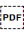 U+202C POP DIRECTIONAL FORMATTING (PDF).
U+202C POP DIRECTIONAL FORMATTING (PDF).Originally designed for hot metal typesetting as a space that is approximately 0.5 em wide. In digital text, the size is fixed by the font, and does not normally increase in size during justification. Canonically equivalent to 2002.
`, // M Quad space '\u{2001}': `Originally designed for hot metal typesetting as a space that is approximately 1 em wide. In digital text, the size is fixed by the font, and does not normally increase in size during justification. Canonically equivalent to 2003.
`, '\u{2002}': `Provides a space that is approximately 0.5 em wide. Does not increase in size during justification.
`, '\u{2003}': `Provides a space that is approximately 1 em wide.
Some content authors using Southeast Asian orthographies, such as Thai and Khmer, may use this character to produce a wider space between sentences than around phrases (since there is no sentence-final punctuation). Does not increase in size during justification.
`, // 3/M space '\u{2004}': `Originally designed for hot metal typesetting as a space that is approximately 0.3 em wide. In digital text, the size is fixed by the font, and does not normally increase in size during justification.
`, // 4/M space '\u{2005}': `Originally designed for hot metal typesetting as a space that is approximately 0.25 em wide. In digital text, the size is fixed by the font, and does not normally increase in size during justification.
`, // 6/M space '\u{2006}': `Originally designed for hot metal typesetting as a space that is approximately 1/6th em wide. In digital text, the size is fixed by the font, and does not normally increase in size during justification.
`, // fig space '\u{2007}': `Has a fixed width known as tabular width, which is the same width as digits used in tables. Does not increase in size during justification.u16,#G1834
`, // punctuation space '\u{2008}': `Defined to be the same width as a period. Does not increase in size during justification.u16,#G1834
`, // thin space '\u{2009}': `Used for narrow word gaps and for justification of type. Slightly larger than 200A. Sometimes gets expanded during justification, unlike the other fixed width spaces.u16,#G1834
`, // hair space '\u{200A}': `Used for narrow word gaps and for justification of type. Slightly smaller than 2009. Does not increase in size during justification.u16,#G1834
`, // zwsp '\u{200B}': `An invisible character, used to signal line-break and word-break opportunities. It was originally provided for use with writing systems such as Thai, Myanmar, Khmer, Japanese, etc. that don't use spaces between words.
Justification adjusts the gap between the characters on either side of the ZWSP as if the ZWSP wasn't there§,827, eg. the two lines below show Thai text containing a ZWSP after the 4th base character. The first is rendered as per normal, the second is as it would appear with justification or letter-spacing. Note how the second line has no extra spacing where the ZWSP occurs.
อักษรไทย
อั ก ษ ร ไ ท ย
`, // zwnj '\u{200C}': `Prevents two adjacent letters forming a cursive connection with each other when rendered. Especially useful for educational illustrations, but also has some real-world applications.
Also used with complex scripts to manage the visual representation of glyphs that normally interact, eg. to form conjuncts, position diacritics, etc.
Examples:
Persian
The ZWNJ is used in Persian for plural suffixes, some proper names, and Ottoman Turkish vowels. Ignoring or removing the ZWNJ will result in text with a different meaning or meaningless text. For example, تنها is the plural of body, whereas تنها is the adjective alone. The only difference is the presence or absence of ZWNJ after noon. u373 g
Khmer
Khmer register shifters (ie. ◌៉ [U+17C9 KHMER SIGN MUUSIKATOAN] or ◌៊ [U+17CA KHMER SIGN TRIISAP]) usually appear above a consonant. However, if a superscript vowel is also attached to the consonant, the shifter is normally displayed below the consonant, instead. If you want to force the shifter to remain above the consonant, as is occasionally the case, insert ZWNJ between the consonant and the shifter.u373 sk ហ ហ៊ ហ៊ី ហ៊ី
Hindi
The ZWNJ can be used to prevent the formation of conjuncts, eg. क्क → क्क क्ष → क्ष
Permits a letter to form a cursive connection without a visible neighbour. Especially useful for educational illustrations, but also has some real-world applications.
Also used with complex scripts to manage the visual representation of glyphs that normally interact, eg. to form conjuncts, position diacritics, etc.
Examples:
Arabic
The marker for hijri dates is an initial form of heh, even though it doesn't join to the left, ie. ه. For this, use a U+200D ZERO WIDTH JOINER immediately after the heh, eg. الاثنين 10 رجب 1415 ه..
In some cases ـ [U+0640 ARABIC TATWEEL] is used to ensure that the shape looks right, because some applications or fonts don't produce the right effect when using the ZWJ, eg. الاثنين 10 رجب 1415 هـ..
