This page brings together basic information about the Hanifi Rohingya script and its use for the Rohingya language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Rohingya using Unicode.
Hanifi Rohingya is one of four scripts used for writing the Rohingya language, spoken by about 1,500,000 people, mostly in Myanmar, but also in significant Rohingya-speaking refugee communities in Bangladesh and Thailand.
The other scripts are Arabic, Latin (called Rohingyalish), and Myanmar.
Hanifi Rohingya is actively used in newspapers and books and on the Web. The inventor estimates that around 50 Rohingya community Schools in Bangladesh refugee camps are teaching Hanifi Rohingya, and another 2,000 are learning in Malaysia and Saudi Arabia. There are also a number of web sites and apps dedicated to the script.
𐴌𐴟𐴇𐴥𐴝𐴚𐴒𐴙𐴝ɾuh²aŋgiaruˈhɪŋdʒaRohingya
For over 200 years, the Rohingya language has been written in Arabic script, using several orthographies, one of which was developed in 1975, but didn't gain much traction. The Latin orthography. called Rohingyalish or Rohingya Fonna, was developed in 1999 in order to make it easier to write Rohingya on computers.
Around 1960, scholars began to see a need for a completely new writing system that was tailored closely to the needs of the language and that provided a focus point for Rohingya culture. In the 1980s this lead to the development of the Hanifi Rohingya script by Mohammad Hanif and his colleagues.
The Hanifi Rohingya script is an alphabet, ie. all vowels are written explicitly, alongside consonants; there is no inherent vowel in a consonant (abugidas), certain vowels are not systematically dropped (abjads), and consonant and vowel are not combined in the same character (syllabaries).
Hanifi Rohingya is mostly a simple and largely phonetic orthography, clearly modelled on Arabic script, and yet with significant differences.
Observation: Also, it seems possible to repeat a vowel to lengthen a sound, eg.
𐴈𐴡𐴀𐴡xoʔoxo:
Nasalisation
Nasalised vowels are indicated by writing 𐴣 after the vowel.
eg.
𐴔𐴦𐴝𐴣𐴈𐴝𐴣𐴓𐴞
Standalone vowels
A standalone vowel at the beginning of a word is always preceded by 𐴀, which acts as a vowel carrier.
eg.
𐴀𐴝𐴣𐴍𐴥𐴝𐴓𐴞𐴀𐴦𐴟𐴘
Similarly, in a sequence of vowels inside a word, the non-initial vowels are preceded by the carrier.
eg.
𐴅𐴝𐴕𐴟𐴀𐴝𐴌𐴞
When 𐴀 occurs without a following vowel letter at the beginning or in the middle of a word, it represents the vowel ɔ.
eg.
𐴁𐴡𐴀𐴌 𐴉𐴝𐴃𐴝
Tones
Rohingya has 3 tones. They indicate stress and vowel length, and are indicated in writing using dedicated combining characters, as follows.
short and high, 10D24
long and falling, 10D25
long and rising, 10D26
These usually appear above the consonant in a syllable, however in some fonts the mark drifts to the left, so that it appears between the consonant and the vowel.
eg.
𐴁𐴤𐴝ba¹ba𐴁𐴥𐴝ba²ba𐴁𐴦𐴝ba³ba
Observation: In order to achieve the best positioning using the Noto Sans Hanifi Rohingya and the Rohingya Noories One fonts, it is necessary to type the tone mark after the consonant (rather than after the vowel, as suggested in Pandey's script proposal).
When both 10D27 and a tone mark appear together, it is important to type in and store both in the correct order for display. The tassi is typed and stored first,u§684.
eg.
𐴔𐴡𐴙𐴅𐴧𐴤𐴙𐴠𐴊𐴠moiɟ&¹iede
These diacritics may appear side-by-side, with the tone mark to the left, when they occur together.u§684
Vowel sounds to characters
This section maps Rohingya vowel sounds to common graphemes in the Hanifi Rohingya orthography.
Graphemes are labelled as either dependent (post-consonant) vowels or standalone vowels.
Plain vowels
i
dependent𐴞
standalone𐴀𐴞
ĩ
dependent𐴞𐴣
u
dependent𐴟
standalone𐴀𐴟
ũ
dependent𐴟𐴣
e
dependent𐴠
standalone𐴀𐴠
ẽ
dependent𐴠𐴣
o
dependent𐴡
standalone𐴀𐴡
õ
dependent𐴡𐴣
ɔ
standalone𐴀when used without a following.
a
dependent𐴝
standalone𐴀𐴝
ã
dependent𐴝𐴣
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Since this is an alphabet, the absence of vowel sounds in consonant clusters or after codas is marked simply by an absence of vowel letters. There is no special shaping or mark to indicate a consonant cluster. For example:
eg.
