This page brings together basic information about the Gurmukhi script and its use for the Punjabi language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Punjabi using Unicode.
The Gurmukhi script ( ਗੁਰਮੁਖੀ ) is used in the Punjab in India, where it is the official script of the Punjabi language. The original Sikh scriptures and most of the historic Sikh literature were written in the Gurmukhi script.
Muslim speakers of Punjabi in Pakistan use a Persian version of the Arabic script (called shahmukhi).
The current form of Gurmukhi was developed in the 16th century by Guru Angad, successor to the founder of the Sikh religion, Guru Nanak. It's roots lie in the historical Brahmi script.
Unicode 17 has 1 dedicated Punjabi block, comprising 80 characters.
There are two diacritics for vowel nasalisation, tippi and bindi, each used in different phonetic contexts.
Punjabi is a tonal language. Tones are normally indicated by the use of certain consonants, rather than diacritics.
Standalone vowel sounds are written using 10 independent vowels, which can be visually analysed as vowel signs added to one of three vowel carriers. However, Unicode provides separate code points for all the combinations and deprecates the use of 2 of the carriers.
Consonants Punjabi has 32 basic consonant letters. 0A3C can be used to represent 5 more non-native sounds, particularly for words from Persian.
Vowel absenceVowel absence is typically not marked, but conjunct forms do occur for subjoined r and h, and there is one dedicated syllable-final combining mark. There are no dedicated medial consonant characters.
0A4D (called halant in Punjabi) is used to form conjuncts, but is rarely seen. It isn't used at the end of a word, and is normally only used in modern Punjabi for subjoined r, ʋ (rare), and h, in which cases it is invisible. However, the virama may also be used occasionally to suppress the vowel in Sanskritised text, or in dictionaries for extra phonetic information.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Consonant sounds
labial
dental
alveolar
post-
alveolar
retroflex
palatal
velar
glottal
stops
pb
td
ʈɖ
kɡ
aspirated
pʰ
tʰ
ʈʰ
kʰ
affricates
t͡ʃd͡ʒ
aspirated
t͡ʃʰ
fricatives
fv
sz
ʃ
xɣ
ɦ
nasals
m
n
ɳ
ɲ
ŋ
approximants
ʋ~w
l
ɭ
j
trills/flaps
ɾ
ɽ
Note that Punjabi has no voiced aspirated stops. The letters for these sounds do exist in Gurmukhi, but are redirected to indicate tone.
Structure
The following summary is from Wikipediawl.
The three retroflex consonants /ɳ, ɽ, ɭ/ do not occur initially, and the nasals /ŋ, ɲ/ occur only as allophones of /n/ in clusters with velars and palatals.
The well-established phoneme /ʃ/ may be realised allophonically as the voiceless retroflex fricative /ʂ/ in learned clusters with retroflexes.
The phonemic status of the fricatives /f, z, x, ɣ/ varies with familiarity with Hindustani norms, more so with the Gurmukhi script, with the pairs /f, pʰ/, /z, d͡ʒ/, /x, kʰ/, and /ɣ, g/ systematically distinguished in educated speech.
The retroflex lateral is most commonly analysed as an approximant as opposed to a flap.
Gurmukhi uses spaces to separate text into words. The inherent vowel is usually not pronounced at the end of a word, however there is often a ghost sound ᵊ, eg.
ਜਾਲ਼
Gurmukhi tends to use independent vowels rather than semi-vowels for sequences of vowel sounds, eg.
ਓਹਾਇਓ
Tone
Punjabi is a tonal language with three tones: high, low, and level (not transcribed). The tones cover one or two syllables.d They are transcribed as follows in Wiktionary.
IPA
Name
Accent
˥ or ˩˥
high
á
˩ or ˥˩
low
à
—
level
a
There is a lack of clarity about the fine detail of how the tonal system works.b
Sometimes these are described as contour tones: high rising, and low falling.
ⓘ represents the inherent vowel. Diacritics are added to the vowels to indicate nasalisation (not shown here).
Inherent vowel
ਕ
kə
The inherent vowel for Punjabi is pronounced ə and transcribed a, so kə is written by simply using the consonant letter.
eg.
ਦਰਖ਼ਤ
ਦ,ਰ,ਖ਼,ਤ
Since Punjabi consonants normally include an inherent vowel, the orthography has ways to indicate a consonant that is not followed by a vowel sound. See novowel.
Post-consonant vowels
Punjabi represents other vowels using 9 vowel signs, which are all combining marks. The inherent vowel is usually not pronounced at the end of a word, however there is often a ghost ᵊ.
Punjabi has 1 pre-base vowel and no circumgraphs. A single Unicode character is used per base consonant, so there are no multipart vowels.
Three of the vowel signs are spacing marks, meaning that they consume horizontal space when added to a base consonant.
All vowel signs are typed and stored after the base consonant, and the glyph rendering system takes care of the positioning at display time. Conjuncts are treated as indivisible units when it comes to rendering vowel signs, meaning that pre-base vowel sign is rendered before the conjunct as a whole (see prebase).