Hindi
The ZWJ can be used to make a conjunct that usually forms a ligature use half-forms instead, eg. क्ष → क्ष
An invisible character with strong LTR directional properties that can be used to produce the correct ordering of text, especially where there is a risk of spillover effects while the Unicode Bidirectional Algorithm is at work.
Generally referred to as LRM.
`, // RLM '\u{200F}': `An invisible character with strong RTL directional properties that can be used to produce the correct ordering of text, especially where there is a risk of spillover effects while the Unicode Bidirectional Algorithm is at work.
Generally referred to as RLM.
`, '\u{2010}': `This hyphen is rendered with a narrow width, and used in words such as 'left-to-right'.u16,#G6120
When typesetting text, this character is preferred, rather than U+002D HYPHEN-MINUS (which has ambiguous semantic value and rendered with an average width).u16,#G6120
`, '\u{2011}': `Has the same semantics as U+2010 HYPHEN except that it prevents line breaks around it. This hyphen is rendered with a narrow width, and used in words such as 'left-to-right'.u16,#G6120
`, '\u{2012}': `Has the same ambiguous semantics as U+002D HYPHEN-MINUS but has the same width as monospaced digits.u16,#G6120
`, '\u{2013}': `Used to indicate a range of values, such as 2002–2025.u16,#G6120
It is also used by some typographers to make a break – like this – and when used this way it usually has spaces either side.
Note, however, that in Hebrew, using this rather than U+002D HYPHEN-MINUS to write a range results in the numbers in the range being read right to left, rather than the normal left to right, eg.
ספרה 23–24 ספרה
`, '\u{2014}': `Used to make a break—like this—in which case it usually has no spaces either side (unlike – U+2013 EN DASH). In typewriter text this is oftn represented by a double hyphen.u16,#G6120
Authors of Chinese text may use two of these characters, side-by-side, to indicate a break, but nowadays ⸺ U+2E3A TWO-EM DASH is recommended, instead.
In older mathematical typography this may be used to indicate a binary minus sign.u16,#G6120
`, '\u{2015}': `Introduces quoted text in some typographic styles.u16,#G6120
`, '\u{2016}': `Called double bar.b
An old standard reference mark used with footnotes. When used for this purpose with other signs, the traditional order is * † ‡ § ‖ ¶.b
Also used as a standard symbol for bibliographic work.b
`, '\u{2019}': `This is the preferred default for a punctuation apostrophe (avoiding the ambiguity of ' U+0027 APOSTROPHE), eg. in contractions such as "We’ve been here before."u16,#G6120
If surrounded by text or digits on both sides, this should not constitute a line-break opportunity.u16,#G6120
Where the apostrophe is to represent a modifier letter (for example, in transliterations to indicate a glottal stop), a letter apostrophe is used. The code point for that is ʼ U+02BC MODIFIER LETTER APOSTROPHE.u16,#G6120 That code point is used, for example, for many languages as a letter of their alphabets, as a tone marker in Bodo and Dogri, and to indicate vowel elongation, or various truncations and ellipsis in Maithili.
Called dagger, but also known as obelisk, obelus, or long cross.b321
A reference mark, used primarily with footnotes. When used for this purpose with other signs, the traditional order is * † ‡ § ‖ ¶.b68
Also a death sign in European typography, used to mark the year of death or the names of dead persons.b321
In lexicography it marks obsolete forms, and in editing of classical texts flags passages judged to be corrupt.b321
`, '\u{2021}': `Called dagger, but also known as diesis, or double obelisk.b321
A reference mark used with footnotes. When used for this purpose with other signs, the traditional order is * † ‡ § ‖ ¶.b68
`, '\u{2024}': `Used in Armenia like a semicolon, eg.
Հայկական Բարձրաւանդակ․ նկարուած հարաւային Կովկասի արբանեակէն Armenian Highlands; satellite image of the southern Caucasus
It can also be used with 2025 to construct dot leaders in plain text, when the application doesn't generate them automatically. This character allows for fine-tuning of the dot leader sequence length.u16,#G13727 (Note that this only works when the page width is fixed.) For example:
Chapter 1‥‥‥‥‥‥‥‥․2
`, '\u{2025}': `Dot leaders that connect things like chapter titles with page numbers are often generated automatically by an application. If they are not, this and 2024 can be used to construct them.u16,#G13727 (Note that this only works when the page width is fixed.) For example:
Chapter 1‥‥‥‥‥‥‥‥․2
`, '\u{2026}': `A convenient alternative to writing ellipsis with 3 consecutive full stops. This makes it easy to ensure that the ellipsis is not broken across a line, but the spacing of the dots in the ellipsis glyph may need to change based on the language.u16,#G13586
In CJK texts, it is normal to express ellipsis using this character twice (making 6 dots). When used that way, a line should not normally be broken between the 2 code points. CJK ellipsis is usually vertically centred in horizontal text and horizontally centred in vertical text. The dots are evenly spread across the 2em width. CJK fonts tend to do this automatically when rendering this code point (although not all fonts do).
