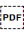 U+202C POP DIRECTIONAL FORMATTING (PDF).
U+202C POP DIRECTIONAL FORMATTING (PDF).
0 digit.
`, '\u{10D41}': `
1 digit.
`, '\u{10D42}': `
2 digit.
`, '\u{10D43}': `
3 digit.
`, '\u{10D44}': `
4 digit.
`, '\u{10D45}': `
5 digit.
`, '\u{10D46}': `
6 digit.
`, '\u{10D47}': `
7 digit.
`, '\u{10D48}': `
8 digit.
`, '\u{10D49}': `
9 digit.
`, '\u{10D4A}': `
a vowel.
Combinations
All vowels in word-initial position are preceded by 10D70 or its uppercase equivalent, 10D50. The vowels themselves are unicameral.
aː is .
ə is .
əː is .
`, '\u{10D4B}': `
i vowel.
Combinations
All vowels in word-initial position are preceded by 10D70 or its uppercase equivalent, 10D50. The vowels themselves are unicameral.
iː is
iʰ is
iːʰ is
`, '\u{10D4C}': `
ɔ vowel.
Combinations
All vowels in word-initial position are preceded by 10D70 or its uppercase equivalent, 10D50. The vowels themselves are unicameral.
ɔː is .
o is .
oː is .
u is .
uː is .
`, '\u{10D4D}': `
ɛ after one of the 4 consonants, b, d, ɡ, or ɟ whether they are prenasalised or not. This is to avoid a collision with the diacritic 10D69, which is the natural way of writing the sound ɛ, but is also the way to show prenasalisation.
It is also used to write the word-initial ɛ, .
ɛː after the same consonants, is the sequence .
Other combinations
e is normally .
However, after one of the 4 consonants mentioned earlier the combining mark combining mark is also replaced with this character, ie. 10D4D 10D4D.
Word-initial e- is a little idiosynchratic and is written using 2 of these characters: .
eː is .
ə is .
əː is .
u is .
uː is .
o is .
oː is .
iʰ is
iːʰ is
`, '\u{10D4E}': `
Creates a long vowel. Used with all Garay vowels.
`, '\u{10D4F}': `
A spacing letter that signals that no vowel appears after a consonant. According to Rovenchak, Faye, and Riley, it is now obsolete.rsr§10
`, '\u{10D50}': `
See the lowercase letter for details.
`, '\u{10D51}': `
See the lowercase letter for details.
`, '\u{10D52}': `
See the lowercase letter for details.
`, '\u{10D53}': `
See the lowercase letter for details.
`, '\u{10D54}': `
See the lowercase letter for details.
`, '\u{10D55}': `
See the lowercase letter for details.
`, '\u{10D56}': `
See the lowercase letter for details.
`, '\u{10D57}': `
See the lowercase letter for details.
`, '\u{10D58}': `
See the lowercase letter for details.
`, '\u{10D59}': `
See the lowercase letter for details.
`, '\u{10D5A}': `
See the lowercase letter for details.
`, '\u{10D5B}': `
See the lowercase letter for details.
`, '\u{10D5C}': `
See the lowercase letter for details.
`, '\u{10D5D}': `
See the lowercase letter for details.
`, '\u{10D5E}': `
See the lowercase letter for details.
`, '\u{10D5F}': `
See the lowercase letter for details.
`, '\u{10D60}': `
See the lowercase letter for details.
`, '\u{10D61}': `
See the lowercase letter for details.
`, '\u{10D62}': `
See the lowercase letter for details.
`, '\u{10D63}': `
See the lowercase letter for details.
`, '\u{10D64}': `
See the lowercase letter for details.
`, '\u{10D65}': `
See the lowercase letter for details.
`, '\u{10D69}': `
ɛ vowel.
After one of the 4 consonants, b, d, ɡ, or ɟ whether they are prenasalised or not, 10D4D is used instead. This is to avoid a collision with this diacritic, which is the natural way of writing the sound ɛ, but is also the way to show prenasalisation.
It is also used to write the word-initial ɛ, .
ɛː is
However, after the consonants that can be prenasalised, the sequence is used, instead.
Other vowel combinations
e is normally .