Punjabi uses the following dedicated combining marks for vowels.
Where a vowel sign has multiple pronunciations, click on the letter to see details.
ਿ,ੀ,ੂ,ੁ,ੇ,ੋ,ੈ,ੌ,ਾ
Vowels ɪ and ʊ tend to be pronounced differently in certain contexts. Followed by ਹ they become the high tone éː and óː, respectively.d
eg.
ਕਿਹੜਾ
ਕੁਹੜਾ
The combination of an inherent vowel followed by ਹ and then one of these 2 letters produces ɛ́ː and ɔ́ː, respectively.d
eg.
ਕਹਿਣਾ
ਵਹੁਟੀ
Two more combining marks are used for nasalisation (see nasalisation).
Nasalisation
Two separate diacritics are used to indicate either nasalisation or a nasal coda.
ੰ,ਂ
ੰ is used after consonants with an inherent vowel, and after the following vowels:
ਇੰ,ਿੰ,ੁੰ,ੂੰ,ਅੰ
ਂ is used with the other vowels (dependent and independent). Most of these vowels have glyphs that extend above the top bar, and the bindu fits more easily into the space available. (If a tippi is used for one of these vowels, the font may quietly substitute the bindu glyph.)
Observation: In the terms list, the IPA transcription for the bindu is mostly a nasalisation diacritic, whereas for the tippi it is more likely to be a homorganic nasal consonant.
eg.
ਧੂੰਆਂ
ਬਾਂਹ
ਮੂੰਡਾ
These diacritics can also signal gemination of a following m or n.
eg.
ਲੰਮੀ
The word for smoke contains both bindi and tippi.show composition
ਧੂੰਆਂ
The Unicode Standard describes ‘special cases’ where the bindi dot needs to appear to the left of the letter ੀ. To produce this effect, type and store the bindi and vowel sign in the reverse order compared to the norm.
ਕ,ੀ,ਂ,ਕੀਂ
ਕ,ਂ,ੀ,ਕਂੀ
Standalone vowels
Gurmukhi represents standalone vowels using a set of independent vowel letters. The set includes a character to represent the inherent vowel sound.
ਈ,ਊ,ਇ,ਉ,ਏ,ਓ,ਅ,ਐ,ਔ,ਆ
ਅ is typically analysed as a null consonant with an inherent vowel.
In fact, all independent vowels in Gurmukhi are graphically a combination of one of three vowel carriers and a vowel sign.
ੲ,ੳ,ਅ
Unicode has independent code points for the vowel carriers, but decomposed and precomposed standalone vowels are not regarded as canonically equivalent. This means that words containing decomposed sequences will not match those containing precomposed code points (unless the application does something special). In fact, Gurmukhi fonts will typically not render the decomposed sequences as expected.
