Unified Canadian Aboriginal Syllabics orthography notes
Updated
27 April, 2026
This page brings together basic information about the Unified Canadian Aboriginal Syllabics (UCAS) script and its use for the Eastern Canadian Inuktitut language, focusing particularly on usage in Nunavut and Nunavik. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Eastern Canadian Inuktitut using Unicode.
Referencing this document
Richard Ishida, UCAS (Eastern Canadian Inuktitut) Unified Canadian Aboriginal Syllabics Orthography Notes, 27-Apr-2026, https://r12a.github.io/scripts/cans/ike
Sample
Select part of this sample text to show a list of characters, with links to more details.
Change size: 28px
Unified Canadian Aboriginal Syllabics are used for a range of Algonquin and Inuit orthographies indigenous to Canada, including Cree, Ojibwe, Inuktitut, and occasionally Blackfoot languages.
Inuktitut syllabics are used in Canada by the Inuktitut-speaking Inuit of the territory of Nunavut and the Nunavik region in Quebec. The script is used by governmental agencies and in business, education, and media.
In 1976, the Language Commission of the Inuit Cultural Institute made Inuktitut syllabics the co-official script for the Inuit languages, along with the Latin script and standardised both orthographies.
The 'Inuktitut language' comprises a number of similar dialects, which have divergeant vocabulary and pronunciation. The following lists dialects in Nunavit: Inuinnaqtun, Nattilingmiutut, Qamani’tuarmiutut, Paallirmiutut, Aivilingmiutut, North Qikiqtaaluk, Central Qikiqtaaluk, South Qikiqtaaluk (includes the capital, Iqaluit), and Sanikiluarmiutut. The orthography follows the sounds spoken, which leads to different spellings for the different dialects. Some dialects use only the Latin orthography.
The Canadian syllabic script was first created in 1840 by the British missionary James Evans for writing the Swampy Cree dialect. The individual symbols may represent different phonemes for each language.
The syllabic script was first adapted to represent Inuktitut around the middle of the 1800s, again by missionaries, and early print runs occurred in the 1870s.ws§#History
The Unified Canadian Aboriginal Syllabary (UCAS) is a featural syllabary, where the majority of symbols represent both a consonant and a vowel, but vowel components are indicated by standardised rotations of the glyph shape.
The Inuit languages can be written using the syllabic script, or using a Latin transcription. The former is widely used in eastern dialects, whereas the latter is more common in the west.
Syllables A majority of symbols in the syllabary represesent a CV pairing, but the symbol is rotated to indicate whether the vowel is i, u, or a, or in some dialects ai.
A small dot above a symbol indicates a lengthened vowel, but there are precomposed code points for all combinations of base plus diacritics. These are all atomic characters. Inuktitut uses no combining marks.
The denomination Eastern Canadian Inuktitut includes a number of dialects, with differences in pronunciation. The charts here attempt to cover all the possibilities. Some dialects won't use certain sounds.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones. Source Wikipedia.
Vowel sounds
Consonant sounds
labial
dental
alveolar
post-
alveolar
palatal
velar
uvular
glottal
stop
pb
t
ɟ
k
q
ʔ
fricative
v
sɬ
ɣ
ʁ
h
nasal
m
n
ŋ
approximant
l
j
Where eastern dialects (South Qikiqtaaluk) use s.
eg.
ᑭᓴᐅᑦ
western dialects (Paallirmiutut) use h.
eg.
ᑭᓴᖅ
In some foreign words western dialects may use the sound s, such as
eg.
ᓱᑲᖅ
and eastern dialects may use h,t.
eg.
ᕼᐋᑭᕐᕕᒃ
Several dialects replace phonemes with a glottal stop, ʔ, however the original phoneme it replaces varies from dialect to dialect.m
eg.
ᑐᐱˈᒥ
Eastern dialects are more likely to collapse consonant clusters into geminated pairs. For example, compare these versions of the same word from western and eastern dialects, respectively:t
eg.
ᐅᑉᓛᖅ
ᐅᓪᓛᖅ
Speakers of North Qikiqtaaluk dialect, Nattilingmiutut, Aivilingmiutut and Pallirmiutut make the sound ɬ. (North Qikiqtaaluk)
eg.
ᐊᒃᖢᓈᖅ
but other dialects don't have it in their phonetic repertoire. (South Qikiqtaaluk)
eg.
ᐊᑦᑐᓈᖅ
and (Inuinnaqtun)
eg.
ᐊᒃᓱᓈᖅ
The b sound is only used in certain dialects, and almost always before l, eg. (Inuinnaqtun)
eg.
