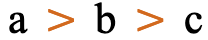This page brings together basic information about the Arabic script and its use for the Uighur language. It aims to provide a brief, descriptive summary of the modern, printed orthography and typographic features, and to advise how to write Uighur using Unicode.
The Perso-Arabic orthography described here is one of several alphabets used to write the Uighur language, but has been the official alphabet of the Uyghur language, used primarily by Uighur living in China, since 1982.
Wikipedia provides the following account of the development of the orthography.
The first Perso-Arabic derived alphabet for Uyghur was developed in the 10th century, when Islam was introduced there. The version used for writing the Chagatai language. It became the regional literary language, now known as the Chagatay alphabet. It was used nearly exclusively up to the early 1920s. Alternative Uyghur scripts then began emerging and collectively largely displaced Chagatai; Kona Yëziq, meaning "old script", now distinguishes it and UEY from the alternatives that are not derived from Arabic. Between 1937 and 1954 the Perso-Arabic alphabet used to write Uyghur was modified by removing redundant letters and adding markings for vowels. A Cyrillic alphabet was adopted in the 1950s and a Latin alphabet in 1958. The modern Uyghur Perso-Arabic alphabet was made official in 1978 and reinstituted by the Chinese government in 1983, with modifications for representing Uyghur vowels.
The Arabic alphabet used before the modifications (Kona Yëziq) did not represent Uyghur vowels and according to Robert Barkley Shaw, spelling was irregular and long vowel letters were frequently written for short vowels since most Turki speakers were unsure of the difference between long and short vowels. The pre-modification alphabet used Arabic diacritics (zabar, zer, and pesh) to mark short vowels. ...
The reformed modern Uyghur Arabic alphabet eliminated letters whose sounds were found only in Arabic and spelt Arabic and Persian loanwords, including Islamic religious words, as they were pronounced in Uyghur, not as they were originally spelt in Arabic or Persian.
The Arabic script is normally an abjad, ie. in normal use the script represents only consonant and long vowel sounds. This approach is helped by the strong emphasis on consonant patterns in Semitic languages. However Uighur is not a Semitic language, and the modern version of the Arabic script used for Uighur is an alphabet. See the table to the right for a brief overview of the features of the modern Uighur orthography.
Uighur text is written horizontally, right-to-left, but numbers and embedded Latin text are read left-to-right.
Words are separated by spaces, and contain a mixture of consonants and vowels.
The script is unicameral. Words are separated by spaces, but word-internal line breaks are allowed (unlike for the Arabic orthography when used for the Arabic language).
The script is cursive, and some basic letter shapes change significantly, depending on their joining context.
Uighur has 25 consonant letters, including a character that serves as a vowel base.
Arabic sukun is not used to indicate consonant clusters or lack of a vowel. Similarly, geminated consonant sounds are written by doubling the letter, rather than using the Arabic shadda.
The Uighur orthography is an alphabet where vowels are written using 8 vowel letters, in a straightforward way. Except in decomposed text, there are no combining marks. Unlike Arabic, all the diacritics are ijam, and in normal text are part of an atomic character.
Punctuation marks use code points from the ASCII and Arabic Unicode ranges.
Joining forms
Because the Arabic script is 'cursive' (ie. joined-up) writing, letters tend to have different shapes depending on whether they join with adjacent letters or not (see cursive). In addition, vowels can be represented using different characters, depending on where in a word they appear.
In scripts such as Arabic, several characters have no left-joining form. In what follows we'll use the characters ي and د to illustrate shapes. The former can join on both sides, but the latter can only join on the right.
Left-joining glyphs are commonly called initial; dual-joining are called medial; and right-joining are called final. Glyphs that don't join on either side are called isolated. However, these glyph shapes can be found in various places within a single word.
Word-initial characters usually have initial glyph shapes (eg. 064A ). However, characters that only join to the right will use an isolated glyph shape (eg. 062F ).
Furthermore, words beginning with a vowel are always preceded by a vowel carrier, which is normally ا
(eg. 0627 06CC or 0627 064E ).
Word-medial characters will typically join on both sides
(eg. 064A ) but those that only join to the right will use a final glyph (eg. 062F ).
However, if either of those is preceded by another character that only joins to the right, the glyph shapes rendered will be initial (eg. 064A )
and isolated (eg. 062F ), respectively.