The following is an example of Korean usage:
그는 최선을 다했다. 그러나 성공할지는…… He did his best. But if he succeeds...
⋯ U+22EF MIDLINE HORIZONTAL ELLIPSIS may be substituted for this character in order to make the dots appear centred in the line, but this is really a mathematical symbol. Neither CLReq nor JLReq mention the use of that character.
There is also a presentation form aimed at vertical text, ︙ U+FE19 PRESENTATION FORM FOR VERTICAL HORIZONTAL ELLIPSIS, which maps to the GB 18030 Chinese standard, but as for most presentation forms, fonts should render the text appropriately so that it is not needed. There is also another mathematical symbol, ⋮ U+22EE VERTICAL ELLIPSIS, which looks similar, but the Unicode Standard recommends that, if the font doesn't automatically render U+2026 as needed, then U+FE19 is a better choice.
Mongolian, which is normally written vertically, has its own, 4-dot ellipsis code point, ᠁ U+1801 MONGOLIAN ELLIPSIS.
Do not confuse this character with ⁝ U+205D TRICOLON, which is used as a word or phrase delimiter.
A raised dot used in dictionaries to indicate word-break opportunities, eg. “dic‧tio‧nary”.u16,#G20622
It should not be confused with · U+00B7 MIDDLE DOT.u16,#G20622
The Unicode Standardu16,#G746543 has a table illustrating the use of this and other methods for indicating word-breaks in a selection of dictionaries.
`, // LRE '\u{202A}': `Sets the start point for a range of inline text when applying a base direction of left-to-right. The range is terminated by U+202C POP DIRECTIONAL FORMATTING (PDF).
You should use 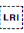 U+2066 LEFT-TO-RIGHT ISOLATE (LRI) rather than this character.
U+2066 LEFT-TO-RIGHT ISOLATE (LRI) rather than this character.
Sets the start point for a range of inline text when applying a base direction of right-to-left. The range is terminated by 202C (PDF).
You should use 2067 (RLI) rather than this character.
`, // PDF '\u{202C}': `Sets the end point for a range of inline text when applying a base direction. The range is started with either 202A (LRE) or 202B (RLE).
You should use 2069 (PDI) and its associated range starters rather than this character.
`, '\u{202F}': `Many Mongolian suffixes are separated from the root or other suffixes by a gap that is smaller than a normal space. Characters following this gap may take on special shapes, and lines should not be broken at this gap. For example:
ᠭᠠᠵᠠᠷ ᠠ gaǰar-a to the country
This character was initially added to Unicode for Mongolian suffix handling, but in Unicode 16 a decision was taken to use U+180E MONGOLIAN VOWEL SEPARATOR instead for this purpose.
A somewhat recent innovation in writing Cree syllabics is to use this as a morpheme separator, rather than the hyphen which is used in the Latin transcription, eg. ᐁ ᐚᐸᒫᐟ ê-wâpamât
Also useful in Latin script languages where a thin, non-breaking space is needed:
Abbreviation for feet (1′ = 12″).b330
Also used for minutes of arc (eg. 60′=1°).b330
`, '\u{2033}': `Abbreviation for inches (1′ = 12″).b321
Also used for seconds of arc (eg. 360″=1°).b321
`, '\u{203C}': `Encoded for convenience when working with vertical text in East Asian or Mongolian scripts.u16,#G5491
It has a compatibility decomposition to a sequence of 2 code points.
`, '\u{203E}': `Can be used to create a high line, corresponding to _ U+005F LOW LINE. A sequence of these characters should create an unbroken line.u16,#G2006
This is distinct from the following: ̅ U+0305 COMBINING OVERLINE, and ̄ U+0304 COMBINING MACRON.
A proofreading mark indicating a location where something should be inserted.u16,#G14769
`, '\u{2044}': `A fraction slash to be used between digits. Fonts may convert the sequence to a single typographic unit, such as in the following examples:u16,#G2001
1⁄4 1⁄2 3⁄4
`, '\u{2047}': `Encoded for convenience when working with vertical text in East Asian or Mongolian scripts.u16,#G5491
It has a compatibility decomposition to a sequence of 2 code points.
`, '\u{2048}': `Encoded for convenience when working with vertical text in East Asian or Mongolian scripts.u16,#G5491
It has a compatibility decomposition to a sequence of 2 code points.