However, after one of the 4 consonants mentioned earlier the combining mark combining mark is also replaced with this character, ie. 10D4D 10D4D.
Word-initial e- is a little idiosynchratic and is written using . eː is .
Prenasalised stops
The following combinations indicate prenasalisation.
ᵐb is .
ⁿd is .
ᶮɟ is .
ᵑɡ is .
`, '\u{10D6A}': `
Used over a consonant to indicate that it is geminated. Consonant gemination is common and is phonemically distinctive in Wolof.
When a gemination mark is used over the same letter as 10D69, the gemination mark should be typed and stored last, whether the other diacritic represents prenasalisation or a vowelrsr§4.
Observation: This makes sense in the case of prenasalisation, since the initial combining mark is closely associated with the basic quality of the consonant letter, but it appears slightly unusual when it actually represents a following vowel. Presumably, the order was dictated by the fact that the same combining mark is used for both roles, and a single ordering is preferred.
`, '\u{10D6B}': `
Extends a consonant to represent additional sounds.
ŋ is written using the combination .
sˤ is written using the combination .
`, '\u{10D6C}': `
Extends a consonant to represent an additional sound.
z is written using the combination .
`, '\u{10D6D}': `
Observation: It's not clear how this is used. It appears in the second Garay Proposal documentrsr, but there is no information about it other than a code point assignment. It is also not clear why this is named 'consonant' nasalisation, unless it acts perhaps as a final consonant mark.
`, '\u{10D6E}': `
This hyphen appears at the end of a line when a word is broken across the line endrsr§8.
Observation: There is no description of it being used for hyphenating words otherwise.
`, '\u{10D6F}': `
Doubles a word, eg.
`, '\u{10D70}': `
ʔ carrier for standalone vowels in word-initial position. This is analogous to the Arabic alef. It is not usually given any sound in IPA transcriptions.
Note that the lowercase glyph for this letter is larger than that for 10D4D.
Combinations
This letter is also used in combination with other characters to represent non-native sounds.
ʃ is .
v is .
q is .
`, '\u{10D71}': `
c consonant.
`, '\u{10D72}': `
m consonant.
`, '\u{10D73}': `
k consonant.
`, '\u{10D74}': `
b consonant.
Prenasalisation
ᵐb is 10D74 10D69.
`, '\u{10D75}': `
ɟ consonant.
Prenasalisation
ᶮɟ is 10D75 10D69.
`, '\u{10D76}': `
s consonant.
Combinations
This letter can be combined with other characters to represent a number of sounds from other languages.
sˤ is .
z is .
ʃ is .
ʒ is .
`, '\u{10D77}': `
w consonant.
Combinations
v (foreign sound) is .
`, '\u{10D78}': `
l consonant.
`, '\u{10D79}': `
ɡ consonant.
Combinations
ᵑɡ is .
ŋ is .
`, '\u{10D7A}': `
d consonant.
Combinations
ⁿd is .
`, '\u{10D7B}': `
x consonant.
Combinations
q is .
`, '\u{10D7C}': `
j consonant.
`, '\u{10D7D}': `
t consonant.
`, '\u{10D7E}': `
r consonant.
`, '\u{10D7F}': `
ɲ consonant.
`, '\u{10D80}': `
f consonant.
`, '\u{10D81}': `
n consonant.
`, '\u{10D82}': `
p consonant.
`, '\u{10D83}': `
h consonant.
`, '\u{10D84}': `
Obsolete letter for k.
`, '\u{10D85}': `
Obsolete letter for n.
`, '\u{0021}': `!
`, '\u{0028}': `(
`, '\u{0029}': `)
`, '\u{002E}': `.
`, '\u{003A}': `:
`, '\u{003B}': `;
`, '\u{003F}': `?
`, '\u{060C}': `،
`, '\u{061B}': `؛
`, '\u{061F}': `؟
`, '\u{2018}': `‘
`, '\u{2019}': `’
`, '\u{201C}': `“
`, '\u{201D}': `”
`, '\u{2026}': `…
`, // FORMATTING CHARACTERS // zwsp '\u{200B}': `ZWSP
An invisible character, used to signal line-break and word-break opportunities. It was originally provided for use with writing systems such as Thai, Myanmar, Khmer, Japanese, etc. that don't use spaces between words.