Word-final characters will typically use a final glyph shape (eg. 064A and 062F ).
However, if the previous character joins only to the right, they will use isolated glyph shapes (eg.064A and 062F ).
In all this contextual glyph shaping the basic shapes used for a character can vary significantly in a script like Arabic. This also includes some characters that only have ijam dots in certain contexts.
Character index
Letters
Show
Consonants
پ␣ب␣ت␣د␣ك␣گ␣ق␣چ␣ج␣ف␣س␣ز␣ژ␣ش␣خ␣غ␣ھ␣ر␣ل␣م␣ن␣ڭ␣ۋ␣ي␣ئ
Vowels
ى␣ۈ␣ۇ␣ې␣و␣ە␣ۆ␣ا
Combining marks
Showٔ
Punctuation
Show،␣؛␣؟␣«␣»
ASCII
!␣.␣:␣(␣)
Other
Show
Formatting
␣␣␣␣␣␣␣␣␣␣␣␣͏
To be investigated
-␣[␣]␣ʼ␣٪␣␣‑␣–␣—␣‘␣’␣“␣”␣…␣‹␣›␣␣
Items to show in lists
Phonology
These are sounds of the modern Uighur language.
Click on the sounds to reveal locations in this document where they are mentioned.
Phones in a lighter colour are non-native or allophones.
Vowel sounds
Natively and phonemically, Uighur has only short vowel sounds, although historical assimilation and loan words have led to some longer sounds phoneticallywup.
Uighur has no diphthongs, although hiatus may occur in some loanwordswup.
Uighur vowels participate in vowel harmony and vowel reduction. For more information see Uighur Phonology.
Consonant sounds
labial
dental
alveolar
post-
alveolar
palatal
velar
uvular
glottal
stop
pb
td
kɡ
q
ʔ
affricate
t͡ʃd͡ʒ
fricative
fv
sz
ʃʒ
χʁ
ɦ
nasal
m
n
ŋ
approximant
w
l
j
trill/flap
r
Stops and affricates weaken (lenition) before dissimilar consonants, and r, l and j may be assimilated to the preceding vowel, which becomes lengthened, but none of this is reflected in the orthographywul.
Tone
Uighur is not a tonal language.
Structure
The general syllabic structure of Uighurwup is
CV(C)(C)
Uighur syllables are primarily CV or CVC. Consonant clusters in the syllable coda are often phonetically altered by elision or epenthesiswup.
Any consonant can begin a syllable except for ŋ. Any consonant can appear in the coda except for ʔwup.
Vowels
Vowel summary table
This table summarises basic vowel to character assignments.
The glyphs shown in the table are illustrative; alternative shapes may occur (see joining_forms).
Because Uighur uses atomic characters for its vowels, Uighur text usually contains no vowel-dedicated combining marks. The only exception occurs in decomposed text, where 0654 will become a combining mark.
Vowel length
Uighur doesn't natively have long vowel sounds, and none are marked in the written orthography.wup
Standalone vowels
When a vowel is alone, initial, or follows another vowel inside a word, it is always preceded by 0626, which in theory represents the glottal stop, but which is not pronounced as such at the start of a word – rather, it is just a support for the vowel.
ئى␣ئۈ␣ئۇ␣ئې␣ئو␣ئە␣ئۆ␣ئا
Vowel sounds to characters
This section maps Uighur vowel sounds to common graphemes in the Arabic orthography.
The items here indicate typical word-initial, word-medial, and word-final usage. The joining forms shown are illustrative; alternative shapes may occur (see joining_forms).
i ɨ
initial0626 0649eg. ئىرادە
medial0649eg. ئالتىنچى
final0649eg. ئالتىنچى
y ʏ
initial0626 06C8eg. ئۈزۈك
medial06C8eg. سۈلھ
final06C8eg. كۆزگۈ
u ʊ
initial0626 06C7eg. ئۇلۇغ
medial06C7eg. بۇرۇن
final06C7eg. جاڭيۇ
e
initial0626 06D0eg. ئېغىز
medial06D0eg. بېنزىن
final06D0eg. داشۈئې
ø
initial0626 06C6eg. ئۆلمەك
medial06C6eg. تۆت
final06C6
o
initial0626 0648eg. ئوتۇن
medial0648eg. پروفېسسور
final0648eg. جۇڭگو
ɛ
initial0626 06D5eg. ئەتىۋار
medial06D5eg. ئاپەت
final06D5eg. ئالتە
ɔ
initial0626 0648
medial0648
final0648
æ
initial0626 06D5eg. ئەپسۇس
medial06D5eg. خوتەن
final06D5
ɑ a
initial0626 0627eg. ئالاقە
medial0627eg. بانان
final0627eg. بانا
Consonants
Consonant summary table
This table summarises basic consonant to character assignments.