𐴑𐴡𐴔𐴂𐴘𐴟𐴄𐴝𐴌
𐴑,𐴡,𐴔,𐴂,𐴘,𐴟,𐴄,𐴝,𐴌
More examples:
eg.
𐴑𐴟𐴌𐴥𐴏𐴞
𐴀𐴞𐴏𐴃𐴞𐴌𐴞
Sakin
At the end of a word, or when just the consonant is written alone, 𐴢 is used after some consonants when there is no following vowel.
Consonants that typically take the sakin include the following:
𐴂𐴢,𐴁𐴢,𐴃𐴢,𐴊𐴢,𐴄𐴢,𐴒𐴢,𐴉𐴢,𐴏𐴢,𐴐𐴢,𐴈𐴢,𐴇𐴢,𐴖𐴢,𐴗𐴢,𐴓𐴢,𐴙𐴢
And those that don't:
𐴋,𐴆,𐴅,𐴑,𐴎,𐴔,𐴕,𐴛,𐴚,𐴌,𐴍
However, these rules are not hard and fast. For example, m may be written either way (see the example of 'turnip' below).
eg.
𐴇𐴥𐴝𐴙𐴓𐴢𐴐𐴥𐴝𐴓𐴒𐴡𐴔𐴢𐴄𐴝𐴘𐴧𐴡𐴕𐴋𐴥𐴠𐴙𐴇𐴝𐴑
Consonants
𐴂,𐴁,𐴃,𐴊,𐴄,𐴋,𐴆,𐴅,𐴑,𐴒
𐴉,𐴖,𐴏,𐴜,𐴎,𐴐,𐴈,𐴇
𐴔,𐴕,𐴛,𐴚
𐴖,𐴗,𐴌,𐴍,𐴓,𐴘,𐴙
Consonant letters
These are the basic consonant letters in Rohingya.
Click on each letter for more details and for examples of usage.
Some people have used 𐴜 to represent the sound v, although it was not formally approved as part of the script. The normal letter to use for both w and v is 𐴖.
Gemination
Geminated consonant sounds are indicated using 10D27, which is typed immediately after the consonant and before any following vowel, and which is rendered above the consonant letter, eg. compare the z sounds in the following.
eg.
𐴎𐴥𐴞𐴘𐴡𐴎𐴧𐴝𐴔𐴝𐴘
Consonant sounds to characters
This section maps Rohingya consonant sounds to common graphemes in the Hanifi Rohingya orthography.
The right-hand column shows joining forms for the letter.
p
10D0210D0210D0210D02consonant𐴂
b
10D0110D0110D0110D01consonant𐴁
t
10D0310D0310D0310D03consonant𐴃
d
10D0A10D0A10D0A10D0Aconsonant𐴊
ʈ
10D0410D0410D0410D04consonant𐴄
ɖ
10D0B10D0B10D0B10D0Bconsonant𐴋
c
10D0610D0610D0610D06consonant𐴆
ɟ
10D0510D0510D0510D05consonant𐴅
k
10D1110D1110D1110D11consonant𐴑
ɡ
10D1210D1210D1210D12consonant𐴒
f
10D0910D0910D0910D09consonant𐴉
v
10D1610D1610D1610D16consonant𐴖
s
10D0F10D0F10D0F10D0Fconsonant𐴏
z
10D0E10D0E10D0E10D0Econsonant𐴎
ʃ
10D1010D1010D1010D10consonant𐴐
x
10D0810D0810D0810D08consonant𐴈
h
10D0710D0710D0710D07consonant𐴇
m
10D1410D1410D1410D14consonant𐴔
n
10D1510D1510D1510D15consonant𐴕
ɲ
10D1B10D1B10D1B10D1Bconsonant𐴛
ŋ
10D1A10D1A10D1A10D1Aconsonant𐴚
w
10D1610D1610D1610D16consonant𐴖
10D1710D1710D1710D17semivowel𐴗Semivowel.
ɾ
10D0C10D0C10D0C10D0Cconsonant𐴌
ɽ
10D0D10D0D10D0D10D0Dconsonant𐴍
l
10D1310D1310D1310D13consonant𐴓
j
10D1810D1810D1810D18consonant𐴘
10D1910D1910D1910D19semivowel𐴙Semivowel.
Numbers
Digits
Hanifi Rohingya has a set of native digits
𐴰,𐴱,𐴲,𐴳,𐴴,𐴵,𐴶,𐴷,𐴸,𐴹
Numbers are written left-to-right within the overall right-to-left flow.