ᖃᑉᓗ
whereas elsewhere geminated sounds are common, eg. (South Qikiqtaaluk)
eg.
ᖃᓪᓗ
Tone
tbd
Structure
The following indicates the syllabic structure of Inuktitut syllables.m
(C)V(V)(C)
A VV sequence may consist of a long vowel.
eg.
ᐆᒪ
or a sequence of 2 different vowels.
eg.
ᑕᐃᓇ
There are usually never more than two consecutive vowels.m
Where a syllable with a closing consonant is followed by a syllable with an opening consonant, a cluster arises.
eg.
ᑐᒃᑐ
Clusters are usually only 2 consonants in length. Special final consonant signs are used at the end of a syllable, or in other words at the beginning of a cluster.m
A single consonant in the middle of a word is the opening consonant of a syllable.
eg.
ᐊᐃᕕᖅ
is composed of the syllables ai and viq.m
The sounds of consonants may change when they are part of a cluster due to phonetic rules that determine which consonant sounds can be together. This is particularly relevant when attaching morphemic suffixesm.
The left-hand column shows the basic CV shapes only; vowel length and onset labialisation are shown using letters with the same basic shape but including dots (see following sections). The middle column shows some alphabetic characters. The right-hand column shows (non-syllabic) consonant codas.
Syllable composition
The core of the script is a set of V or CV syllables, and the superscripts used for syllable-final consonants.
Each consonant can be followed by one of 4 vowel sounds (though not all combinations exist). The vowel sound for a given syllable is indicated by the rotation of the basic glyph. The illustration below is based on the p consonant.
ᐱ,ᐳ,ᐸ,ᐯ
The basic set of syllable glyphs used for Inuktitut includes the following.
ᐸ,ᑕ,ᑲ,ᒐ,ᒪ,ᓇ,ᓴ,ᓚ,ᔭ,ᕙ,ᕋ,ᖃ,ᖓ,ᖤ
There is also a set of standalone vowel glyphs, which can be seen below, and some special glyphs for consonant clusters.
Three of the vowels have both short and long forms, the latter indicated by a dot diacritic. These are all single precomposed code points. They don't decompose.
Here is the complete set of syllables beginning with the sound p.
ᐱ,ᐲ,ᐳ,ᐴ,ᐸ,ᐹ,ᐯ,ᑉ
The last symbol just above is a superscript, usually visually similar to the -a syllable, which indicates a consonant sound without a following vowel. These glyphs are used for the syllable-final consonants, which occur in (C)VC sequences.
i
u
a
ai
-
ᐃ
ᐅ
ᐊ
ᐁ
p
ᐱ
ᐳ
ᐸ
ᐯ
ᑉ
t
ᑎ
ᑐ
ᑕ
ᑌ
ᑦ
k
ᑭ
ᑯ
ᑲ
ᑫ
ᒃ
g
ᒋ
ᒍ
ᒐ
ᒉ
ᒡ
m
ᒥ
ᒧ
ᒪ
ᒣ
ᒻ
n
ᓂ
ᓄ
ᓇ
ᓀ
ᓐ
s~h
ᓯ
ᓱ
ᓴ
ᓭ
ᔅ
l
ᓕ
ᓗ
ᓚ
ᓓ
ᓪ
j
ᔨ
ᔪ
ᔭ
ᔦ
ᔾ
v
ᕕ
ᕗ
ᕙ
ᕓ
ᕝ
r
ᕆ
ᕈ
ᕋ
ᕃ
ᕐ
q
ᕿ
ᖁ
ᖃ
ᙯ
ᖅ
ŋ
ᖏ
ᖑ
ᖓ
ᙰ
ᖕ
ɫ
ᖠ
ᖢ
ᖤ
ᖦ
The core syllables for Inuktitut, arranged in matrix form.
Pronunciations of words and their suffixes can vary from dialect to dialect but, with the exception of the s~h distinction, words are generally written as they are pronounced. In the series ᓯᓱᓴ, each syllable starts with the sound s in eastern (Qikiqtaaluk) dialects, but in western dialects, the pronunciation of the same symbols begins with h.
Vowel-only syllables
ᐃ,ᐄ,ᐅ,ᐆ,ᐊ,ᐋ,ᐁ
The -ai vowels were initially dropped due to typewriter-related constraints, but have recently been reintroduced in Nunavik. For example, the following show the Nunavik and Nunavut spellings, respectively, for the same syllablei:
cf.
