
1 super+subscript. eg. కైkaʲ
At maximum, vowel components can occur concurrently on 2 sides of the base.
Vowel sounds to characters
This section maps Telugu vowel sounds to common graphemes in the Telugu orthography.
The left column shows dependent vowels, and the right column independent vowel letters.
Plain vowels
i
dependentి
standaloneఇ
iː
dependentీ
standaloneఈ
u
dependentు
standaloneఉ
uː
dependentూ
standaloneఊ
e
dependentె
standaloneఎ
eː
dependentే
standaloneఏ
o
dependentొ
standaloneఒ
oː
dependentో
standaloneఓ
æː
dependentే
dependentా
a
inherent voweleg. కడలి
standaloneఅ
aː
dependentా
standaloneఆ
Complex vowels
aj
dependentై
standaloneఐ
aw
dependentౌ
standaloneఔ
Vocalics
Only one of the vocalics is common in Telugu.
ృ, ,ఋ
eg.
కృష్ణ
తృప్తి
ఋతువు
The remainder are used for Sanskrit texts.
ౢ,ౄ,ౣ, ,ౠ,ఌ,ౡ
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Given that consonants normally include an inherent vowel, the orthography needs a way to indicate when a consonant is not followed by a vowel.
Follow these links for more information.
Conjuncts. The absence of a vowel sound between two or more consonants is visually indicated by using conjunct forms, where the second consonant is a subscript. There are a number of possibilities here.
Simple stacking : A reduced-size version of the 2nd consonant has any headstroke removed and is simply positioned below the 1st.
Conjoined with reduced forms : The shape of the 2nd consonant is transformed into something that sits alongside the 1st, but extends above and below the baseline.
Show a visible virama above the consonant that has no following vowel.
Coda diacritics. Some Telugu codas can be written using combining marks.
Conjuncts
Conjunct formation
In Unicode, the transformation of the 2nd consonant is achieved by adding 0C4D between the consonants. The font hides the glyph automatically.
fig_stacks shows consonants subjoined below themselves that are simply reduced in size, stripped of any headstroke, and positioned directly below the initial consonant. This approach is particularly common for geminated consonants.
ట,్,ట,ట్ట
ష,్,ఠ,ష్ఠ
Examples of conjuncts formed by subjoining non-initial consonants.
Show more stacked consonants (font dependent)ద్ద,థ్థ,ధ్ధ,ట్ట,డ్డ,ఠ్ఠ,ఢ్ఢ,గ్గ,ఖ్ఖ,ఘ్ఘ,ష్ష,హ్హ,ఞ్ఞ,ణ్ణ,ఙ్ఙ,ఱ్ఱ,ఴ్ఴ
Stacking with transformations
The following consonants are also subjoined below the first, but are rendered with a very different shape.
త,్,త,త్త
ర,్,ర,ర్ర
ల,్,ల,ల్ల
క,్,ష,క్ష
Examples of conjuncts where subjoined forms have very different shapes.
Conjoined with reduced, spacing form
The second consonant in these clusters is transformed into a spacing glyph that extends above and below the baseline.
త,్,య,త్య
ర,్,మ,ర్మ
న,్,న,న్న
త,్,స,త్స
Examples of conjoined conjuncts.
In a conjunct of this kind, any vowel sign is visually attached to the initial consonant letter but still typed and stored after the conjunct.
eg.
అన్నీ
అ,న,్,న,ీ
Show more conjoined consonants (font dependent)ప్ప,బ్బ,ఫ్ఫ,భ్భ,క్క,స్స,శ్శ,మ్మ,న్న,వ్వ,ళ్ళ,య్య
Triple-consonant clusters
Telugu has a number of clusters involving 3 consonants. For example, the following words contain triple-consonant clusters. As always, click on the example to see the composition.
ర,్,ష,్,య,ర్ష్య
స,్,త,్,ర,స్త్
క,్,ష,్,మ,క్ష్మ
Examples of triple-consonant conjuncts.
eg.
ఈర్ష్య
మేస్త్రి
లక్ష్మి
Visible virama
Telugu words usually end with a vowel.
eg.
ఇక్కడ
In traditional Telugu there is always a vowel sound at the end of a word, however in the modern language it is possible for m, n, y, and w to end a wordwl§#Phonology.