Therefore, the Unicode Standard recommends the use of the precomposed characters, and says to not use two of the carrier symbols at all. ਅ is used on its own to represent ə, but should not be used in combinations, either.
ੲ,ੳ
Vowel components
This section describes various vowel components and behaviours associated with this orthography.
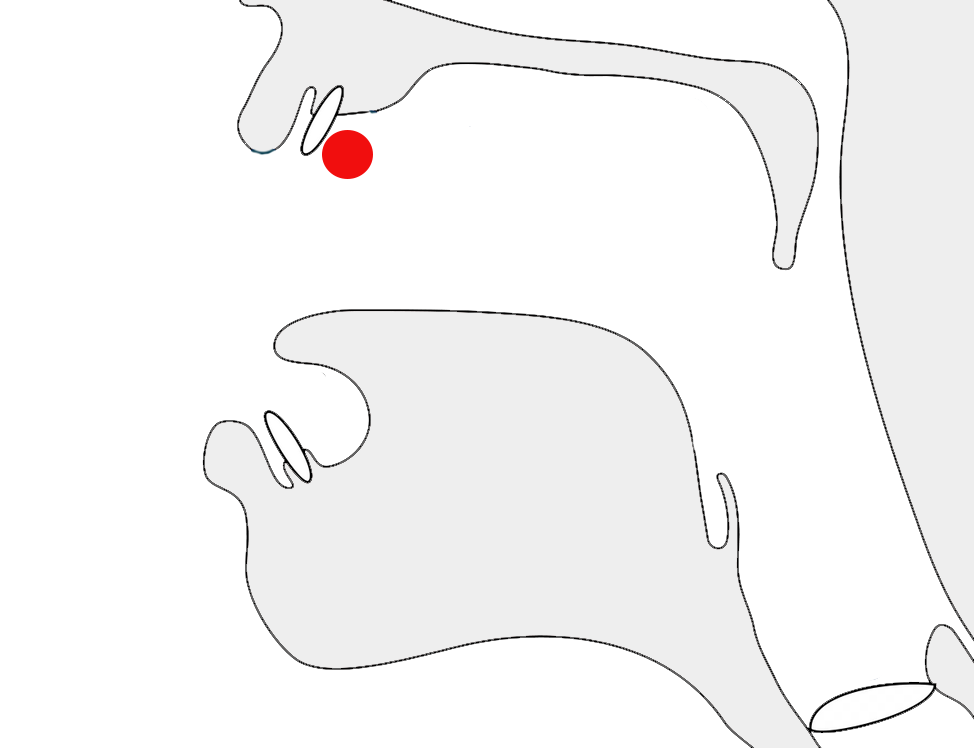
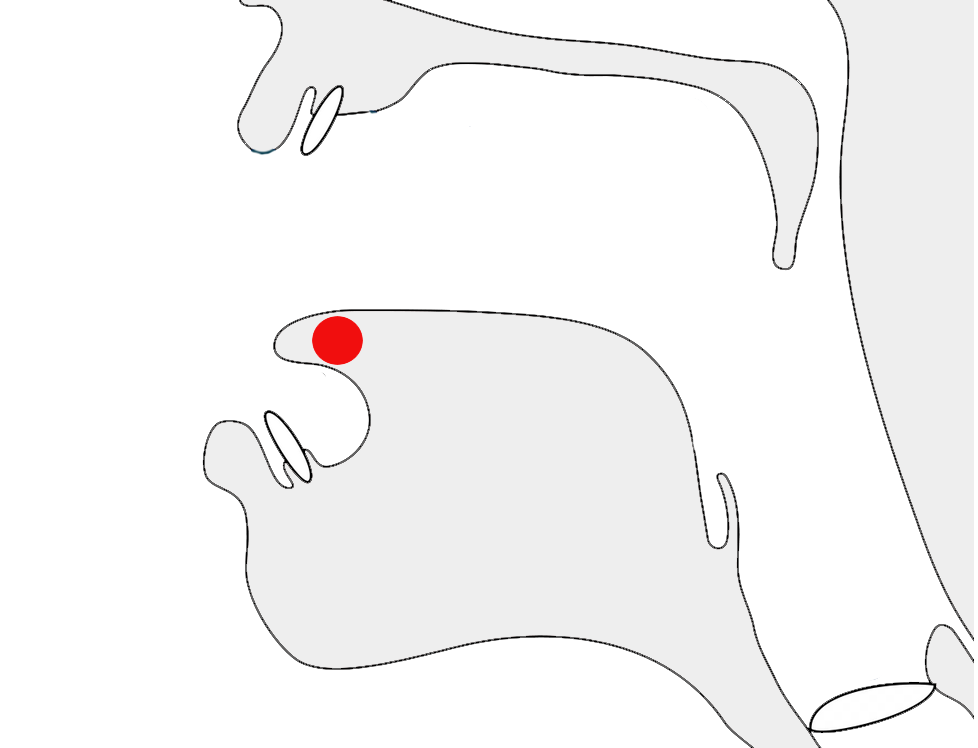
Pre-base vowel sign
ਕਿ
ké
ਿ
One vowel sign appears to the left of the base consonant letter or cluster.
eg.
ਦਿਲ
This is a combining mark that is always typed and stored after the base consonant(s), ie. the codepoints follow the order in which the items are pronounced. The rendering process places the glyph before the base consonant without changing the code points. The following shows the sequence of code points that make up the word just above.
ਦ,ਿ,ਲ
A prebase vowel, rendered to the left of the consonant after which it is pronounced.show compositionਬਹਿਣਾ
Vowel sign placement
The following list shows where vowel signs are positioned around a base consonant to produce vowels, and how many instances of that pattern there are.
1 pre-base, eg. ਕਿkɪ
2 post-base, eg. ਕੀkī
4 superscript, eg. ਕੇke
2 subscript, eg. ਕੁkʊ
At maximum, vowel components can occur concurrently on 1 side of the base.
Gurmukhi doesn't normally use tone diacritics. Instead, certain character combinations serve to indicate high and low tones. The level tone is not marked.
Tonal stop letters
Five of the consonants – those nominally representing voiced, aspirated sounds in the Brahmi model – indicate changes in tone. The articulatory pronunciation is unaspirated and, when syllable-initial, unvoiced.
ਭ,ਧ,ਝ,ਢ,ਘ
These letters indicate a low tone when they appear at the beginning of a word or syllable or medially between a short and long vowel.
eg.
ਘੋੜਾ
ਬਘਿਆੜ
They indicate a high tone when elsewhere.o
eg.
ਕੁਝ
ਬਾਘ
The letter HA
ਹ is typically pronounced h when syllable-initial.
eg.
ਹਰੀ
ਅਹਾਰ
However, in unstressed syllables in this position it is often elided and the vowel takes on a high tone.
eg.
ਕਹਿਣਾ
ਬਹੁਤ
In non-initial positions the letter serves as a tone marker, and is not pronounced, but instead indicates that that syllable has a high tone.
After an open syllable the full letter shape is used, but if the syllable has a coda, this letter appears subjoined below the coda (see stacks).
eg.