Basic consonant sounds for the Uighur language are written using the following letters.
Click on each letter for more details and for examples of usage, especially where more than one sound is indicated.
پ␣ب␣ت␣د␣ك␣گ␣چ␣ف␣س␣ز␣ژ␣ش␣خ␣غ␣م␣ن␣ۋ␣ر␣ل␣ي
Transcription note
In transcriptions using the Uyghur Latin alphabet (ULY) system, occasionally there can be ambiguities around the digraphs. In such cases, an apostrophe is used, eg. the transcription bashlan’ghuch for the following disambiguates n-gh from ng-h.
باشلئانگۇچ
Consonant clusters & gemination
Consonant clusters have no special annotation or shaping. The Arabic sukkun is not used to indicate missing vowels.
Geminated consonants are written by simply repeating the consonant twice, there is no use of the Arabic shadda, eg.
تاللاشئاپتاپپەرەسئۇسسۇل
Consonant sounds to characters
This section maps Uighur consonant sounds to common graphemes in the Arabic orthography.
The right-hand side of each item shows the various joining forms for that character.
p
067E067E067E067Econsonantپ
b
0628062806280628consonantب
t
062A062A062A062Aconsonantت
t͡ʃ
0686068606860686consonantچ
d
062F062Fconsonantد
d͡ʒ
062C062C062C062Cconsonantج
k
0643064306430643consonantك
ɡ
06AF06AF06AF06AFconsonantگ
q
0642064206420642consonantق
f
0641064106410641consonantف
v
06CB06CBsemivowelۋ
w
06CB06CBsemivowelۋ
s
0633063306330633consonantس
z
06320632consonantز
ʃ
0634063406340634consonantش
ʒ
06980698consonantژ
χ
062E062E062E062Econsonantخ
ʁ
063A063A063A063Aconsonantغ
h
06BE06BE06BE06BEconsonantھ
m
0645064506450645consonantم
n
0646064606460646consonantن
ŋ
06AD06AD06AD06ADconsonantڭ
w
ۋ ـۋvowelۋ
r
06310631consonantر
l
0644064406440644consonantل
j
064A064A064A064Asemivowelي
Encoding choices