Telugu uses 0C4D (called virāmamu in Telugu) to show that the inherent vowel after a consonant is not pronounced, eg. ల్ explicitly represents just the sound l.
eg.
హాస్పిటల్
The virama is usually hidden when the consonant is part of a consonant cluster (see clusters).
Consonants
ప,బ,త,ద,ట,డ,క,గ
ఫ,భ,థ,ధ,ఠ,ఢ,ఖ,ఘ
చ,చ,జ,జ, ,ఛ,ఝ
స,శ,ష,హ,ః
మ,ం,న,ం,ఞ,ణ,ఙ,ం
వ,ర,ఱ,ల,ళ,య
Basic consonants
The basic consonant sounds in Telugu are written using the following letters.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
Unicode 14 introduced a nukta, ఼, to the Telugu block for representing additional sounds from Tamil and Perso-Arabic languages.
Onsets
Clusters of consonant letters at the beginning of an orthographic syllable occur in Telugu, and they are handled as described in the section clusters.
eg.
ప్రశ్న
క్షురము
జ్ఞానము
Codas
Syllable codas are commonly written using ordinary letters, but there are also a couple of dedicated combining marks in Telugu. When followed by another consonant, the coda and onset are usually rendered as a conjunct (see clusters).
For older texts, the Unicode Standard describes a final n sound called nakāra pollu which, rather than being written న్, has a special shape. Unicode 14 added the separate code point 0C5D to represent this shape.u16§#G687332
RA coda
In modern Telugu, clusters that begin with r are formed in the normal way.
eg.
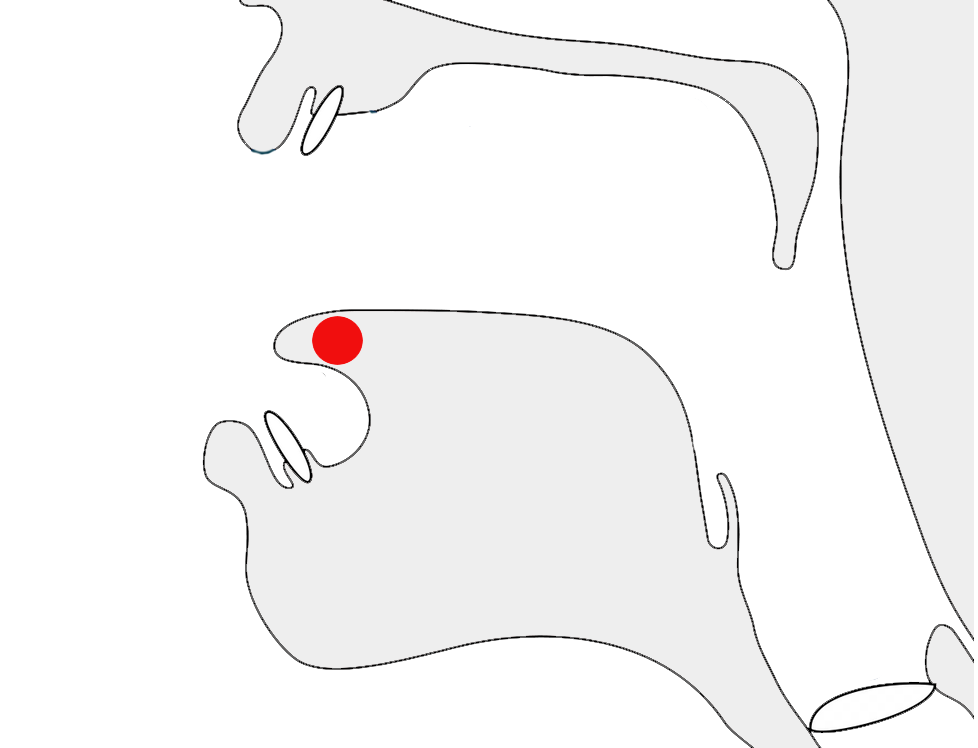
గూర్చి
In older texts, however, the r is represented as a special form to the right of the second consonant, and the second consonant is left intact and carries any vowel signs. See fig_gurci for an example.
