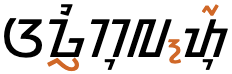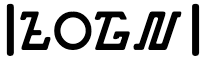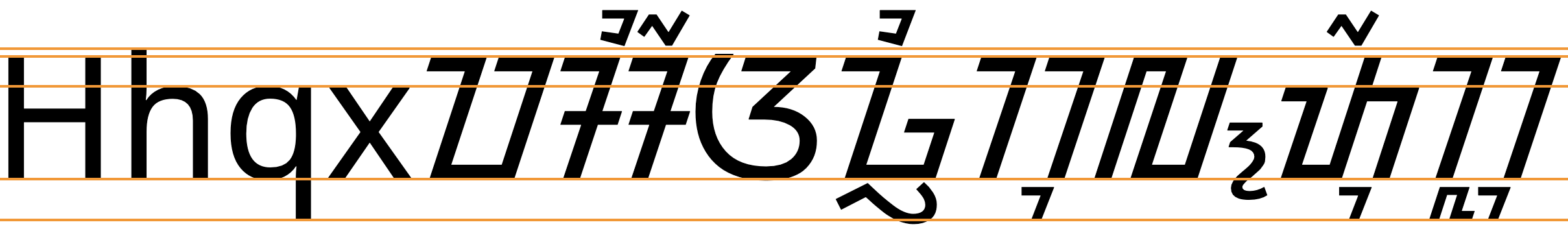This page brings together basic information about the Sundanese script and its use for the Sundanese language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Sundanese using Unicode.
Since 1996 the Sundanese script ( ᮃᮊ᮪ᮞᮛ ᮞᮥᮔ᮪ᮓ ) has been the official orthography for the 27 million Sundanese speakers on the island of Java, although the Latin script is also used. It is currently taught in schools and used for public signage.
The modern orthography is derived from the Old Sundanese orthography (Aksara Sunda Kuno) which was used by the Sundanese between the 14th and 18th centuries. It, in turn, derived from the Pallava script.
Unicode 17 has 2 dedicated Sundanese blocks, comprising 72 characters.
Vowel absenceVowel absence in modern Sundanese writing is indicated using either a visible vowel killer, a medial consonant diacritic, or a word-final consonant diacritic. There are no stacked consonants or other conjuncts in modern Sundanese, however they were used in the Old Sundanese orthography.
᮪ is used to indicate the absence of the inherent vowel. It is always visible.
Syllable codas are also written using 3 dedicated combining marks. When a vowel sign and final consonant are both attached to the same base, they are arranged side by side..
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Consonant sounds
labial
alveolar
post-
alveolar
palatal
velar
uvular
glottal
stop
pb
td
kɡ
q
affricate
t͡ʃd͡ʒ
k͡s
fricative
fv
sz
x
h
nasal
m
n
ɲ
ŋ
approximant
w
l
j
trill/flap
r
Structure
An orthographic syllable in modern Sundanese can be described as one of
C {y,r,l} {vs} {ng,r,h}
Cp
V {ng,r,h}
where C is a consonant and V is an independent vowel, y,r,l represents a medial combining character, vs a vowel sign, ng,r,h a syllable-final combining character, and p a vowel-killer.
Tone
Sundanese is not a tonal language.
Vowels
Post-consonant
Standalone
◌ᮤ, ,◌ᮥ
ᮄ, ,ᮅ
◌ᮩ
ᮉ
◌ᮨ
ᮈ
◌ᮦ,,◌ᮧ
ᮆ,,ᮇ
ⓘ
ᮃ
ⓘ represents the inherent vowel.
Inherent vowel
ᮊ
ka
The inherent vowel for Sundanese is pronounced a. So ka, la, and pa in the following example are written by simply using the consonant letter.
eg.
ᮊᮜᮕ
ᮊ,ᮜ,ᮕ
Since Sundanese consonants normally include an inherent vowel, the orthography has ways to indicate a consonant that is not followed by a vowel sound. See novowel.
Post-consonant vowels
Post-consonant vowels are written using 6 combining marks (vowel signs). There are no vowel letters.
All vowel signs are typed and stored after the base consonant, whether or not they precede it when displayed. The glyph rendering system takes care of the positioning at display time.
Two vowel signs are spacing marks, meaning that they consume horizontal space when added to a base consonant.
Simple vowels
ᮊᮤ
kiː
Sundanese uses the following dedicated combining marks for vowels.
◌ᮤ,◌ᮥ,◌ᮩ,◌ᮨ,◌ᮦ,◌ᮧ
eg.