Several of the vowel signs could be written by adding a combining mark to a base character (see the table), but in practice precomposed characters are used, and the only letter that decomposes during NFD normalisation is ئ.
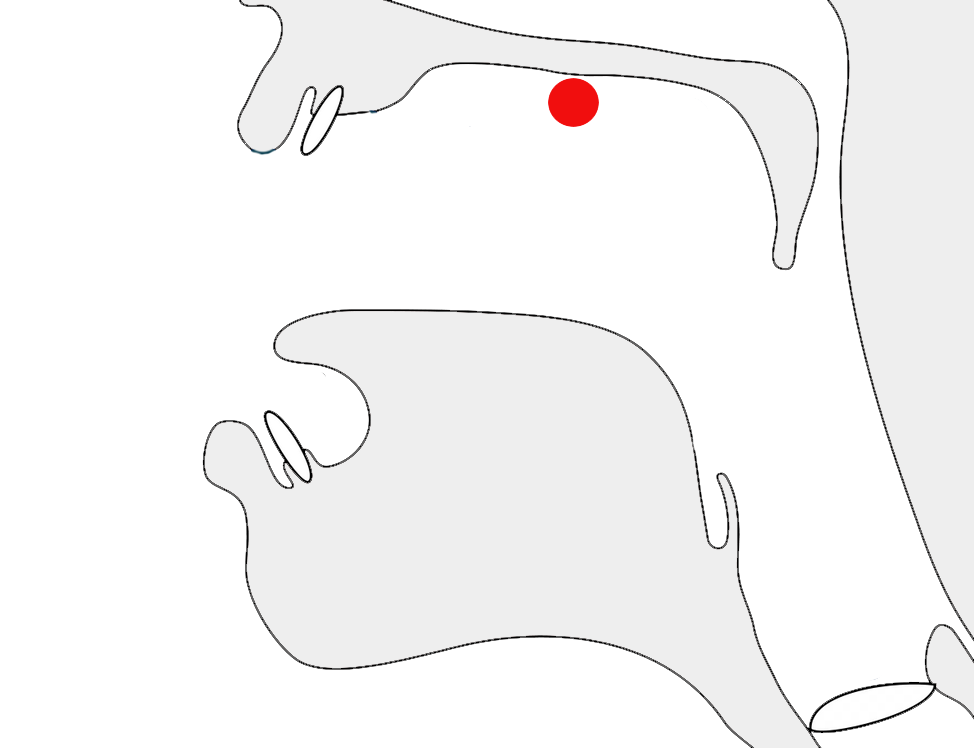
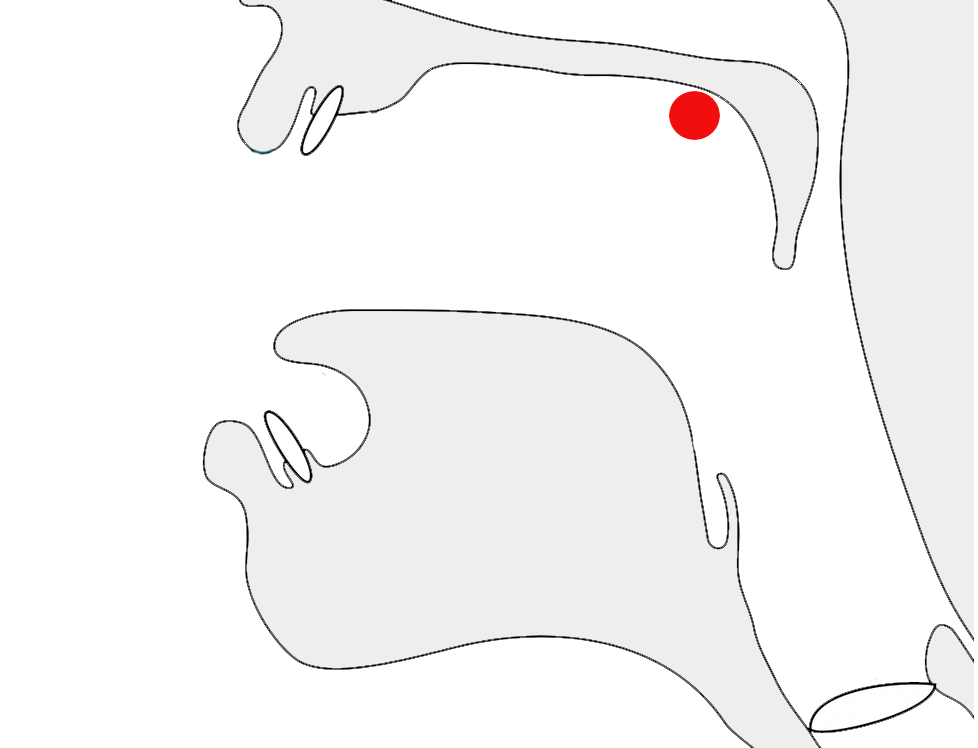
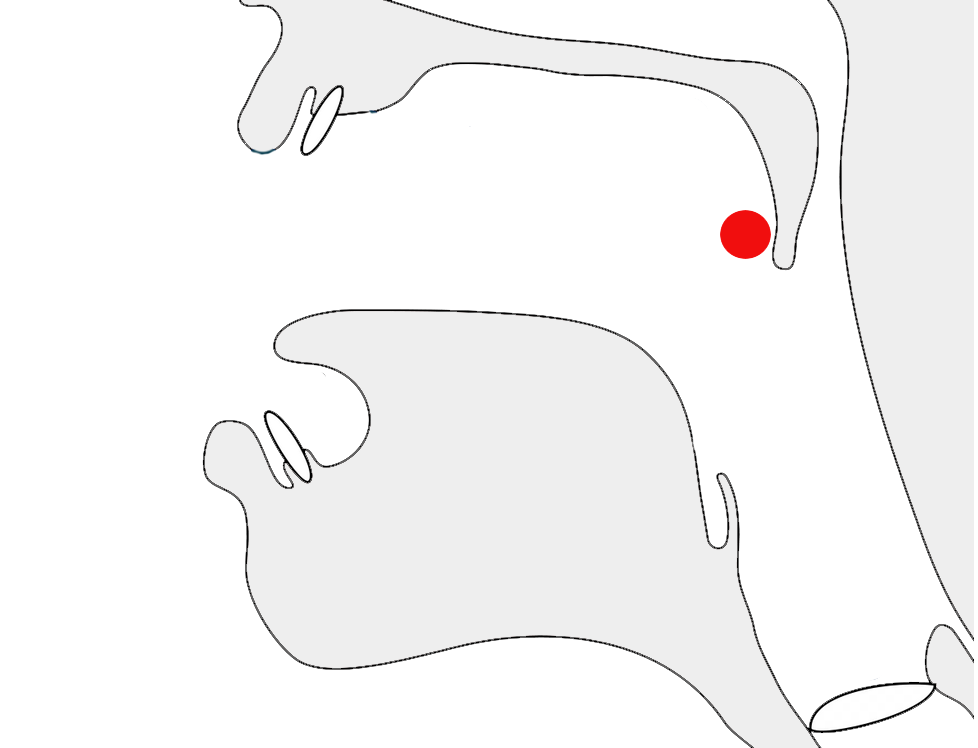
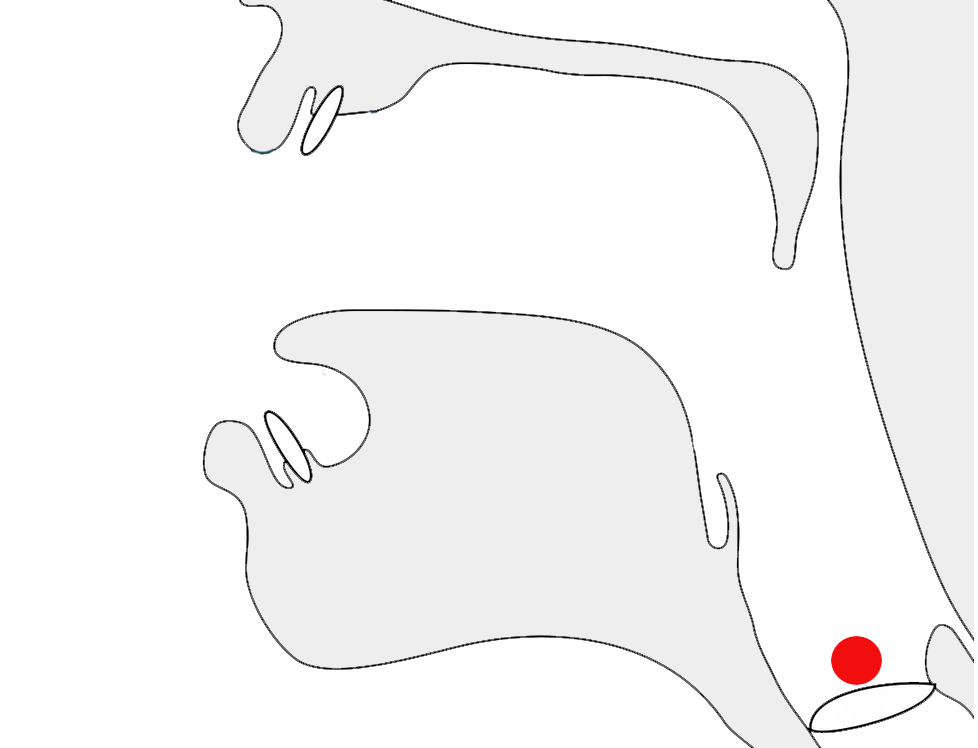
Observation:fig_date_connector shows day-month format using a tatweel-like connector, however the text doesn't connect to the horizontal line.
Day-month date forms using a low horizontal connector.
Text direction
Arabic script text is written horizontally and right-to-left in the main, but as with most RTL scripts, numbers and embedded LTR script text are written left-to-right (producing 'bidirectional' text).
Uighur words are read RTL, starting on the right, but numbers and Latin text (highlighted here) are read left-to-right.