ᐯpᵃⁱpai
ᐸᐃpᵃipai
Consonant-vowel syllables
This section lists all the basic CV characters used for Inuktitut and, unlike the summary chart above, it includes all letters with dots, too.
These superscript characters are used to indicate syllable codas.
ᑉ,ᑦ,ᒃ,ᒡ,ᖅ,ᕝ,ᔅ,ᖦ,ᒻ,ᓐ,ᖕ,ᕐ,ᓪ,ᔾ
Repertoire extension
ᕼ,ᖯ,ʼ
ᖯ is used to represent sounds from Inuvialuktun dialects or borrowed words from other languages. It represents a b sound in bl or bj. This sound may also be written using ᑉ,i .
eg.
ᐅᑉᓛᖅ
ᕼ is used to represent a borrowed h in eastern dialects.
eg.
ᕼᐋᑭᕐᕕᒃ
In western dialects, the s- series produces this sound, so ᓵ can be used.i
Glottal stop
Several dialects have a glottal stop, ʔ, that replaces an original phoneme. Many writers simply use the original phoneme: others use the apostrophe in both Latin and syllabics,m eg. compare these versions of the word 'in a tent':
cf.
ᑐᐱᕐᒥ
ᑐᐱʼᒥ
Here we use ʼ for the apostrophe, however keyboard limitations may lead to use of the ASCII single quote, instead.
Rare characters
Mills describes an h- series of syllables that is sometimes used in Nunavit.r
ᕵ,ᕶ,ᕷ,ᕸ,ᕹ,ᕺ,ᕴ,ᕻ
Consonant clusters & geminates
Most consonants without a following vowel are written using the dedicated coda symbols (see finals), but some consonant clusters have special arrangments.
Consonant clusters only occur where one syllable ends in a consonant and the next syllable begins with one. They therefore involve the use of final consonant symbols.
eg.
ᐃᒡᓗ
Generally usage is straightforward. But there are some wrinkles.
Nng.Two ŋ consonants occuring together are typically represented using a distinct series of code points.
eg.
ᐅᒥᐊᙳᐊᖅ
ᙱ,ᙲ,ᙳ,ᙴ,ᙵ,ᙶ
Note that the Latin orthography also changes, dropping the first g from ngng to give nng.
According to Mills,r Nunavik continues to use
ᖕᖏŋŋiŋŋi
He also says that they typically use an alternate glyph shape which looks like an 8 rather than the ng-ligature.
Qq. Rather than
*...ᖅᕿ...qqiqqi
the orthography substitutes ᑭ
for ᕿ, resulting in the sequence
...ᖅᑭqkiqqi.
eg.
ᐅᑕᖅᑭᔪᖅ
The Latin orthography doesn't apply this change.
Clusters with j. In clusters that end with j the pronunciation is generally d͡ʒ, including the geminate jj.i
eg.
ᓂᔾᔭᔪᑦ
Confusables
ᖕᒋ may cause some confusion, since it looks the same as ᖏ, eg. compare
cf.
ᑭᒍᑕᖕᒋᕐᓇᖅ
ᑲᖏᖅᑐᒃ
Numbers
Inuktitut uses ASCII digits.
Text direction
The UCAS script runs left to right in horizontal lines.
Inuktitut letters don't interact, so no special shaping is needed.
There are no combining marks, and context-based positioning is not needed either.
Typographic units
Word boundaries
Words are separated by spaces, however 'words' in Inuktitut can be quite complicated and often long, eg. parimunngauniralauqsimanngittunga means I never said I wanted to go to Paris.m
Hyphens are sometimes used. fig_hyphen shows 3 hyphens used inside words or to attach numbers to words.
Since there are no combining marks or decompositions, grapheme clusters correspond to individual characters.
Grapheme clusters
Base | superscript
Each letter is a grapheme cluster, and there are no combining marks to extend them. Final consonant letters are also treated as grapheme clusters.
Click on the text version of this word to see more detail about the composition.
ᑲᖏᖅᑐᒃ
ᐅᑉᓛᖅ
ᑐᐱˈᒥ
Punctuation & inline features
Phrase & section boundaries
Inuktitut uses western punctuation.
phrase
,
;
:
sentence
.
?
!
The Unicode block contains two punctuation marks, ᐀U+1400 HYPHEN and ᙮U+166E FULL STOP, but they are not used for Inuktitut.
Observation: Use of m-dash in newspaper: ᐃᓱᒪᔪᖓᓕ ᖃᓄᐃᓕᐅᕈᑎᒃᓴᓄᑦ ᐸᕐᓇᐅᑎ ᑕᒪᑐᒪᓂ ᐊᕐᕌᒍᒥ ᐊᑐᕆᐊᖃᓕᕐᓂᖓᓂᒃ—ᐃᓚᒋᔭᐅᔪᑦ ᐅᑕᖅᑭᓯᒪᖕᒪᑕ.