ਮੀਹ
ਚੜ੍ਹਦਾ
When the letter HA follows a short I or U, it changes the vowel's phonetic value from ɪ and ʊ to é and ó, respectively.
(The sound h after a vowel can be produced using ਃ, but it is only rarely used.)
Observation: Wiktionary contains at least one apparent exception to the above: the word ਮੂੰਹ ends with a pronounced h.
Udaat
The diacritic ੑ can also be used in older texts to indicate a high tone.
Vowel sounds to characters
This section maps Punjabi vowel sounds to common graphemes in the Gurmukhi orthography.
iː
vowel signੀ
standaloneਈ
ɪ
vowel signਿ
standaloneਇ
ʊ
vowel signੁ
standaloneਉ
uː
vowel signੂ
standaloneਊ
eː
vowel signੇ
vowel signਿਹApplies a high tone.
standaloneਏ
oː
vowel signੋ
vowel signੁਹWith a high tone.
standaloneਓ
ə
inherent voweleg. ਸ੍ਵਰਗ
standaloneਅ
ɛː
vowel signੈ
vowel signਹਿApplies a high tone.
standaloneਐ
ɔː
vowel signੌ
vowel signਹੁWith a high tone.
standaloneਔ
aː
vowel signਾ
standaloneਆ
◌̃
nasalisationੱwith the inherent vowel or i and u.
nasalisationਂwith all other vowels.
Vowel absence
Vowel absence principally occurs either when a consonant is a syllable coda, or when a consonant is part of a consonant cluster.
Given that consonants normally include an inherent vowel, the orthography needs a way to indicate when a consonant is not followed by a vowel.
Conjuncts, where the second character appears below the first in a stack.
Coda diacritics Some Punjabi codas can be written using combining marks.
Using yakash below the initial character (quite rare).
Unmarked vowel absence
Unlike most other indic scripts, there is generally no indication when a consonant is not pronounced with a following inherent vowel. (For the few occasions where this is made clear see clusters.) Generally speaking, the reader simply has to know whether an inherent vowel is pronounced or not.
eg.
ਉਤਸੁਕ
ਵਸਤੂ
The inherent vowel is generally not pronounced at the end of a word (see the previous example), however the last letter is often followed by a ᵊ ghost.
eg.
ਅੱਜ
Conjuncts
Vertical stacks
Normally Gurmukhi produces stacks to indicate a consonant cluster for only 3 combinations. In each case, the second letter in the cluster appears subjoined to the first.
The stacking behaviour is produced by adding 0A4D between the two characters to be stacked. The lower character's shape and size are significantly reduced.
eg.
ਪ,੍,ਰ,ਪ੍ਰ
The character h in non-initial position is used to indicate tones (see consonant_tones). When the h follows a consonant, it is subjoined to it.
eg.
ਚੜ੍ਹ
ਚ,ੜ,੍,ਹ
Syllable-initial clusters also occur with r and occasionally v, and are also indicated using subjoined forms.
eg.
ਪ੍ਰਬੰਧਸ੍ਵਰਗ
Subjoined v is much less common in modern text.
The virama may also be used occasionally to suppress the vowel in Sanskritised text, or in dictionaries for extra phonetic information.ws In some fonts subjoined forms are available for other consonant clusters, though they are not used unless the content author uses a virama.
Conjunct forms produced after the letter p by the Mukta Mahee font. They include the following sounds, in order of appearance: pt pd ptʰ pt͡ʃ pʈ pʈʰ pg pɦ pʋ pn pr.
Modern Gurmukhi texts don't feature half-forms like those in Devanagari, but a few pairings are attested in older texts. They include the following. In a few other cases, the half-form is sometimes the first consonant in the cluster, and other times the second. Read more in the Unicode Standard.
ਦ,੍,ਯ,ਦ੍ਯ
Consonants
ਪ,ਭ,ਬ,ਭ,ਤ,ਧ,ਦ,ਧ,ਟ,ਢ,ਡ,ਢ,ਕ,ਘ,ਗ,ਘ
ਫ,ਥ,ਠ,ਖ
ਚ,ਝ,ਜ,ਝ, ,ਛ
ਫ਼,ਵ,ਸ,ਜ਼,ਸ਼,ਖ਼,ਗ਼,ਹ,ਃ
ਮ,ਨ,ਞ,ਣ,ਙ
ਰ,ੜ,ਲ,ਲ਼,ਯ
ਹ can be used in combination with other consonants to indicate tone. Those combinations are not shown here. Hyphens indicate consonants that play a role in tone marking, depending on the position in a syllable: a hyphen after indicates a low tone when the letter is syllable-initial; hyphens either side indicate a high tone when the letter is not syllable-initial.
Basic consonants
Gurmukhi has a set of consonants that mostly map onto the traditional Brahmi phonetic matrix, though not all are used for articulatory distinctions.
The basic consonant sounds in Punjabi are written using the following letters.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
ਅ is also classified as a null consonant and is described in standalone.