The Unicode Bidirectional Algorithm automatically takes care of the ordering for all the text in fig_bidi, as long as the 'base direction' (ie. the surrounding directional context) is set to right-to-left (RTL).
Characters are all stored in the order in which they are spoken (and typed). This so-called 'logical' order is then rendered as bidirectional flows by the application at run time, as the text is displayed or printed. The relative placement of characters within a single directional flow is based on strong directional properties (RTL or LTR) assigned to each Unicode character by the Unicode Standard. There exist, however a set of neutral direction property values, mostly for punctuation, where the placement of characters depends on the base direction.
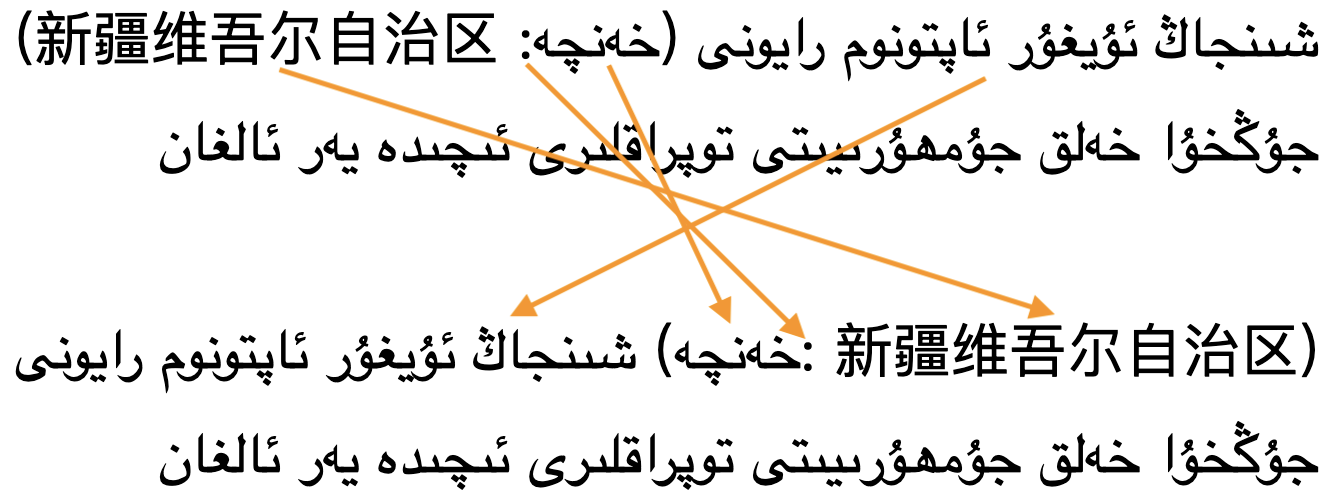
If the base direction is not set appropriately, the directional runs will be ordered incorrectly as shown in fig_bidi_no_base_direction, making it very difficult to get the meaning.
The exact same sequence of characters with the base direction set to RTL (top), and with no base direction set on this LTR page (bottom). The arrows show how items are relocated.
In some circumstances the Unicode Bidirectional Algorithm requires additional assistance to correctly render the directionality of bidirectional text. For such cases the Unicode Standard provides invisible formatting characters for use in plain text. See directioncontrols.
In HTML the base direction and higher level controls can be set using the dir or bdi attributes. CSS should not be used to control direction. Unicode formatting codes should also not be used where markup is available.
For authoring HTML pages, one of the most important things to remember is to use <html dir="rtl" … > at the top of a right-to-left page, and then use the dir attribute or bdi tag for ranges within the page, but only when you need to change the base direction. Also, use markup to manage direction, and do not use CSS styling.
For other aspects of dealing with right-to-left writing systems see the following sections:
Unicode provides a set of 10 formatting characters that can be used to control the direction of text when displayed. These characters have no visual form in the rendered text, however text editing applications may have a way to show their location.
202B (RLE), 202A (LRE), and 202C (PDF) are in widespread use to set the base direction of a range of characters. RLE/LRE comes at the start, and PDF at the end of a range of characters for which the base direction is to be set.
In Unicode 6.1, the Unicode Standard added a set of characters which do the same thing but also isolate the content from surrounding characters, in order to avoid spillover effects. They are 2067 (RLI), 2066 (LRI), and 2066 (PDI). The Unicode Standard recommends that these be used instead.