ᮒᮤᮝᮥ
ᮌᮧᮛᮦᮀ
ᮌᮨᮜᮥᮒ᮪
Standalone vowels
ᮃ
a
Sundanese represents standalone vowels using 7 independent vowel letters, including one for the equivalent of the inherent vowel.
ᮄ,ᮅ,ᮉ,ᮈ,ᮆ,ᮇ,ᮃ
eg.
ᮄᮔ᮪ᮓᮥᮀ
ᮅᮎᮤᮀ
ᮃᮇᮞᮩᮔ᮪
ᮊᮩᮉᮙ᮪
Independent vowels can carry syllable-final consonants.
eg.
ᮃᮀᮌᮛ
ᮊᮥᮆᮂ
Vowel composition
This section describes various vowel components and behaviours associated with this orthography.
Pre-base vowel sign
One vowel sign appears to the left of the base consonant letter or cluster.
ᮦ
eg.
ᮘᮦᮛᮦ
This is a combining mark that is always typed and stored after the base consonant(s), ie. the codepoints follow the order in which the items are pronounced. The rendering process places the glyph before the base consonant without changing the code points. The following shows the sequence of code points that make up the word just above.
ᮘ,ᮦ,ᮛ,ᮦ
A prebase vowel sign appears to the left of the consonant after which it is pronounced.show composition
ᮛᮦᮌᮀ
Vowel sounds mapped to characters
This section maps Sundanese vowel sounds to common graphemes in the Sundanese orthography.
Alternative dependent (post-consonant) and standalone vowel letters are labelled.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
Plain vowels
i
dependentᮤ
standaloneᮄ
ɨ
dependentᮩThis is an allophone of ɤ.
standaloneᮉ
u
dependentᮥ
standaloneᮅ
e
dependentᮦThis is an allophone of ɛ.
standaloneᮆ
ɤ
dependentᮩ
standaloneᮉ
o
dependentᮧThis is an allophone of ɔ.
standaloneᮇ
ə
dependentᮨ
standaloneᮈ
ɛ
dependentᮦ
standaloneᮆ
ɔ
dependentᮧ
standaloneᮇ
a
inherent voweleg. ᮊᮜᮕ
standaloneᮃ
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
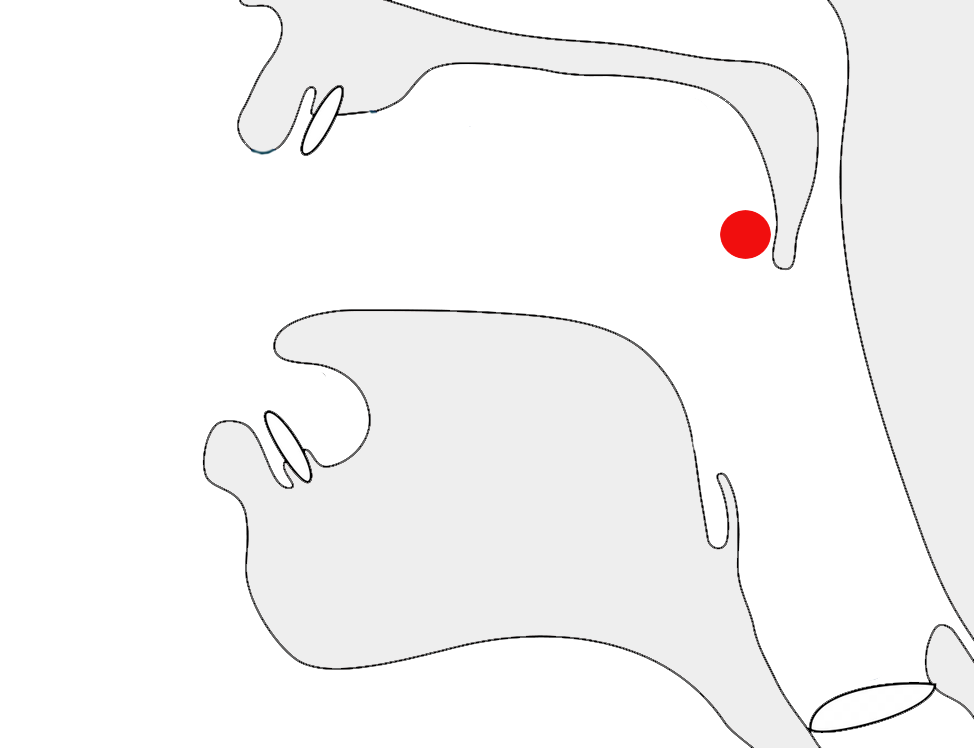
For example, ᮃᮌᮢᮤᮊᮥᮜ᮪ᮒᮥᮁ contains all three, as can be seen in fig_vowel_absence.