Text direction
Hanifi Rohingya text is written horizontally and right-to-left in the main but, as in most right-to-left scripts, numbers and embedded text in other scripts are written left-to-right (producing 'bidirectional' text).
Rohingya words are read right-to-left, starting from the right of this line, but numbers (highlighted) and Latin text are read left-to-right.
The Unicode Bidirectional Algorithm automatically takes care of the ordering for all the text in fig_bidi, as long as the 'base direction' is set to RTL. In HTML this can be set using the dir attribute, or in plain text using formatting controls.
For authoring HTML pages, one of the most important things to remember is to use <html dir="rtl" … > at the top of the page. Also, use markup to manage direction, and do not use CSS styling.
Managing text direction
Unicode provides a set of 10 formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction of a range of characters. RLE/LRE comes at the start, and PDF at the end of a range of characters for which the base direction is to be set.
In Unicode 6.1, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2066 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
061C (ALM) is used to produce correct sequencing of numeric data. Follow the link and see expressions for details.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
Hanifi Rohingya is cursive, ie. letters in a word are joined up.
Nearly all letters join on both sides. 𐴢 joins only to the right. And 𐴀 joins only to the left, which is very unusual. Fonts automatically produce the appropriate joining form for a code point, according to its visual context.
Cursive connections in the word 𐴃𐴞𐴕𐴑𐴟𐴙𐴕𐴧𐴝 𐴐𐴡𐴑𐴥𐴡𐴓𐴢.
The cursive treatment produces only minor changes to glyph shapes in most cases, other than extensions to the baseline. 𐴔 is an exception, with different final and medial/initial shapes (see fig_joining_forms).
There is a style of font which behaves slightly differently, and appears to be quite commonly used. fig_cursive_triangle_noories shows an example. Note how the n doesn't join to the right, and the o falls short of the l. The glyphs in this font don't have joining strokes to the right, and taper off and barely touch (if they do) to the left.
Cursive connections in the same word as in fig_cursive_triangle using the Rohingya Noories One font.
The following tables show all joining forms.
isolated
right-joined
dual-join
left-joined
joining groups
𐴂
ـ𐴂
ـ𐴂ـ
𐴂ـ
𐴂,𐴉,𐴜
𐴁
ـ𐴁
ـ𐴁ـ
𐴁ـ
𐴁
𐴃
ـ𐴃
ـ𐴃ـ
𐴃ـ
𐴃
𐴊
ـ𐴊
ـ𐴊ـ
𐴊ـ
𐴊
𐴄
ـ𐴄
ـ𐴄ـ
𐴄ـ
𐴄
𐴋
ـ𐴋
ـ𐴋ـ
𐴋ـ
𐴋
𐴆
ـ𐴆
ـ𐴆ـ
𐴆ـ
𐴆
𐴅
ـ𐴅
ـ𐴅ـ
𐴅ـ
𐴅
𐴑
ـ𐴑
ـ𐴑ـ
𐴑ـ
𐴑
𐴒
ـ𐴒
ـ𐴒ـ
𐴒ـ
𐴒
𐴏
ـ𐴏
ـ𐴏ـ
𐴏ـ
𐴏
𐴎
ـ𐴎
ـ𐴎ـ
𐴎ـ
𐴎
𐴐
ـ𐴐
ـ𐴐ـ
𐴐ـ
𐴐
𐴈
ـ𐴈
ـ𐴈ـ
𐴈ـ
𐴈
𐴇
ـ𐴇
ـ𐴇ـ
𐴇ـ
𐴇
𐴔
ـ𐴔
ـ𐴔ـ
𐴔ـ
𐴔
𐴕
ـ𐴕
ـ𐴕ـ
𐴕ـ
𐴕
𐴛
ـ𐴛
ـ𐴛ـ
𐴛ـ
𐴛
𐴚
ـ𐴚
ـ𐴚ـ
𐴚ـ
𐴚
𐴖
ـ𐴖
ـ𐴖ـ
𐴖ـ
𐴖
𐴗
ـ𐴗
ـ𐴗ـ
𐴗ـ
𐴗
𐴌
ـ𐴌
ـ𐴌ـ
𐴌ـ
𐴌
𐴍
ـ𐴍
ـ𐴍ـ
𐴍ـ
𐴍
𐴓
ـ𐴓
ـ𐴓ـ
𐴓ـ
𐴓
𐴘
ـ𐴘
ـ𐴘ـ
𐴘ـ
𐴘
𐴙
ـ𐴙
ـ𐴙ـ
𐴙ـ
𐴙,𐴣,𐴞,𐴠
𐴟
ـ𐴟
ـ𐴟ـ
𐴟ـ
𐴟
𐴡
ـ𐴡
ـ𐴡ـ
𐴡ـ
𐴡
𐴝
ـ𐴝
ـ𐴝ـ
𐴝ـ
𐴝
𐴢
ـ𐴢
ـ𐴢ـ
𐴢ـ
𐴢
Joining forms for shapes that join on both sides. Those showing significant shape change are highlighted.