Tone-related consonants
Gurmukhi uses certain characters to indicate high and low tones (marked with an asterisk in the list above). These include the letters that are nominally associated with aspirated, voiced plosives (which sounds don't exist in Punjabi) and the letter ਹ.
਼ is used to represent foreign sounds, particularly for words taken from Persian, eg. in the following example the dot changes
ਗɡ
to
ਗ਼ɣ
and
ਜs
to
ਜ਼z
ਕਾਗ਼ਜ਼
ਕ,ਾ,ਗ਼,ਜ਼
The following graphemes combine nukta with an existing consonant.
ਫ਼,ਜ਼,ਸ਼,ਖ਼,ਗ਼,ਲ਼
eg.
ਸਿਫ਼ਰ
ਸ਼ਹਿਰ
ਤਨਖ਼ਾਹ
ਕੋਲ਼
The nukta should always be typed and stored immediately after the consonant it modifies, and before any combining vowels or diacritics.
ਲ਼ is different from the other extended letters in that it represents a native Punjabi sound. This letter was only recently added to the Gurmukhī alphabet. Some sources do not consider it a separate letterws, and it may not always be written. It tends to get used in dictionaries to clarify pronunciation.
These graphemes are normally represented by decomposed sequences, and in fact that is what is produced by Unicode Normalization Form C (NFC). However, there are also a set of precomposed code points in the Unicode Gurmukhi block.
ਫ਼,ਜ਼,ਸ਼,ਖ਼,ਗ਼,ਲ਼
The Unicode Standard recommends not to use the precomposed code points for Gurmukhi, but instead to use the base + nukta sequences. See also encoding.
Onsets
Consonant clusters in syllable onsets are not particularly common in Punjabi. The more common variety involves a medial RA or a VA after the initial consonant. These are normally rendered as reduced subjoined forms below the preceding consonant (see stacks).
eg.
ਕ੍ਰੋਧ
ਸ੍ਵਰ
Yakash
Occasionally, a cluster ending with y is rendered using ੵ, though this appears to be quite rare.
eg.
ਕਲੵਚਰੈkly̆ʧrɛculture
Codas
Syllable-final consonant sounds are generally represented by ordinary consonant characters. It is not clear from the writing whether the consonant letter is a coda with no following sound, a coda with a ghost vowel after, or an onset with an inherent vowel. For example, compare:
ਕੂਕਰ
ਕੁਹੀਰ
ਸਿਫ਼ਰ
Syllable codas may be written as a conjunct with a subjoined ਹ, which is used to indicate tone (see tones).
eg.
ਹੜ੍ਹ
ਚੜ੍ਹਦਾ
Coda diacritics
Nasal codas can be written using ੰ. The sound is homorganic with the following consonant.
eg.
ਚੰਗਾ
ਚੰਦ
Apparently, a final h can also sometimes be represented by ਃ.
Consonant length
Doubling or reinforcement of a consonant sound is indicated, unusually for an Indic script, using a diacritic, ੱ. It is typed before the consonant (In this way it resembles the small tsu in Japanese), and is placed to the left of the consonant it affects (not over it).
eg.
ਅੱਜ-ਕੱਲ੍ਹ
The diacritic may appear over the right side of the preceding consonant, but if that consonant has a vowel sign or extension above the horizontal topline, it may be displayed on a short extension of the joining line.
Placement of the addak diacritic
Geminated mm and nn sounds may also be produced when a nasal coda precedes a nasal onset.d
eg.
ਲੰਮੀ
Consonant sounds to characters
This section maps Punjabi consonant sounds to common graphemes in the Gurmukhi orthography.
Sounds listed as 'infrequent' are allophones, or sounds used for foreign words, etc. Light coloured characters occur infrequently.
p
consonantਪ
consonantਭwhen syllable-initial, signals a low tone.
b
consonantਬ
consonantਭwhen NOT syllable-initial, signals a high tone.
pʰ
consonantਫ
t
consonantਤ
consonantਧwhen syllable-initial, signals a low tone.
tʰ
consonantਥ
t͡ʃ
consonantਚ
consonantਝwhen syllable-initial, signals a low tone.
t͡ʃʰ
consonantਛ
d
consonantਦ
consonantਧwhen NOT syllable-initial, signals a high tone.
d͡ʒ
consonantਜ
consonantਝwhen NOT syllable-initial, signals a high tone.
ʈ
consonantਟ
consonantਢwhen syllable-initial, signals a low tone.
ʈʰ
consonantਠ
ɖ
consonantਡ
consonantਢwhen NOT syllable-initial, signals a high tone.
k
consonantਕ
consonantਘwhen syllable-initial, signals a low tone.
kʰ
consonantਖ
ɡ
consonantਗ
consonantਘwhen NOT syllable-initial, signals a high tone.
f
consonantਫ਼
consonant with nuktaਫ਼(decomposes in NFC and doesn't recompose).
ʋ
consonantਵ
s
consonantਸ
z
consonantਜ਼
consonant with nuktaਜ਼(decomposes in NFC and doesn't recompose).