Justification visibly adjusts the space between the characters on either side of the ZWSP as if the ZWSP wasn't there§,827, eg. the two lines below show Thai text containing a ZWSP after the 4th base character. The first is rendered as per normal, the second is as it would appear with justification or letter-spacing. Note how the second line has no extra spacing where the ZWSP occurs. อักษรไทย อั ก ษ ร ไ ท ย
`, // zwnj '\u{200C}': `ZWNJ
Prevents two adjacent letters forming a cursive connection with each other when rendered. Useful for illustrations that describe how the script works, eg. 𞤨𞤼𞤷 ← 𞤨𞤼𞤷
`, // zwj '\u{200D}': `ZWJ
Permits a letter to form a cursive connection without a visible neighbour. Useful for illustrations that describe how the script works, eg. 𞤨 𞤼 𞤷 ← 𞤨 𞤼 𞤷
`, // LRM '\u{200E}': `LRM
An invisible character with strong LTR directional properties that can be used to produce the correct ordering of text, especially where there is a risk of spillover effects while the Unicode Bidirectional Algorithm is at work.
Generally referred to as LRM.
`, // RLM '\u{200F}': `RLM
An invisible character with strong RTL directional properties that can be used to produce the correct ordering of text, especially where there is a risk of spillover effects while the Unicode Bidirectional Algorithm is at work.
Generally referred to as RLM.
`, // LRE '\u{202A}': `LRE
Sets the start point for a range of inline text when applying a base direction of left-to-right. The range is terminated by U+202C POP DIRECTIONAL FORMATTING (PDF).
You should use 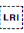 U+2066 LEFT-TO-RIGHT ISOLATE (LRI) rather than this character.
U+2066 LEFT-TO-RIGHT ISOLATE (LRI) rather than this character.
RLE
Sets the start point for a range of inline text when applying a base direction of right-to-left. The range is terminated by U+202C POP DIRECTIONAL FORMATTING (PDF).
You should use 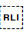 U+2067 RIGHT-TO-LEFT ISOLATE (RLI) rather than this character.
U+2067 RIGHT-TO-LEFT ISOLATE (RLI) rather than this character.
Sets the end point for a range of inline text when applying a base direction. The range is started with either 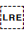 U+202A LEFT-TO-RIGHT EMBEDDING (LRE) or
U+202A LEFT-TO-RIGHT EMBEDDING (LRE) or  U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
You should use  U+2069 POP DIRECTIONAL ISOLATE (PDI) and its associated range starters rather than this character.
U+2069 POP DIRECTIONAL ISOLATE (PDI) and its associated range starters rather than this character.
LRI
Sets the start point for a range of inline text when applying a base direction of left-to-right, and isolates the text within that range from text outside it. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
This character should be used rather than U+202A LEFT-TO-RIGHT EMBEDDING (LRE).
RLI
Sets the start point for a range of inline text when applying a base direction of right-to-left, and isolates the text within that range from text outside it. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
This character should be used rather than U+202B RIGHT-TO-LEFT EMBEDDING (RLE).
FSI
Sets the start point for a range of inline text when applying a base direction, and isolates the text within that range from text outside it. The base direction set is determined by that of the first strong directional character in the range. The isolation prevents unintended spill-over effects when the text is reordered by the Unicode Bidirectional Algorithm. The range is terminated by U+2069 POP DIRECTIONAL ISOLATE (PDI).
PDI
Sets the end point for a range of inline text when applying a base direction. The range is started with either U+2066 LEFT-TO-RIGHT ISOLATE (LRI), U+2067 RIGHT-TO-LEFT ISOLATE (RLI) or  U+2068 FIRST STRONG ISOLATE (FSI).
U+2068 FIRST STRONG ISOLATE (FSI).
This character should be used rather than U+202C POP DIRECTIONAL FORMATTING (PDF).
CGJ
Used in Arabic to produce special ordering of diacritics. The name is a misnomer, as it is generally used to break the normal sequence of diacritics.
`, }