`, '\u{2049}': `Encoded for convenience when working with vertical text in East Asian or Mongolian scripts.u16,#G5491
It has a compatibility decomposition to a sequence of 2 code points.
`, '\u{204A}': `Used in Old English or Irish Gaelic in the same way as a modern ampersand (&), but may also be used as a letter in some contexts.u16,#G28551
In some medieval materials an uppercase form appears. This can be represented using ⹒ U+2E52 TIRONIAN SIGN CAPITAL ET, however note that these two are not case-mapped in Unicode.u16,#G28551
A common alternative to ¶ U+00B6 PILCROW SIGN. The pilcrow characters and § U+00A7 SECTION SIGN are used to indicate sections or paragraphs, in editorial markup, to show format modes, etc. Which character is used is dictated by convention.u16,#G4247
Used as a minus sign in commercial or tax-related forms or publications in several European countries, including Germany and Scandinavia. Can also be written as the sequence ./. U+002E FULL STOP + U+002F SOLIDUS + U+002E FULL STOP.u16,#G7935
In European countries such as Finland, this character and ✓ U+2713 CHECK MARK are used in marking student work to indicate 'correct' and 'incorrect', respectively.u16,#G7935
Also used as a marginal note in letters to indicate enclosures, and in the Uralic Phonetic Alphabet to indicate a structurally related borrowed element of different pronunciation.u16,#G7935
`, // swung dash '\u{2053}': `Used in dictionaries to repeat the defined term in examples.u16,#G6120
`, '\u{2056}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
`, '\u{2058}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
`, '\u{2059}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
`, '\u{205A}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
`, '\u{205B}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
Also used by scribes in a margin to highlight text.u16,#G13108
`, '\u{205C}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
Also used by scribes in a margin to highlight text.u16,#G13108
`, '\u{205D}': `One character in a set of archaic punctuation characters used in common for ancient and medieval scripts. The specific function can vary by script.u16,#G13108
`, '\u{205E}': `Used in dictionaries to indicate syllable boundaries that are not suitable word-break opportunities, eg.u16,#G20622
a⁞plomb
hoar⁞y
To reinforce the idea that there should be no line break here, this character may be followed by 2060.u16,#G20622
See also 2027.
`, '\u{2060}': `An invisible character, equivalent to a zero-width no-break space, and used to prevent line-breaks. It has no effect on word segmentation.
It can also be used to bracket other characters to turn them into non-breaking characters, such as U+2009 THIN SPACE or ― [U+2015 HORIZONTAL BAR].
Not to be confused with U+200D ZERO WIDTH JOINER or U+034F COMBINING GRAPHEME JOINER, since it has no effect on shaping.
This functionality is also provided by U+FEFF ZERO WIDTH NO-BREAK SPACE, but since that character also represents the byte-order mark, the use of this word joiner character (added in Unicode 3.2) is strongly preferred.
`, // LRI '\u{2066}': `Sets the start point for a range of inline text when applying a base direction of left-to-right, and isolates the text within that range from text outside it. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by 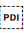 U+2069 POP DIRECTIONAL ISOLATE (PDI).
U+2069 POP DIRECTIONAL ISOLATE (PDI).
This character should be used rather than 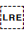 U+202A LEFT-TO-RIGHT EMBEDDING (LRE).
U+202A LEFT-TO-RIGHT EMBEDDING (LRE).
Sets the start point for a range of inline text when applying a base direction of right-to-left, and isolates the text within that range from text outside it. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
This character should be used rather than 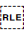 U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
Sets the start point for a range of inline text when applying a base direction, and isolates the text within that range from text outside it. The base direction set is determined by that of the first strong directional character in the range. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
Sets the end point for a range of inline text when applying a base direction. The range is started with either U+2066 LEFT-TO-RIGHT ISOLATE (LRI), 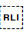 U+2067 RIGHT-TO-LEFT ISOLATE (RLI) or
U+2067 RIGHT-TO-LEFT ISOLATE (RLI) or  U+2068 FIRST STRONG ISOLATE (FSI).
U+2068 FIRST STRONG ISOLATE (FSI).
This character should be used rather than U+202C POP DIRECTIONAL FORMATTING (PDF).
Used in dictionaries to indicate certain morphological boundaries in West Asian linguistics.u16,#G9921
For similar-looking Fraktur hyphens use the normal hyphen characters with an appropriate font, rather than this character.u16,#G9921
`, '\u{2E31}': `Orthographies that separate words with a raised dot, such as Avestan or Samaritan, can use this word separator which is not script-specific. However, Runic has its own code point for the same purpose (᛫ U+16EB RUNIC SINGLE PUNCTUATION).u16,#G15382
Similar-looking code points with different semantics include: ⸳, ‧, and · U+00B7 MIDDLE DOT.