The word guːrt͡ʃi spelled in the modern way (left), and with a reph (right). Colour is used to indicate the visual location of the r sound.show composition
గూర్చి
This effect can be produced in Unicode using 200D immediately after the virama, although not all fonts support it.
eg.
గూర్చి
గ,ూ,ర,్,,చ,ి
In a font that shows the reph form by default, it should be possible to disable it using the ZWJ before the virama instead of after it, as long as the font supports it.
Combining marks
There are several ways of representing syllable-final nasals.
Nasals can be written using 0C02. Before a plosive this is pronounced as a homorganic nasal.
eg.
అంగము
It is pronounced m when followed by a non-plosive consonant, or at the end of a word,d§415.
eg.
సింహలగాం
Syllable final h (usually pronounced ha) can be written with 0C03, which is principally used for Sanskrit words.
eg.
పునః
Consonant length
Gemination and consonant lengthening are handled using the normal approach to consonant clusters (see clusters).
Consonant sounds to characters
This section maps Telugu consonant sounds to common graphemes in the Telugu orthography.
p
్పconsonantప
pʰ
్ఫconsonantఫ
b
్బconsonantబ
bʰ
్భconsonantభ
t
్తconsonantత
tʰ
్థconsonantథ
t͡ʃ
్చconsonantచ
t͡s
్చconsonantచin native Dravidian words when followed by a, o or u sounds.
t͡ʃʰ
్ఛconsonantఛ
d
్దconsonantద
dʰ
్ధconsonantధ
d͡ʒ
్జconsonantజ
d͡z
్జconsonantజin native Dravidian words when followed by a, o or u sounds.
d͡ʒʰ
్ఝconsonantఝ
ʈ
్టconsonantట
ʈʰ
్ఠconsonantఠ
ɖ
్డconsonantడ
ɖʰ
్ఢconsonantఢ
k
్కconsonantక
kʰ
్ఖconsonantఖ
ɡ
్గconsonantగ
ɡʰ
్ఘconsonantఘ
s
్సconsonantస
ʃ
్శconsonantశ
ʂ
్షconsonantష
h
్హconsonantహ
ha
final consonantః
m
్మconsonantమ
final consonantంas a syllable coda.
n
్నconsonantన
final consonantంas a syllable coda.
ɲ
్ఞconsonantఞ
ɳ
్ణconsonantణ
ŋ
final consonantంas a syllable coda.
consonant్ఙఙAssociated with Sanskrit, and relatively rare in Telugu.
ʋ
్వconsonantవ
r~ɾ
్రconsonantర
ru~ri
vocalic vowel signృ
independent vocalicఋ
ɽ
్ఱconsonantఱ
l
్లconsonantల
ɭ
్ళconsonantళ
j
్యconsonantయ
Other features
Other letters
These are other characters in the Telugu block that are archaic and have the general category of letter.
ఽ,ౘ,ౙ,ౚ,ఴ
The Telugu block contains a single character with the symbol property, but it isn't used for modern Telugu.
౿
Encoding choices
Visually, several of the standalone vowels and some vowel signs look as it they could be composed of smaller parts. This section compares approaches and considers the relevance of Unicode Normalisation Form D (NFD) and Unicode Normalisation Form C (NFC) to give guidance on which approach is best.
Vowel signs
The vowel signs for iː, eː, and oː should each be written with one of the single code points listed above. Those code points do not decompose in NFD. The Unicode Standard warns not to make up the shapes using combinations of characters.
Use
Do not use!
0C40
0C3F 0C55
0C47
0C46 0C55
0C4B
0C4A 0C55
The vowel sign for ai decomposes and recomposes during normalisation. It is therefore possible to find it encoded as either 0C48 or 0C46 0C56. It is normal to use the precomposed version.
Precomposed (recommended)
Decomposed
0C48
0C46 0C56
0C56 is only used in decomposed versions of 0C48.
Independent vowels
The independent letters also should each be written with one of the single code points listed just above. The Unicode Standard warns not to make up the shapes using a combination of characters for aw and oː.
Use
Do not use!
ఓ
0C12 0C55
ఔ
0C12 0C4C
Numbers
Digits
Telugu has native digits, but they are only used infrequently.
