Usage & history
The Kurmanji (or Northern Kurdish) language is spoken by almost 16 million people. 9 million speakers are in Turkey, although overall usage is beginning to decline there.ekmr The Latin script is the primary orthography, but the Arabic script is used in Iran, Iraq, Syria, and Lebanon.ekmr
Kurmanji is widely written in the Latin script for poetry, general literature, education, and political documents.ekmr
Kurmancî
The Hawar orthography described here was devised by Celadet Bedirxan and his brother Kamuran Alî Bedirxan and launched in 1932. They aimed to create an alphabet that didn't use two letters for representing one sound. In addition to the older Latin orthography, Kurmanji has been written in the past in Arabic, Armenian, and Cyrillic orthographies.
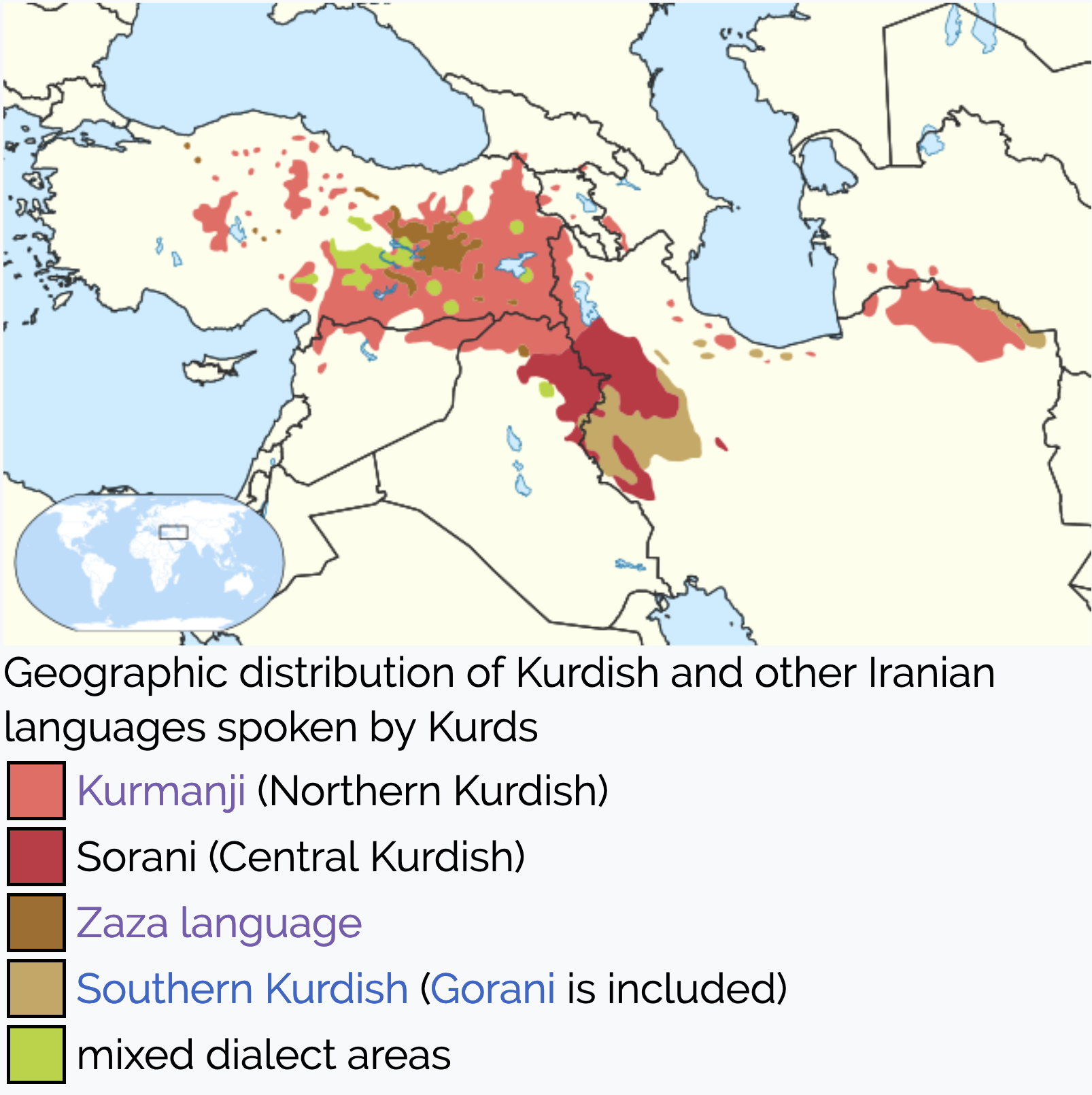
The following map of Kurdish dialects was created for Wikipedia. The Wikipedia article on Sorani contains a useful additional details about the use of Sorani since the 1700s.






{kind=link}