ʃ
consonantਸ਼
consonant with nuktaਸ਼(decomposes in NFC and doesn't recompose).
x
consonantਖ਼
consonant with nuktaਖ਼(decomposes in NFC and doesn't recompose).
ɣ
consonantਗ਼
consonant with nuktaਗ਼(decomposes in NFC and doesn't recompose).
-h
codaਃUsed only very occasionally, when it acts like a Sanskrit visarga.
ɦ
consonantਹ
m
consonantਮ
consonant0A71with the inherent vowel or i and u, followed by a labial consonant.
consonant0A02with other vowels before a labial consonant.
n
consonantਨ
consonant0A71with the inherent vowel or i and u, followed by an alveolar consonant.
consonant0A02with other vowels before an alveolar consonant.
ɳ
consonantਣ
ɲ
consonantਨbefore a palatal consonant.
consonant0A71with the inherent vowel or i and u, followed by a palatal consonant.
consonant0A02with other vowels before a palatal consonant.
consonantਞRare.
ŋ
consonantਨbefore a velar consonant.
consonant0A71with the inherent vowel or i and u, followed by a velar consonant.
consonant0A02with other vowels before a velar consonant.
consonantਙRare.
w
consonantਵoccasionally as a variant of ʋ.
r
consonantਰ
ɽ
consonantੜ
l
consonantਲ
ɭ
consonantਲ਼
consonant with nuktaਲ਼ (decomposes in NFC and doesn't recompose) .
j
consonantਯ
Symbols
Gurmukhi uses a couple of religious symbols.
ੴ,☬
ੴ can have various different forms. Unicode classes it as a letter. The shape in Arial MS Unicode is highly stylised, most fonts shape it as digit one followed by a sign based on ura with a long upper tail.
The stylised shape of ek onkar in Arial MS Unicode.
The other religious symbol, ☬, is encoded in Unicode's Miscellaneous Symbols block.
Although usage is recommended here, content authors may well be unaware of such recommendations. Therefore, applications should look out for the non-recommended approach and treat it the same as the recommended approach wherever possible.
Encoding independent vowels
Visually, Gurmukhi independent vowels are written using a combination of a vowel sign attached to one of three base letters. Those combinations are encoded by the Unicode Standard as single, atomic code points, but it is also possible to analyze the letter as using a decomposed sequence of code points: a base letter followed by a vowel sign.
The atomic characters don't decompose when normalised using NFD, nor do the decomposed sequences change under NFC. They are therefore not treated in Unicode as canonically equivalent. The Unicode Standard recommends that the atomic characters be used, and not the sequences.
Many fonts (such as Noto Fonts) will display a dotted circle if the content author tries to use the decomposed sequence, but not all fonts do. Content authors who created their content with a font such as Gurmukhi MN will find that their content no longer looks right when a different font is used.
Atomic (recommended)
Decomposed (do not use)
ਇ
0A72 0A3F
ਈ
0A72 0A40
ਉ
0A73 0A41
ਊ
0A73 0A42
ਏ
0A72 0A47
0A13
0A73 0A4B
ਆ
0A05 0A3E
ਐ
0A05 0A48
ਔ
0A05 0A4C
It is unlikely that content authors will always choose the approach recommended by the Unicode Standard, so applications should be able to treat atomic and decomposed independent vowels as the same, even though they are not canonically equivalent.
Encoding the nukta
The nukta is a small dot used to extend the Gurmukhi repertoire to additional sounds (see extendedC. The decomposed sequence of letter+nukta is recommended by the Unicode Standard. NFC does not recombine the parts into atomic characters. Instead, normalisation produces decomposed forms for both NFC and NFD. So both alternatives are canonically equivalent, but decomposed is recommended.
Precomposed
Decomposed (recommended)
ਫ਼
0A2B 0A3C
ਜ਼
0A1C 0A3C
ਸ਼
0A38 0A3C
ਖ਼
0A16 0A3C
ਗ਼
0A17 0A3C
ਲ਼
0A32 0A3C
Combining mark order
The following indicates the expected ordering of Unicode characters within a Punjabi combining character sequence. Follow the links to see what characters are represented by a given label.
Killed vowel. This CCS belongs to the non-final part of a consonant cluster, or to a consonant with a killed vowel. It consists of just the base, with an optional Nukta, and the Virama.
General. The alternative CCS uses the following preferred ordering after a base.
Gurmukhi has its own set of decimal digits, however modern text tends to use ASCII digits.ws
੦,੧,੨,੩,੪,੫,੬,੭,੮,੯
In some cases the choice of digits depends on the context. For example, list counter styles often use Gurmukhi digits, whereas postcodes, route numbers, and ordinal dates, etc. tend to use ASCII digits.GitHub§https://github.com/r12a/scripts/issues/118#issuecomment-1235187772
Text direction
Gurmukhi script runs left to right in horizontal lines.
Within a Gurmukhi word, spacing glyphs are joined together at the top bar (shirorekha).
eg.
