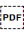 U+202C POP DIRECTIONAL FORMATTING (PDF).
U+202C POP DIRECTIONAL FORMATTING (PDF).`, '\u{2001}': `
`, '\u{2002}': `
`, '\u{2003}': `
Provides a space that is approximately 1 em wide.
Some content authors using Southeast Asian orthographies, such as Thai and Khmer, may use this character to produce a wider space between sentences than around phrases (since there is no sentence-final punctuation).
`, '\u{2004}': ``, '\u{2005}': `
`, '\u{2006}': `
`, '\u{2007}': `
`, '\u{2008}': `
`, '\u{2009}': `
`, '\u{200A}': `
`, // zwsp '\u{200B}': `
An invisible character, used to signal line-break and word-break opportunities. It was originally provided for use with writing systems such as Thai, Myanmar, Khmer, Japanese, etc. that don't use spaces between words.
Justification visibly adjusts the space between the characters on either side of the ZWSP as if the ZWSP wasn't there§,827, eg. the two lines below show Thai text containing a ZWSP after the 4th base character. The first is rendered as per normal, the second is as it would appear with justification or letter-spacing. Note how the second line has no extra spacing where the ZWSP occurs. อักษรไทย อั ก ษ ร ไ ท ย
`, // zwnj '\u{200C}': `ZWNJ
Prevents two adjacent letters forming a cursive connection with each other when rendered. Especially useful for educational illustrations, but also has some real-world applications.
Also used with complex scripts to manage the visual representation of glyphs that normally interact, eg. to form conjuncts, position diacritics, etc.
Examples:
Persian
The ZWNJ is used in Persian for plural suffixes, some proper names, and Ottoman Turkish vowels. Ignoring or removing the ZWNJ will result in text with a different meaning or meaningless text. For example, تنها is the plural of body, whereas تنها is the adjective alone. The only difference is the presence or absence of ZWNJ after noon. u373 g
Khmer
Khmer register shifters (ie. ◌៉ [U+17C9 KHMER SIGN MUUSIKATOAN] or ◌៊ [U+17CA KHMER SIGN TRIISAP]) usually appear above a consonant. However, if a superscript vowel is also attached to the consonant, the shifter is normally displayed below the consonant, instead. If you want to force the shifter to remain above the consonant, as is occasionally the case, insert ZWNJ between the consonant and the shifter.u373 sk ហ ហ៊ ហ៊ី ហ៊ី
Hindi
The ZWNJ can be used to prevent the formation of conjuncts, eg. क्क → क्क क्ष → क्ष
ZWJ
Permits a letter to form a cursive connection without a visible neighbour. Especially useful for educational illustrations, but also has some real-world applications.
Also used with complex scripts to manage the visual representation of glyphs that normally interact, eg. to form conjuncts, position diacritics, etc.
Examples:
Arabic
The marker for hijri dates is an initial form of heh, even though it doesn't join to the left, ie. ه. For this, use a U+200D ZERO WIDTH JOINER immediately after the heh, eg. الاثنين 10 رجب 1415 ه..
In some cases ـ [U+0640 ARABIC TATWEEL] is used to ensure that the shape looks right, because some applications or fonts don't produce the right effect when using the ZWJ, eg. الاثنين 10 رجب 1415 هـ..
Hindi
The ZWJ can be used to make a conjunct that usually forms a ligature use half-forms instead, eg. क्ष → क्ष
An invisible character with strong LTR directional properties that can be used to produce the correct ordering of text, especially where there is a risk of spillover effects while the Unicode Bidirectional Algorithm is at work.
Generally referred to as LRM.
`, // RLM '\u{200F}': `
An invisible character with strong RTL directional properties that can be used to produce the correct ordering of text, especially where there is a risk of spillover effects while the Unicode Bidirectional Algorithm is at work.
Generally referred to as RLM.
`, '\u{2010}': `‐
`, '\u{2011}': `‑
`, '\u{2012}': `‒
`, '\u{2013}': `–
`, '\u{2014}': `—
`, '\u{2015}': `―
`, '\u{2016}': `‖
Called double bar.b
An old standard reference mark used with footnotes. When used for this purpose with other signs, the traditional order is * † ‡ § ‖ ¶.b
Also used as a standard symbol for bibliographic work.b
`, '\u{2017}': `‗
`, '\u{2018}': `‘
`, '\u{2019}': `’
`, '\u{201A}': `‚
`, '\u{201B}': `‛
`, '\u{201C}': `“
`, '\u{201D}': `”
`, '\u{201E}': `„
`, '\u{201F}': `‟
`, '\u{2020}': `†
Called dagger, but also known as obelisk, obelus, or long cross.b321
A reference mark, used primarily with footnotes. When used for this purpose with other signs, the traditional order is * † ‡ § ‖ ¶.b68
Also a death sign in European typography, used to mark the year of death or the names of dead persons.b321
In lexicography it marks obsolete forms, and in editing of classical texts flags passages judged to be corrupt.b321
`, '\u{2021}': `‡
Called dagger, but also known as diesis, or double obelisk.b321
A reference mark used with footnotes. When used for this purpose with other signs, the traditional order is * † ‡ § ‖ ¶.b68
`, '\u{2022}': `•
`, '\u{2023}': `‣
`, '\u{2024}': `․
Armenian punctuation miǰakēt
Used like a semi-colon – a shorter break than a full stop. u322
Ոչ ոք չպետք է լինի ստրկության կամ անազատ վիճակում․ պետք է արգելվեն ստրկատիրության ու ստրուկների առուծախի բոլոր ձևերը։
‥
`, '\u{2026}': `…
`, '\u{2027}': `‧
`, '\u{2028}': ``, '\u{2029}': `
`, // LRE '\u{202A}': `
Sets the start point for a range of inline text when applying a base direction of left-to-right. The range is terminated by U+202C POP DIRECTIONAL FORMATTING (PDF).