Left to right, the highlights show a medial diacritic, a pamaaeh, and a final consonant diacritic.show composition
1BAA is used at the end of a word. If there is no pamaaeh the inherent vowel is pronounced.
eg.
ᮘᮤᮔᮨᮊᮞ᮪
ᮘᮤᮔᮞ
Pamaaeh in word-final position.show composition
ᮄᮊᮣᮤᮙ᮪
Pamaaeh is also used for word-internal consonant clusters. It doesn't cause any conjunct formation and is always visible.
eg.
ᮃᮊ᮪ᮞᮛ
ᮛᮔ᮪ᮎ
The word aksara, showing pamaaeh vowel killer.show composition
ᮃᮊ᮪ᮞᮛ
Syllable-initial consonant clusters allow 3 sounds after the initial consonant, j, r, or l. These are all represented using dedicated combining marks (see onsets).
Old Sundanese
Historical Sundanese does have conjunct forms. They can be produced using the invisible 1BAB. The following shows known conjuncts:os
Historically, Sundanese also had special forms for subjoined -m and -w. These can be represented using 1BAD and 1BAC.
ᮬ,ᮭ
Consonants
Onsets
ᮕ,ᮘ,ᮒ,ᮓ,ᮊ,ᮌ,ᮋ, ,ᮟ
ᮎ,ᮏ
ᮖ,ᮗ,ᮞ,ᮯ,ᮐ,ᮮ,ᮠ
ᮙ,ᮔ,ᮑ,ᮍ
ᮝ,ᮛ,ᮜ,ᮚ
Medials
◌ᮢ,◌ᮣ,◌ᮡ
Codas
◌ᮂ, ,◌ᮀ, ,◌ᮁ
Basic consonants
The Sundanese block has 18 consonant letters for indigenous sounds in modern Sundanese writing.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
ᮕ,ᮘ,ᮒ,ᮓ,ᮊ,ᮌ,ᮎ,ᮏ,ᮞ,ᮠ,ᮙ,ᮔ,ᮑ,ᮍ,ᮝ,ᮛ,ᮜ,ᮚ
Repertoire extension
An extended set of consonants is used to represent non-native sounds, eg. Arabic.
ᮟ,ᮋ,ᮖ,ᮗ,ᮐ,ᮯ,ᮮ
eg.
ᮕ᮪ᮛᮧᮖᮦᮞᮧᮛ᮪
ᮮᮥᮯᮥ
Onsets
The three trailing consonants that can appear in syllable-initial pairs are written using dedicated combining marks.
ᮢ,ᮣ,ᮡ
eg.
ᮠᮡᮀ
ᮙᮧᮊᮣ
ᮞᮢᮍᮦᮍᮦ
Observation: The transcriptions of a small number of entries in the Wiktionary termlist suggest that these medial consonants may also be used for regular consonant clusters.
eg.
ᮓᮥᮔᮡ
ᮙᮧᮊᮣ
Codas
The three syllable-final consonant sounds are also represented using dedicated combining marks.
ᮀ,ᮁ,ᮂ
eg.
ᮘᮀᮌ
ᮘᮩᮀᮠᮁ
ᮛᮩᮔᮩᮂ
They can be attached to independent vowels, as well as consonants.
ᮃᮄᮀ
ᮒᮥᮅᮁ
ᮊᮥᮆᮂ
When the coda occurs after ᮧ it is positioned above the vowel sign, rather than above the consonant.
eg.
ᮘᮍᮧᮁ
ᮕᮕᮒᮧᮀ
If the vowel sign and coda appear above the base, they are arranged side by side.
eg.
ᮊᮙᮜᮤᮁ
ᮞᮤᮀᮊᮥᮁ
Consonant to script mapping
This section maps Sundanese consonant sounds to common graphemes in the Sundanese orthography.
Alternative onset, medial, and final consonants are labelled.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
onsetᮕ
b
onsetᮘ
t
onsetᮒ
t͡ʃ
onsetᮎ
d
onsetᮓ
d͡ʒ
onsetᮏ
k
onsetᮊ
ks
onsetᮟfor transliteration of foreign words.