ਚਿੜੀ-ਛਿੱਕਾ
The top bar extends across or through most spacing letters, including both consonants and vowels, but some letters create a gap in the line (while still joining at either side). Two such letters can be seen in the following example.
ਅਧਿਆਪਕ
Letters that create these gaps include digits and the following:
ਪ,ਘ,ਖ,ਮ,ਅ,ਃ
Alignment of the top bar may be appropriate when mixing text of different sizes (see initials). Also, when Gurmukhi text is mixed with another script that also has a top bar, such as Devanagari, the top bars of both scripts may need to be aligned.
Gurmukhi text doesn't commonly use italicisation for emphasis, but slanted text and bolding do occur in modern texts. Italicisation tends to be used to offset blocks of text, by-lines, etc., rather than for emphasis.
The following figures show slanted text being used to set off text.
Slanted text used to set off a by line.Slanted text used to set off a paragraph.
In modern texts, Gurmukhi words are separated by spaces.
Certain older texts did not contain spaces. This is called larivaar.GitHub§https://github.com/r12a/scripts/issues/118#issue-1359804026
Some grammatical suffixes are also separated from their stem by a space, and in this case the two parts should not become separated.GitHub§https://github.com/w3c/iip/issues/98
Words are occasionally hyphenated.
eg.
ਵਿਡਿਓ-ਗੇਮ
Graphemes
Although grapheme clusters alone provide good segmentation for many Gurmukhi syllables (because of the lack of conjuncts), they are not sufficient to represent typographic units for stacks. Stacks are common and must not be split apart by edit operations that visually change the text (such as letter-spacing, first-letter highlighting, and in-word line breaking). For those operations one needs to segment the text using orthographic syllables, which string grapheme clusters together with a virama.
The Gurmukhi virama (halant) is ੍, which has an Indic Syllabic Category of Virama.
Grapheme clusters
Base Combining_mark* ZW(N)J?
Grapheme clusters cover the combinations described just above. In these sequences, Gurmukhi combining marks used for Punjabi may include zero or more of the following types of character.
Nukta [1] (see extendedC) Only one per grapheme cluster, typed and stored immediately after the base consonant.
Bindi [2] (see nasalisation) Occurs over an independent vowel or over a consonant.
Gemination mark [1] (see clength) Occurs after a consonant (with optional nukta).
Other marks [3] (see yakash, finals and udaat) All are uncommon and occur after a consonant (with optional nukta).
Virama (halant) (see clusters and novowel) Occurs immediately after a consonant (and optional nukta) at the beginning of a cluster. In modern Punjabi text stacks are only formed with a subjoined RA or HA, and on rare occasions VA. Other consonant clusters are simple sequences of consonant letters.
ZW(N)J is not usually found in Gurmukhi text.
The following examples show a variety of typical grapheme clusters:
Click on the text version of these words to see more detail about the composition.
ਧੂੰਆਂ
ਖਿੱਚਣਾ
ਕਾਗ਼ਜ਼
ਭਿਖੵਾ
ਕ਼ੌਮ
ਪ੍ਰਭੂ
ਹੜ੍ਹ
Note how grapheme clusters segment the parts of a stack after the virama in the last 2 examples. This is not always desirable (see orthographicS just below).
Larger typographic units
(Consonant Nukta? Virama)* Grapheme_cluster
Gurmukhi stacks medial RA (and sometimes VA) and HA after a syllable coda (see clusters). The stacks represent consonant clusters (but not gemination, which is indicated using a diacritic).
Grapheme clusters terminate after a sequence of marks that includes a halant, but editorial operations that change the visual appearance of the text, such as letter-spacing, first-letter highlighting, line-breaking, and justification, should never split conjunct forms apart. For this reason, an alternative way of segmenting graphemes is needed. This may not apply, however, for some other operations such as cursor movement or backwards delete.
Where stacks appear, a typographic unit contains multiple grapheme clusters. The non-final grapheme clusters all end with ੍, and the final grapheme cluster begins with a consonant.
The following are examples. Some examples were shown in the previous section: here the stack is treated as a single typographic unit.
Click on the text version of these words to see more detail about the composition.
ਪ੍ਰਭੂ
ਹੜ੍ਹ
ਅੰਮ੍ਰਿਤਸਰ
ਪ੍ਰਾਂਗਾਰ
ਫ਼੍ਰੈਂਚ
Browser behaviour
Test in your browser.The words test units that equate to grapheme clusters only, and others that include conjuncts. First, the text is displayed in a contenteditable paragraph, then in a textarea. Results are reported for Gecko (Firefox), Blink (Chrome), and WebKit (Safari) on a Mac.
ਧੂੰਆਂਕਾਗ਼ਜ਼ਪ੍ਰਭੂਹੜ੍ਹਫ਼੍ਰੈਂਚ
Cursor movement.Move the cursor through the text.
Gecko steps through the text using grapheme clusters. It takes 2 steps (to get through the stacks, one grapheme cluster at a time. Blink and WebKit step through all words using the orthographic syllables as described here (ie. they step over a stack and all associated combining characters in one jump).