You should use 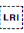 U+2066 LEFT-TO-RIGHT ISOLATE (LRI) rather than this character.
U+2066 LEFT-TO-RIGHT ISOLATE (LRI) rather than this character.
Sets the start point for a range of inline text when applying a base direction of right-to-left. The range is terminated by U+202C POP DIRECTIONAL FORMATTING (PDF).
You should use 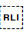 U+2067 RIGHT-TO-LEFT ISOLATE (RLI) rather than this character.
U+2067 RIGHT-TO-LEFT ISOLATE (RLI) rather than this character.
Sets the end point for a range of inline text when applying a base direction. The range is started with either 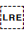 U+202A LEFT-TO-RIGHT EMBEDDING (LRE) or
U+202A LEFT-TO-RIGHT EMBEDDING (LRE) or 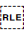 U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
You should use 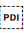 U+2069 POP DIRECTIONAL ISOLATE (PDI) and its associated range starters rather than this character.
U+2069 POP DIRECTIONAL ISOLATE (PDI) and its associated range starters rather than this character.
`, '\u{202E}': `
`, '\u{202F}': `
Initially added to Unicode for Mongolian suffix handling, where it is important to visually distinguish between spaces separating suffixes and those separating words, and where lines should not be broken between morphemes.
Many Mongolian suffixes are separated from the root or other suffixes by this small gap, eg. ᠭᠠᠵᠠᠷ ᠠ gaǰar-a to the country
Characters following NNBSP may take on special shapes.
A somewhat recent innovation in writing Cree syllabics is to use this as a morpheme separator, rather than the hyphen which is used in the Latin transcription, eg. ᐁ ᐚᐸᒫᐟ ê-wâpamât
Also useful in Latin script languages where a thin, non-breaking space is needed:
‰
`, '\u{2031}': `‱
`, '\u{2032}': `′
Abbreviation for feet (1′ = 12″).b330
Also used for minutes of arc (eg. 60′=1°).b330
`, '\u{2033}': `″
Abbreviation for inches (1′ = 12″).b321
Also used for seconds of arc (eg. 360″=1°).b321
`, '\u{2034}': `‴
`, '\u{2035}': `‵
`, '\u{2036}': `‶
`, '\u{2037}': `‷
`, '\u{2038}': `‸
`, '\u{2039}': `‹
`, '\u{203A}': `›
`, '\u{203B}': `※
`, '\u{203C}': `‼
`, '\u{203D}': `‽
`, '\u{203E}': `‾
`, '\u{203F}': `‿
`, '\u{2040}': `⁀
`, '\u{2041}': `⁁
`, '\u{2042}': `⁂
`, '\u{2043}': `⁃
`, '\u{2044}': `⁄
`, '\u{2045}': `⁅
`, '\u{2046}': `⁆
`, '\u{2047}': `⁇
`, '\u{2048}': `⁈
`, '\u{2049}': `⁉
`, '\u{204A}': `⁊
`, '\u{204B}': `⁋
`, '\u{204C}': `⁌
`, '\u{204D}': `⁍
`, '\u{204E}': `⁎
`, '\u{204F}': `⁏
`, '\u{2050}': `⁐
`, '\u{2051}': `⁑
`, '\u{2052}': `⁒
`, '\u{2053}': `⁓
`, '\u{2054}': `⁔
`, '\u{2055}': `⁕
`, '\u{2056}': `⁖
`, '\u{2057}': `⁗
`, '\u{2058}': `⁘
`, '\u{2059}': `⁙
`, '\u{205A}': `⁚
`, '\u{205B}': `⁛
`, '\u{205C}': `⁜
`, '\u{205D}': `⁝
`, '\u{205E}': `⁞
`, '\u{205F}': ``, '\u{2060}': `
WJ
An invisible character, equivalent to a zero-width no-break space, and used to prevent line-breaks. It has no effect on word segmentation.
It can also be used to bracket other characters to turn them into non-breaking characters, such as U+2009 THIN SPACE or ― [U+2015 HORIZONTAL BAR].
Not to be confused with U+200D ZERO WIDTH JOINER or U+034F COMBINING GRAPHEME JOINER, since it has no effect on shaping.
This functionality is also provided by U+FEFF ZERO WIDTH NO-BREAK SPACE, but since that character also represents the byte-order mark, the use of this word joiner character (added in Unicode 3.2) is strongly preferred.