Bracketed text
Inuktitut commonly uses ASCII parentheses to insert parenthetical information into text.
start
end
standard
(
)
Quotations
Inuktitut texts typically use quotation marks. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
By default, lines are broken at inter-word spaces. As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line.
In-word line-breaks
Inuktitut uses hyphenation when words are broken at the end of a line. This is quite important for Inuktitut because the words can become very long (see word).
Examples of hyphenation in a newspaper column.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for some of the characters used in modern Inuktitut. Context may affect the behaviour of some of these and other characters.
Click/tap on the characters to show what they are.
“ ‘ ( should not be the last character on a line.
” ’ ) . , ; ! ? % should not begin a new line.
Text alignment & justification
The primary opportunities for full justification lie in inter-word spaces. Because Inuktitut words tend to be very long, hyphenation is extremely useful for managing justification in narrow columns. Even so, fig_justification shows that spaces can become reasonably large in constrained spaces.
Full justification using expansion of inter-word spaces and hyphenation in a newspaper column.
Baselines, line height, etc.
Inuktitut uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
Inuktitut has no combining characters, and no ascenders or descenders, but the long vowel dot does sit slightly higher than the normal top line of the font.
To give an approximate idea, fig_baselines compares Latin and Inuktitut glyphs from the Noto Sans Canadian Aboriginal font. The basic height of Inuktitut letters is usually that of the Latin cap-height, however the long vowel dot appears above the Latin ascender line, creating a need for slightly larger line spacing.
Font metrics for Latin text compared with Inuktitut glyphs in the Noto Sans Canadian Aboriginal font.
fig_baselines_other shows similar comparisons for the Euphemia UCAS and Gadugi fonts.
Latin font metrics compared with Inuktitut glyphs in the Euphemia UCAS (top) and Gadugi (bottom) fonts.
Styling initials
Inuktitut can highlight initial letters in a paragraph. fig_initials shows how this can lead to a final consonant standing alone at the beginning of the continuation text; it is not part of the highlighted initial.
A highlighted initial in a paragraph of newsprint.











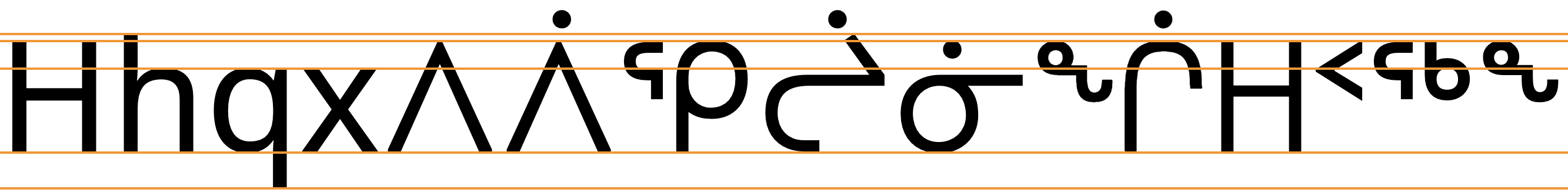
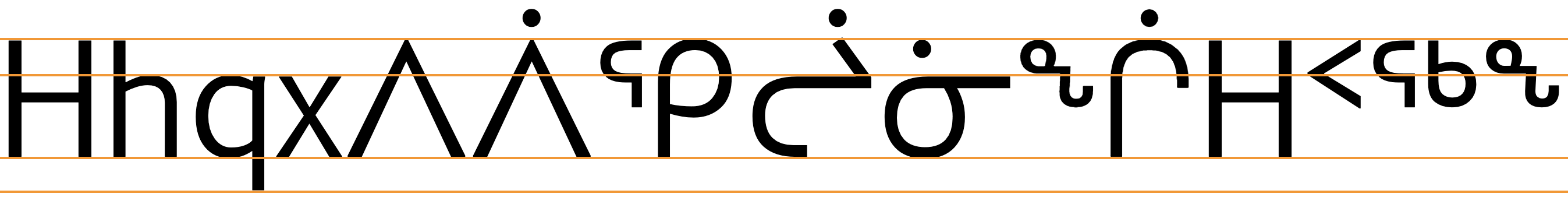

![[ᐃ]ᕐᑲᓗᖕᓄᑦ](images/initials.jpg)