౦,౧,౨,౩,౪,౫,౬,౭,౮,౯
The CLDR standard-decimal pattern is #,##,##0.###. The standard-percent pattern is #,##0%.
Fractions
The Unicode Standard describes the use of fraction characters as follows.
Prior to the adoption of the metric system, Telugu fractions were used as part of the system of measurement. Telugu fractions are quaternary (base-4), and use eight marks, which are conceptually divided into two sets. The first set represents odd-numbered negative powers of four in fractions. The second set represents even-numbered negative powers of four in fractions. Different zeros are used with each set. The zero from the first set is known as hakki, ౸. The zero for the second set is ౦.u§501
౸,౹,౺,౻,౼,౽,౾,౿
Currency
The CLDR standard format for currency is ¤#,##,##0.00, and the symbol for the Indian rupee is ₹.
A majority of the Telugu consonants have a v-shaped headstroke, which is equivalent to the horizontal line in Devanagari. This headstroke is replaced when marks appear above the consonant, eg. క becomes క్ when followed by an explicit virama and కి when followed by the i vowel sign.u§499
Out of 36 consonants, the following are the 9 that don't have a headstroke:
ఖ,ఙ,జ,ఞ,ట,ణ,బ,ల,ఱ
Vowel signs
Most vowel signs interact typographically with their base consonant, replacing the check mark above the base.
A few also produce slightly different joined shapes. For example, in addition to the standard కిki0C3F produces shapes such as the following: గిgiచిci
Also, 0C4A and 0C4B adopt very different shapes when they follow m or y, ie. మొmoమోmōయొyoయోyō
Context-based positioning
Vowel signs need to be correctly positioned relative to the base character, and multiple marks can be combined with a single base character, eg. in అర్పించాలిạr͓pim̽cālioffer the i vowel sign needs to be positioned over the initial consonant in the cluster, even though it occurs after the second in memory. The glyph also has to be carefully positioned with respect to the base character it is attached to.
That example also shows the use of multiple diacritics attached to the same base consonant.
See also the special positioning rules described in reph.
Explicit shaping controls
200C (ZWNJ) is used to prevent the formation of a conjunct (see finals).
200D (ZWJ) is used to control font glyph selection (see reph).
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
tbd
Punctuation & inline features
Phrase & section boundaries
Telugu uses ASCII punctuation, but may also use a couple of indic punctuation marks.
phrase
,
;
:
। (infrequent)
sentence
.
?
!
॥ (infrequent)
। and ॥ are used primarily in the domain of religious texts to indicate the equivalent of a comma and full stop, respectively.u§501
Bracketed text
Telugu commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Quotations & citations
Telugu texts use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
“
”
nested
‘
’
Single quotation marks are used for quotations within quotations.
Line & paragraph layout
Line breaking & hyphenation
Spaces provide the main line break opportunities, however Telugu is an agglutinative language and Telugu words can be long. This can lead to large gaps during justification, and sometimes words that are longer than the available column width, so it is desirable to also hyphenate words.
Because of the length of Telugu words, in-word line-breaks (hyphenation) are very common and needed during layout, especially in narrow columns, such as newsprint.
Hyphenation mostly takes place at syllable boundaries, however there are also occasional exceptions and special cases.
Observation:InDesign produces a hyphen at the end of a line to mark that hyphenation has split a word.
Hyphenated Telugu text as produced by InDesign.
Line-edge rules
Like most writing systems, certain characters are expected not to start or end a line. For example, periods and commas shouldn't start a line, and opening parentheses shouldn't end a line.
Baselines, line height, etc.
tbd
Telugu uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
Counters, lists, etc.
You can experiment with counter styles using the Counter styles converter. Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
The modern Telugu orthography uses a native numeric style.
Numeric
The telugu numeric style is decimal-based and uses these digits.rmcs
౧,౨,౩,౪,౫,౬,౭,౮,౯,౦
eg.
౧,౨,౩,౪,౧౧,౨౨,౩౩,౪౪,౧౧౧,౨౨౨,౩౩౩,౪౪౪
Prefixes and suffixes
Telugu commonly uses a full stop + space as a suffix.
౧. ౨. ౩. ౪. ౫.
Separator for Telugu list counters: full stop + space.