`, '\u{2061}': `
`, '\u{2062}': `
`, '\u{2063}': `
`, '\u{2064}': `
`, // LRI '\u{2066}': `
Sets the start point for a range of inline text when applying a base direction of left-to-right, and isolates the text within that range from text outside it. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
This character should be used rather than U+202A LEFT-TO-RIGHT EMBEDDING (LRE).
Sets the start point for a range of inline text when applying a base direction of right-to-left, and isolates the text within that range from text outside it. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
This character should be used rather than U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
Sets the start point for a range of inline text when applying a base direction, and isolates the text within that range from text outside it. The base direction set is determined by that of the first strong directional character in the range. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
Sets the end point for a range of inline text when applying a base direction. The range is started with either U+2066 LEFT-TO-RIGHT ISOLATE (LRI), U+2067 RIGHT-TO-LEFT ISOLATE (RLI) or  U+2068 FIRST STRONG ISOLATE (FSI).
U+2068 FIRST STRONG ISOLATE (FSI).
This character should be used rather than U+202C POP DIRECTIONAL FORMATTING (PDF).
`, '\u{206B}': `
`, '\u{206C}': `
`, '\u{206D}': `
`, '\u{206E}': `
`, '\u{206F}': `
`, // SUPPLEMENTAL PUNCTUATION '\u{2E00}': `⸀
`, '\u{2E01}': `⸁
`, '\u{2E02}': `⸂
`, '\u{2E03}': `⸃
`, '\u{2E04}': `⸄
`, '\u{2E05}': `⸅
`, '\u{2E06}': `⸆
`, '\u{2E07}': `⸇
`, '\u{2E08}': `⸈
`, '\u{2E09}': `⸉
`, '\u{2E0A}': `⸊
`, '\u{2E0B}': `⸋
`, '\u{2E0C}': `⸌
`, '\u{2E0D}': `⸍
`, '\u{2E0E}': `⸎
`, '\u{2E0F}': `⸏
`, '\u{2E10}': `⸐
`, '\u{2E11}': `⸑
`, '\u{2E12}': `⸒
`, '\u{2E13}': `⸓
`, '\u{2E14}': `⸔
`, '\u{2E15}': `⸕
`, '\u{2E16}': `⸖
`, '\u{2E17}': `⸗
`, '\u{2E18}': `⸘
`, '\u{2E19}': `⸙
`, '\u{2E1A}': `⸚
`, '\u{2E1B}': `⸛
`, '\u{2E1C}': `⸜
`, '\u{2E1D}': `⸝
`, '\u{2E1E}': `⸞
`, '\u{2E1F}': `⸟
`, '\u{2E20}': `⸠
`, '\u{2E21}': `⸡
`, '\u{2E22}': `⸢
`, '\u{2E23}': `⸣
`, '\u{2E24}': `⸤
`, '\u{2E25}': `⸥
`, '\u{2E26}': `⸦
`, '\u{2E27}': `⸧
`, '\u{2E28}': `⸨
`, '\u{2E29}': `⸩
`, '\u{2E2A}': `⸪
`, '\u{2E2B}': `⸫
`, '\u{2E2C}': `⸬
`, '\u{2E2D}': `⸭
`, '\u{2E2E}': `⸮
`, '\u{2E2F}': `ⸯ
`, '\u{2E30}': `⸰
`, '\u{2E31}': `⸱
`, '\u{2E32}': `⸲
`, '\u{2E33}': `⸳
`, '\u{2E34}': `⸴
`, '\u{2E35}': `⸵
`, '\u{2E36}': `⸶
`, '\u{2E37}': `⸷
`, '\u{2E38}': `⸸
`, '\u{2E39}': `⸹
`, '\u{2E3A}': `⸺
`, '\u{2E3B}': `⸻
`, '\u{2E3C}': `⸼
`, '\u{2E3D}': `⸽
`, '\u{2E3E}': `⸾
`, '\u{2E3F}': `⸿
`, '\u{2E40}': `⹀
`, '\u{2E41}': `⹁
`, '\u{2E42}': `⹂
`, '\u{2E43}': `⹃
`, '\u{2E44}': `⹄
`, '\u{2E45}': `⹅
`, '\u{2E46}': `⹆
`, '\u{2E47}': `⹇
`, '\u{2E48}': `⹈
`, '\u{2E49}': `⹉
`, '\u{2E4A}': `⹊
`, '\u{2E4B}': `⹋
`, '\u{2E4C}': `⹌
`, '\u{2E4D}': `⹍
`, '\u{2E4E}': `⹎
`, '\u{2E4F}': `⹏
`, '\u{2E50}': `⹐
`, '\u{2E51}': `⹑
`, '\u{2E52}': `⹒
`, '\u{2E53}': `⹓
`, '\u{2E54}': `⹔
`, '\u{2E55}': `⹕
`, '\u{2E56}': `⹖
`, '\u{2E57}': `⹗
`, '\u{2E58}': `⹘
`, '\u{2E59}': `⹙
`, '\u{2E5A}': `⹚
`, '\u{2E5B}': `⹛
`, '\u{2E5C}': `⹜
`, '\u{2E5D}': `⹝
`, }