Selection.Place the cursor next to a character and hold down shift while pressing an arrow key.
The behaviour is the same as for cursor movement.
Deletion. Forward deletion works in the same way as cursor movement. The backspace key deletes code point by code point, for all browsers.
Line-break.See this test. The CSS sets the value of the line-break property to anywhere. Change the size of the box to slowly move the line break point.
Gecko, WebKit and Blink all wrap on orthographic syllable boundaries.
। may be used rather than a period at the end of a sentence. It is often separated from the last word in the sentence by a small gap, but should not wrap alone to the beginning of the next line. The gap also doesn't grow during justification.
Examples of danda in use as a sentence delimiter in a newspaper report.translation
The Ambassador of Mauritius to India Mrs. Mary Claire J. Monty came to visit Sri Harmandir Sahib today. He bowed down with reverence and served for some time at Guru Ramdas Ji's Langar Hall.
Bracketed text
Punjabi commonly uses ASCII parentheses to insert parenthetical information into text.
Punjabi texts typically use quotation marks. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
start
end
initial
“
”
nested
‘
’
Single quotation marks are used for quotations within quotations.
ਃ is used very occasionally in Gurmukhi. In some cases it acts like a Sanskrit visarga, producing a voiceless h sound, but in others it represents an abbreviation, in the same way the period is used in English.ws
However, contractions are very common in Punjabi text, and a much more common way of indicating these is to use 02BC (or
' U+0027 APOSTROPHE).
A particularly common contraction is to represent ਵਿੱਚ as 'ਚ. GitHub§https://github.com/r12a/scripts/issues/118#issue-1359804026
Examples of abbreviated words using apostrophes.translation
ISKCON Vice President Radharaman said that the increasing incidence of attacks on Hindu temples in Australia is alarming.
Other inline features
Other punctuation
CLDR also lists the following non-ASCII characters.
‐,–,—,
Line & paragraph layout
Line breaking & hyphenation
By default, Gurmukhi breaks lines at inter-word spaces.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for some of the characters used in modern Gurmukhi. Context may affect the behaviour of some of these and other characters.
“ ‘ ( should not be the last character on a line.
” ’ ) . , ; ! ? । % should not begin a new line.
ੴ ☬ do not create line-break opportunities unless they are separated from other letters by space.
fig_justification shows lines justified by stretching the inter-word spaces.
Justification of Punjabi text.
Note that the space before the danda at the end of a sentence is not stretched during justification.
Baselines, line height, etc.
Gurmukhi uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
It also has a 'hanging baseline', which may be used for text alignment in things such as initial letter highlighting. The hanging baseline is based on the top bar that joins the letters.
Gurmukhi requires slightly more vertical space than Latin text. To give an approximate idea, fig_baselines compares Latin and Gurmukhi glyphs from Noto fonts. The basic Gurmukhi letters are typically slightly higher than the Latin x-height, and conjunct stacks and other diacritics extend slightly below the Latin descenders. The hanging baseline is slightly higher than the Latin x-height (Noto fonts actually have a lower top bar than many others).
Font metrics for Latin text compared with Gurmukhi glyphs in the Noto Serif Gurmukhi (top) and Noto Sans Gurmukhi (bottom) fonts.
fig_baselines_other shows similar comparisons for the Baloo Paaji 2 and Raavi fonts.
Latin font metrics compared with Gurmukhi glyphs in the Baloo Paaji (top) and Raavi (bottom) fonts.
You can experiment with counter styles using the Counter styles converter. Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
The modern Punjabi orthography uses a native numeric style.
Numeric
The gurmukhi numeric style is decimal-based and uses these digits.rmcs
੧,੨,੩,੪,੫,੬,੭,੮,੯,੦
eg.
੧,੨,੩,੪,੧੧,੨੨,੩੩,੪੪,੧੧੧,੨੨੨,੩੩੩,੪੪੪
Alphabetic
The punjabi alphabetic style for the Punjabi language uses these letters.
Note that the 2 vowel carriers which are to be avoided in normal text are present here as the 1st and 3rd counters.
eg.
ੳ,ਅ,ੲ,ਸ,ਚ,ਥ,ਲ,ੳਘ,ੲਕ,ਕਛ,ਘਡ,ਛਧ
Prefixes and suffixes
The numeric style commonly uses a full stop + space as a suffix. The alphabetic style may enclose counters in parentheses, or use a single closing parenthesis.
Punjabi content sometimes enlarges the first part of the first word in a paragraph, in a similar way to drop caps. Instead of enlarging just the first letter in the word, it is normal to enlarge the first orthographic syllable (see fig_first_letter). If the first character is the beginning of a conjunct, the whole stack should be included in the styling.
Enlarged syllable styling at the start of a paragraph.
In principle, the top line of the characters should align in the large text and the following first line.
Page & book layout
References
Acknowledgements
Thanks to @bgo-eiu for extensive comments on an early version of this page, and Denis Moyogo Jacquerye for pointers on EK ONKAR.