There is also 2068 (FSI), used initially to set the base direction according to the first recognised strongly-directional character.
061C (ALM) is used to produce correct sequencing of numeric data. Click on the character name, and see also expressions for details.
200F (RLM) and 200E (LRM) are invisible characters with strong directional properties that are also sometimes used to produce the correct ordering of text.
Uighur principally uses word boundaries for line-breaking and basic justification, but uses grapheme boundaries for other operations that work at the sub-word level.
Phrase, sentence, and section delimiters are described in phrase.
Grapheme clusters
Base (Combining_mark)*
In Uighur, segmentation can be realised using Unicode grapheme clusters. A typographic unit is almost always equivalent to a letter, since precomposed code points are available for all letter and diacritic combinations. Only one letter, ئ, decomposes; in that case, the typographic unit includes both the base letter and the combining mark.
Examples:
ئاچقۇچ
ئۆيمۇئۆي
This kind of typographic unit can be used for forwards deletion, cursor movement & selection, character counts, text spacing, and text insertion.
The words 'left' and 'right' in the Unicode names for parentheses, brackets, and other paired characters should be ignored. LEFT should be read as if it said START, and RIGHT as END. The direction in which the glyphs point will be automatically determined according to the base direction of the text.
Both of these lines use >U+003E GREATER-THAN SIGN, but the direction it faces depends on the base direction at the point of display.
The number of characters that are mirrored in this way is around 550, most of which are mathematical symbols. Some are single characters, rather than pairs. The following are some of the more common ones.
The following quotation marks can be found in Uighur texts. (Depending on ease of input, quotations may alternatively be surrounded by ASCII double and single quote marks.)
The glyphs before the hyphen and at the start of the next line are joined forms.
The hyphen sits on the baseline and looks like a tatweel. A very small gap appears between the hyphen and the last letter of the word at the end of the line.
Observation: The actual 'hyphen' looks like ـ [U+0640 ARABIC TATWEEL]. That would produce the expected joining form at the end of the line, although some additional mechanism would be needed to produce the form at the start of the next line. However, scans of various documents show a very small gap between the horizontal line and the last joining form at the end of the line, as can be seen in fig_hyphenation, which would negate the joining produced by a tatweel.
Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for characters affected by these rules. Context may affect the behaviour of some of these and other characters.
« “ ‘ ( should not be the last character on a line
» ” ’ ) . ، ؛ ؟ ! should not begin a new line
Breaking between Latin words
When a line break occurs in the middle of an embedded left-to-right sequence, the items in that sequence need to be rearranged visually so that it isn't necessary to read lines from bottom to top.
latin-line-breaks shows how two Latin words are apparently reordered in the flow of text to accommodate this rule. Of course, the rearragement is only that of the visual glyphs: nothing affects the order of the characters in memory.
In this Arabic language text, the lower of these two images shows the result of decreasing the line width, so that text wraps between a sequence of Latin words.
Baseline lengthening is used to justify lines of text.
fig_kashida shows that baseline lengthening and hyphenation can both be used, and sometimes within the same word.
Kashida baseline lengthening and hyphenation used in the same word (2nd line down).
Baselines, line height, etc.
Uighur uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
Font baselines should match the alphabetic baseline of Latin script text, and Arabic Uighur fonts should have relative sizes that match. However, Uighur also needs to look right alongside Chinese text, which has a slightly lower baseline and generally larger characters than Latin.
Uighur places vowel and tone glyphs above and below base characters. Several glyphs (especially in independent or final forms) also have long descenders or ascenders.
To give an approximate idea, fig_baselines compares Latin and Uighur glyphs from Noto fonts. The basic part of most Uighur letters is generally less than Latin x-height, however extenders and combining marks reach up to and sometimes beyond the Latin ascenders and descenders. That said, Noto fonts are relatively conservative in terms of glyph heights.
Font metrics for Latin text compared with Uighur glyphs in the Noto Naskh Arabic (top) and Noto Sans Arabic (bottom) fonts.
fig_baselines_other shows similar comparisons for the Scheherazade New and Microsoft Uighur fonts.
Latin font metrics compared with Uighur glyphs in the Scheherazade New (top) and Microsoft Uighur (bottom) fonts.