Sample (Hebrew)
כאשר העולם רוצה לדבר, הוא מדבר ב־Unicode. הירשמו כעת לכנס Unicode הבינלאומי העשירי, שייערך בין התאריכים 12־10 במרץ 1997, בְּמָיְינְץ שבגרמניה. בכנס ישתתפו מומחים מכל ענפי התעשייה בנושא האינטרנט העולמי וה־Unicode, בהתאמה לשוק הבינלאומי והמקומי, ביישום Unicode במערכות הפעלה וביישומים, בגופנים, בפריסת טקסט ובמחשוב רב־לשוני.
| Script name | Hebrew |
|---|---|
| Script type | abjad |
| Number of characters | 87 |
| Case distinction | no |
| Combining characters | 51 |
| Multiple combining characters | no |
| Context-based positioning | no |
| Contextual shaping | no |
| Cursive script | no |
| Many more glyphs than characters? | no |
| Text direction | rtl |
| Baseline | mid |
| Space is word separator | yes |
| Wraps at | word |
| Justification | spaces |
| Native digits? | no |
Click on the orange text in the features list (right column) to see examples and notes. Click on highlighted text in the Sample section to see the characters. Click on the vertical blue bar, bottom right, to change font settings.
Combining characters
Diacritics for vowel sounds are typically not used. The example highlighted above shows how they could be used to clarify the pronunciation of the name of the German town Mainz.

Contextual shaping
In Hebrew several characters have a different shape at the end of a word, but each shape variant has it's own codepoint and keyboard key, so there is no need for rendering rules to choose the correct glyph.
This example shows U+05DE HEBREW LETTER MEM and U+05DD HEBREW LETTER FINAL MEM (on the left).

Click on the highlighted text in the Sample section to see the characters that make up this example.
Text direction
Hebrew script is written right-to-left in the main, but as with all RTL scripts, numbers and embedded LTR script text are written left-to-right (bidirectional text). In the following example, the Hebrew words (red) are read right-to-left, starting with the one on the right, and the numeric expression (black) is read left-to-right, ie. it starts with 10 and ends with 12. (Note that this is unlike Arabic, where the 10 and 12 would be in opposite positions.)
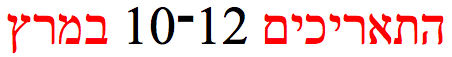
Click on the highlighted text in the Sample section to see the characters that make up this example, and note the order in memory.
Character list
The Hebrew script characters in Unicode 7.0 are contained in a single block:
The following is an incomplete list of languages and the number of characters they use, per version 26 of CLDR's lists of characters (exemplarCharacters).
- Hebrew: main 27, auxiliary 20, punctuation 20