ɡ
onsetᮌ
q
onsetᮋfor transliteration of foreign words.
f
onsetᮖfor transliteration of foreign words.
v
onsetᮗfor transliteration of foreign words.
s
onsetᮞ
onsetᮯfor transliteration of foreign words.
z
onsetᮐfor transliteration of foreign words.
x
onsetᮮfor transliteration of foreign words.
h
onsetᮠ
codaᮂCoda.
m
onsetᮙ
n
onsetᮔ
ɲ
onsetᮑ
ŋ
onsetᮍ
codaᮀCoda.
w
onsetᮝ
r
onsetᮛ
medialᮢ
codaᮁ
l
onsetᮜ
medialᮣ
j
onsetᮚ
medialᮡ
Other features
Other letters
ᮺ is an archaic letter used for writing Sanskrit.
ᮺ
For reproduction of Old Sundanese writing there are 5 additional characters:
ᮻ,ᮼ,ᮽ,ᮾ,ᮿ
Encoding choices
This section offers advice about characters or character sequences to avoid, and what to use instead. It takes into account the relevance of Unicode Normalisation Form D (NFD) and Unicode Normalisation Form C (NFC). It also takes into account Unicode's Do Not Emit guidelines.
Although usage is recommended here, content authors may well be unaware of such recommendations. Therefore, applications should look out for the non-recommended approach and treat it the same as the recommended approach wherever possible.
Codepoint sequences
Combining marks always follow the based character.
Where present, characters in a syllable should always occur in the following order.u
A consonant or independent vowel.
Medial consonant, -ja, -ra, or -la.
Dependent vowel or vowel killer.
Coda.
A vowel-killer cannot be followed by a combining mark for a final consonant, nor can it be preceded by a medial consonant.
The pre-base vowel sign must also be typed and stored after the base; the rendering process will move the glyph to the appropriate location.
Numbers
Sundanese uses native digits, which are decimal-based and used in the same way as European numerals.
᮰,᮱,᮲,᮳,᮴,᮵,᮶,᮷,᮸,᮹
To help distinguish the digits from other characters | is used around numbers.
Glyph shaping is required for subjoined consonants in Old Sundanese, but doesn't appear to be needed for modern Sundanese orthography.
However, when two diacritics appear in the same position relative to the base character they are positioned side by side, as shown in fig_multiple_diacritics.
Multiple combining marks alongside the same base character sit side by side.
Observation: Everson says that the same applies for ᮊᮢᮥ, but the fonts I've tried all render that combination vertically.
For Old Sundanese orthography, positioning rules are also needed to produce conjunct forms.
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
tbd
Punctuation & inline features
Phrase & section boundaries
Modern Sundanese typically uses ASCII punctuation for sentence and phrase punctuation.
phrase
,
;
:
sentence
.
?
!
Old Sundanese
The punctuation described here is used for Old Sundanese texts, and is not used for modern Sundanese.
phrase
In Old Sundanese, if ᳀ is used as a full stop, ᳂ is used as a comma.
Otherwise ᳃ may be used as a comma in older texts.
sentence
᳀ may be used in Old Sundanese texts.
Religious texts in Old Sundanese contain ᳆᳀᳆ and ᳆᳁ markers, which include additional code points ᳆, and ᳁.
Historical texts in Old Sundanese contain ᳅᳂᳅ markers, with the additional code point ᳅.
Other similar code points include ᳄ and ᳇.
Bracketed text
Sundanese commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Quotations & citations
Sundanese texts use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
“
”
nested
‘
’
Line & paragraph layout
Line breaking
tbd
No information about whether lines break after syllables or space-separated words.
In-word line-breaking
According to Everson, hyphenation can occur after any full orthographic syllable, but there are no details about how that works.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for some of the characters used in modern Sundanese. Context may affect the behaviour of some of these and other characters.
Click/tap on the characters to show what they are.
“ ‘ ( should not be the last character on a line.
” ’ ) . , ; ! ? % should not begin a new line.
Baselines, line height, etc.
Sundanese uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
Most Sundanese letters are of a uniform height, but Sundanese places vowel marks and final characters above and below base characters. If the latter occur together, they are typically placed side by side, rather than extending away from the baseline.
To give an approximate idea, fig_baselines compares Latin and Sundanese glyphs from the Noto font. The basic height of Sundanese letters is typically around the Latin cap-height, and combining marks below fit pretty much within the Latin descender height, however combining marks reach above the Latin ascenders, creating a need for larger line spacing.
Font metrics for Latin text compared with Sundanese glyphs in the Noto Sans Sundanese font.