isolated
left-joined
letters
𐴀
𐴀ـ
𐴀
Joining forms for the shape that joins on the left only.
isolated
right-joined
letters
𐴢
ـ𐴢
𐴢
Joining forms for the shape that joins on the right only.
Context-based shaping
tbd
See just above for shaping related to cursive joining.
Typographic units
Word boundaries
Words are separated by spaces.
Graphemes
tbd
Punctuation & inline features
Phrase & section boundaries
Rohingya uses a mixture of Arabic and ASCII punctuation, and may also use Myanmar signs.
phrase
،
؛
:
sentence
۔
.
؟
!
Observation: It seems to be standard practise to separate the punctuation from the foregoing text with a space.
Observation: Two online sites use punctuation that looks like the Burmese section marks, ၊ and ။, except that they use different characters. One uses a single or double 𐴱 [U+10D31 HANIFI ROHINGYA DIGIT ONE], the other uses | [U+007C VERTICAL LINE] or |𐴱 [U+007C VERTICAL LINE + U+10D31 HANIFI ROHINGYA DIGIT ONE]. (The page from which the example in fig_section_signs is taken also uses other strange punctuation choices, such as the Arabic thousands separator instead of the Arabic comma, that can be seen in the bottom line of the example.)
An example of a page using an approximation of Myanmar section signs for punctuation. (The text has been right-aligned to make the example simpler. The original lacks directional markup.)
Bracketed text
Rohingya commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Mirrored characters
It is important to note that the Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use >U+003E GREATER-THAN SIGN, but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some of the more common ones used for Rohingya.
(,),<,>,[,],{,}
Quotations & citations
Rohingya texts use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks. Note, however, that the order of use is different from that in LTR text, because they are not automatically mirrored.
start
end
initial
“
”
nested
‘
’
Unlike the bracketing quotation marks, these characters are not mirrored during display. This means that LEFT means use on the left, and RIGHT means use on the right.
Line & paragraph layout
Line breaking & hyphenation
tbd
Observation: Lines appear to be broken at word boundaries.
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines from top to bottom.
Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
Text alignment & justification
Examples of printed matter show full justification. A baseline extension is frequently used to stretch words in order to achieve flush lines (see fig_justification).
Example of full justification, with the word at the end of the 3rd line from the bottom also showing signs of being stretched.
Pandey recommends using ـ for this.p§12 However, it should be noted that the tatweel character is only useful if the text is static. If window resizing or inserted text cause the line breaks to appear between different words, the tatweels will end up in the wrong place.
Baselines, line height, etc.
tbd
Rohingya uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
Counters, lists, etc.
You can experiment with counter styles using the Counter styles converter. Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
Hanifi Rohingya uses numeric counters.
Numeric
The numeric style is decimal-based and uses these digits.
𐴱,𐴲,𐴳,𐴴,𐴵,𐴶,𐴷,𐴸,𐴹,𐴰
eg.
𐴲,𐴳,𐴴,𐴵,𐴶,𐴲𐴲,𐴳𐴳,𐴴𐴴,𐴵𐴵,𐴲𐴲𐴲,𐴳𐴳𐴳,𐴴𐴴𐴴,𐴵𐴵𐴵
Prefixes and suffixes
Observation: Further examples are needed to clarify the standard prefix and/or suffix for lists. The examples in fig_counters show circled numbers followed by a hyphen, and numbers followed by an equals sign.
Examples of counters in Rohingya.
Page & book layout
General page layout & progression
Arabic books, magazines, etc., are bound on the right-hand side, and pages progress from right to left.
Binding configuration for Arabic books, magazines, etc.
Columns are vertical but run right-to-left across the page.







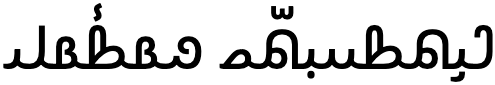


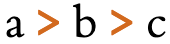
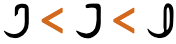
. In https://www.unicode.org/L2/L2016/16311-hanifi-rohingya.pdf p38.")


